 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit and Explicit Attention for Zero-Shot Learning
Oct 02, 2021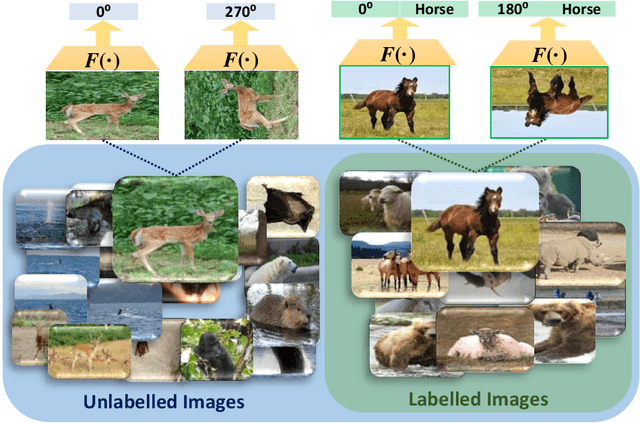

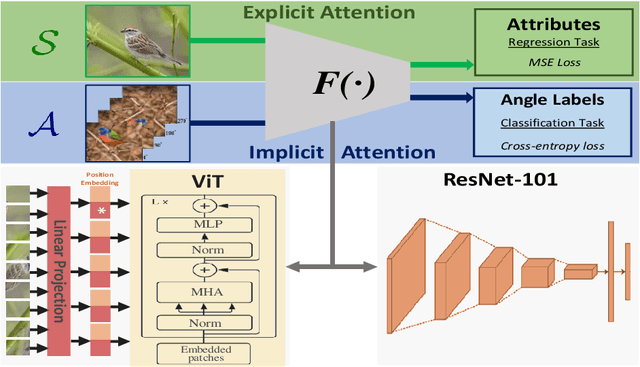
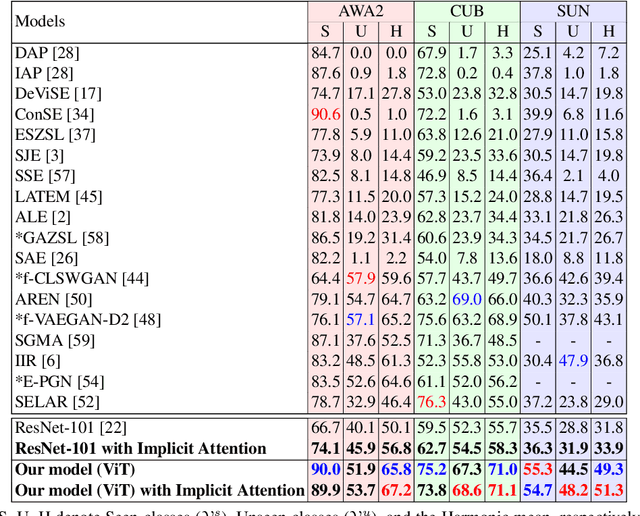
Most of the existing Zero-Shot Learning (ZSL) methods focus on learning a compatibility function between the image representation and class attributes. Few others concentrate on learning image representation combining local and global features. However, the existing approaches still fail to address the bias issue towards the seen classes. In this paper, we propose implicit and explicit attention mechanisms to address the existing bias problem in ZSL models. We formulate the implicit attention mechanism with a self-supervised image angle rotation task, which focuses on specific image features aiding to solve the task. The explicit attention mechanism is composed with the consideration of a multi-headed self-attention mechanism via Vision Transformer model, which learns to map image features to semantic space during the training stage. We conduct comprehensive experiments on three popular benchmarks: AWA2, CUB and SUN. The performance of our proposed attention mechanisms has proved its effectiveness, and has achieved the state-of-the-art harmonic mean on all the three datasets.
Multi-Head Self-Attention via Vision Transformer for Zero-Shot Learning
Jul 30, 2021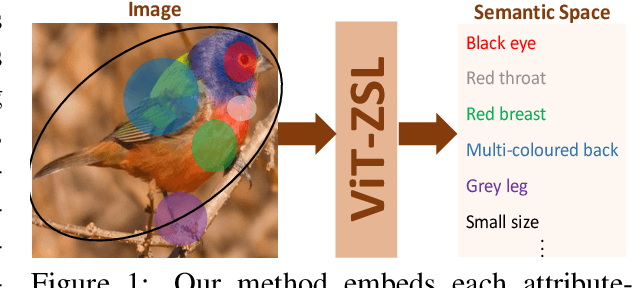


