 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit and Explicit Attention for Zero-Shot Learning
Paper and Code
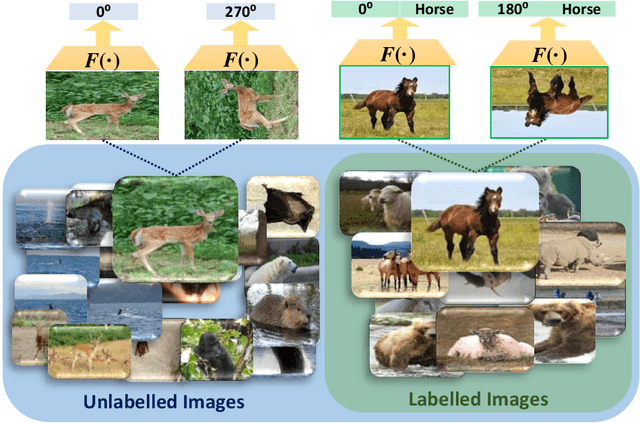

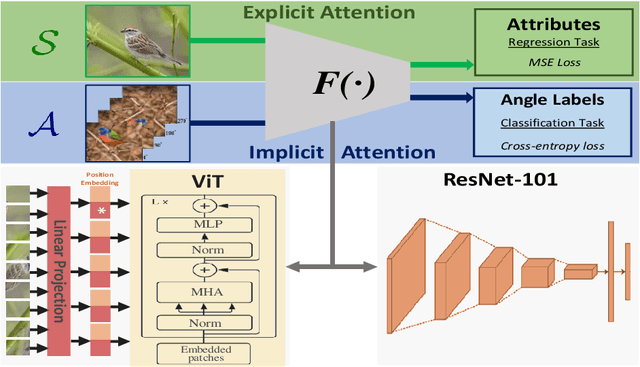
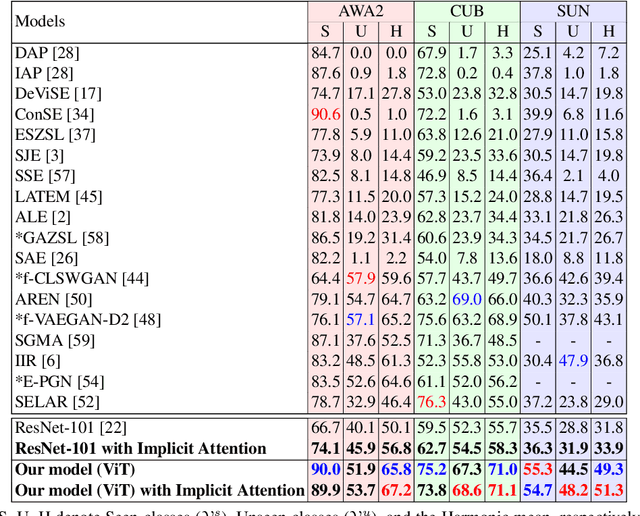
Most of the existing Zero-Shot Learning (ZSL) methods focus on learning a compatibility function between the image representation and class attributes. Few others concentrate on learning image representation combining local and global features. However, the existing approaches still fail to address the bias issue towards the seen classes. In this paper, we propose implicit and explicit attention mechanisms to address the existing bias problem in ZSL models. We formulate the implicit attention mechanism with a self-supervised image angle rotation task, which focuses on specific image features aiding to solve the task. The explicit attention mechanism is composed with the consideration of a multi-headed self-attention mechanism via Vision Transformer model, which learns to map image features to semantic space during the training stage. We conduct comprehensive experiments on three popular benchmarks: AWA2, CUB and SUN. The performance of our proposed attention mechanisms has proved its effectiveness, and has achieved the state-of-the-art harmonic mean on all the three datasets.