 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Encoder Detector Module: Using Context to Improve Robustness to Adversarial Attacks on Object Detection
Paper and Code
Nov 13, 2020
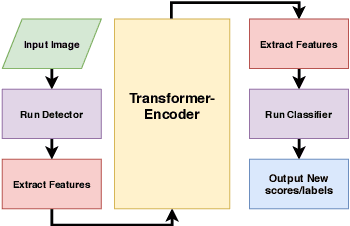


Deep neural network approaches have demonstrated high performance in object recognition (CNN) and detection (Faster-RCNN) tasks, but experiments have shown that such architectures are vulnerable to adversarial attacks (FFF, UAP): low amplitude perturbations, barely perceptible by the human eye, can lead to a drastic reduction in labeling performance. This article proposes a new context module, called \textit{Transformer-Encoder Detector Module}, that can be applied to an object detector to (i) improve the labeling of object instances; and (ii) improve the detector's robustness to adversarial attacks. The proposed model achieves higher mAP, F1 scores and AUC average score of up to 13\% compared to the baseline Faster-RCNN detector, and an mAP score 8 points higher on images subjected to FFF or UAP attacks due to the inclusion of both contextual and visual features extracted from scene and encoded into the model. The result demonstrates that a simple ad-hoc context module can improve the reliability of object detectors significantly.