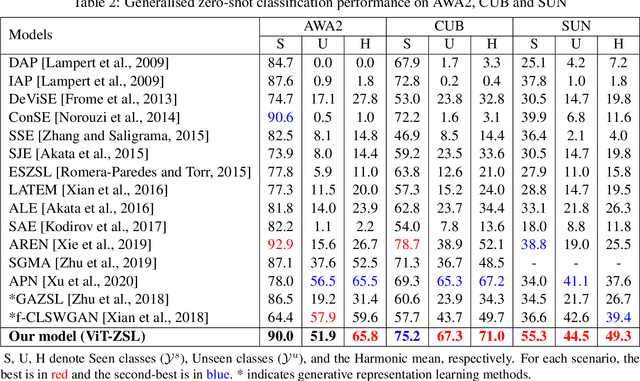
Zero-Shot Learning (ZSL) aims to recognise unseen object classes, which are not observed during the training phase. The existing body of works on ZSL mostly relies on pretrained visual features and lacks the explicit attribute localisation mechanism on images. In this work, we propose an attention-based model in the problem settings of ZSL to learn attributes useful for unseen class recognition. Our method uses an attention mechanism adapted from Vision Transformer to capture and learn discriminative attributes by splitting images into small patches. We conduct experiments on three popular ZSL benchmarks (i.e., AWA2, CUB and SUN) and set new state-of-the-art harmonic mean results {on all the three datasets}, which illustrate the effectiveness of our proposed method.
Transformer-Encoder Detector Module: Using Context to Improve Robustness to Adversarial Attacks on Object Detection
Nov 13, 2020
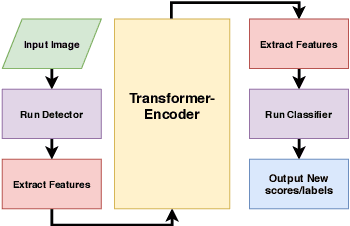


Deep neural network approaches have demonstrated high performance in object recognition (CNN) and detection (Faster-RCNN) tasks, but experiments have shown that such architectures are vulnerable to adversarial attacks (FFF, UAP): low amplitude perturbations, barely perceptible by the human eye, can lead to a drastic reduction in labeling performance. This article proposes a new context module, called \textit{Transformer-Encoder Detector Module}, that can be applied to an object detector to (i) improve the labeling of object instances; and (ii) improve the detector's robustness to adversarial attacks. The proposed model achieves higher mAP, F1 scores and AUC average score of up to 13\% compared to the baseline Faster-RCNN detector, and an mAP score 8 points higher on images subjected to FFF or UAP attacks due to the inclusion of both contextual and visual features extracted from scene and encoded into the model. The result demonstrates that a simple ad-hoc context module can improve the reliability of object detectors significantly.
Contextual Relabelling of Detected Objects
Jun 06, 2019
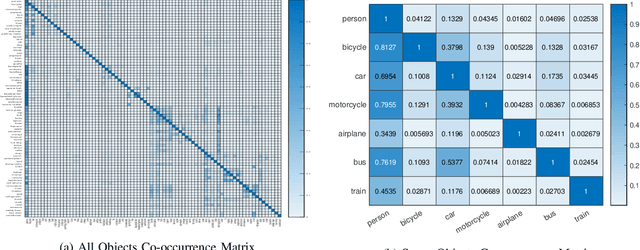

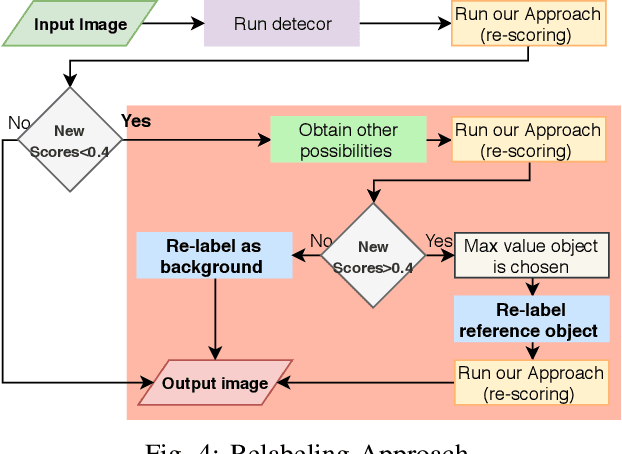
Contextual information, such as the co-occurrence of objects and the spatial and relative size among objects provides deep and complex information about scenes. It also can play an important role in improving object detection. In this work, we present two contextual models (rescoring and re-labeling models) that leverage contextual information (16 contextual relationships are applied in this paper) to enhance the state-of-the-art RCNN-based object detection (Faster RCNN). We experimentally demonstrate that our models lead to enhancement in detection performance using the most common dataset used in this field (MSCOCO).