 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2E Segmentation in a Two-Pass Cascaded Encoder ASR Model
Nov 28, 2022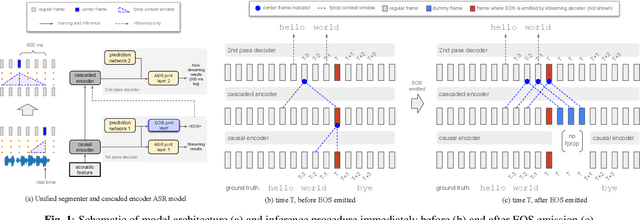
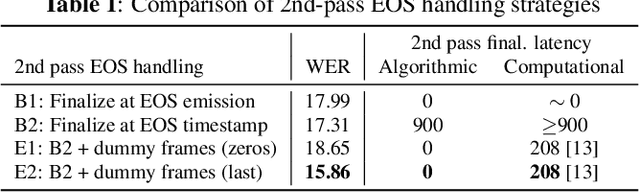
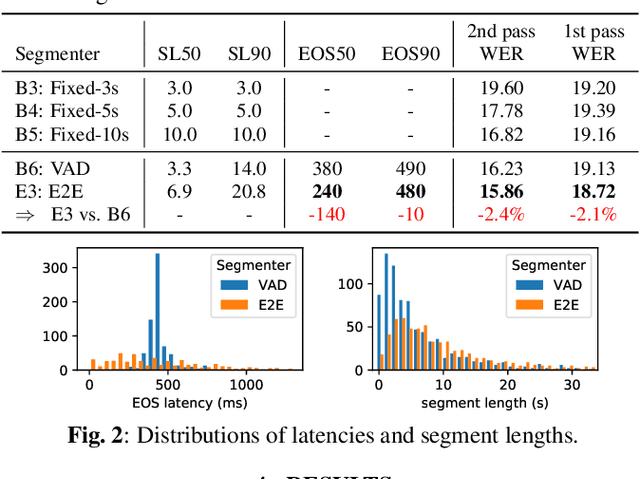

We explore unifying a neural segmenter with two-pass cascaded encoder ASR into a single model. A key challenge is allowing the segmenter (which runs in real-time, synchronously with the decoder) to finalize the 2nd pass (which runs 900 ms behind real-time) without introducing user-perceived latency or deletion errors during inference. We propose a design where the neural segmenter is integrated with the causal 1st pass decoder to emit a end-of-segment (EOS) signal in real-time. The EOS signal is then used to finalize the non-causal 2nd pass. We experiment with different ways to finalize the 2nd pass, and find that a novel dummy frame injection strategy allows for simultaneous high quality 2nd pass results and low finalization latency. On a real-world long-form captioning task (YouTube), we achieve 2.4% relative WER and 140 ms EOS latency gains over a baseline VAD-based segmenter with the same cascaded encoder.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 20, 2022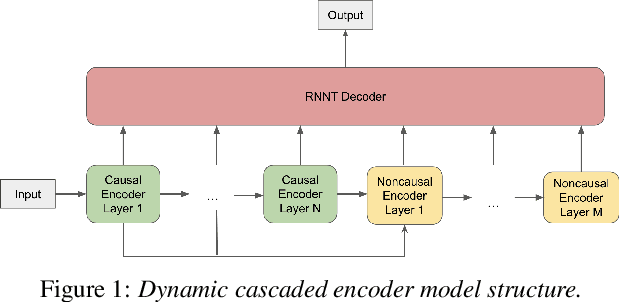
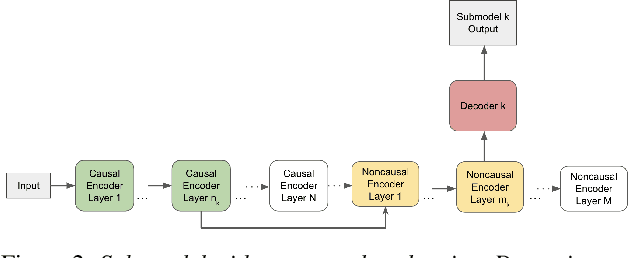
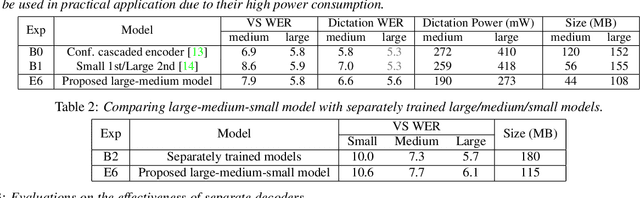
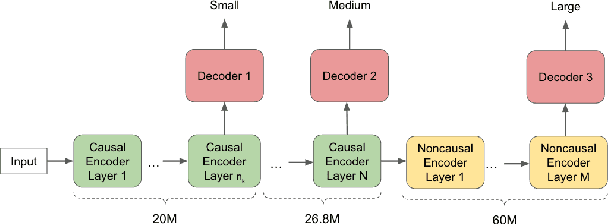
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.
Tied & Reduced RNN-T Decoder
Sep 15, 2021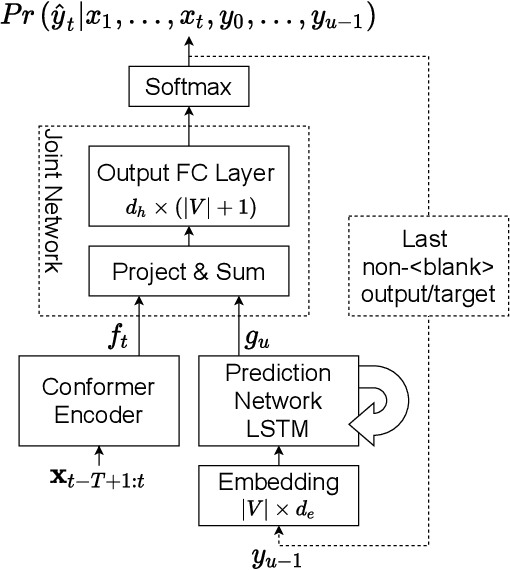
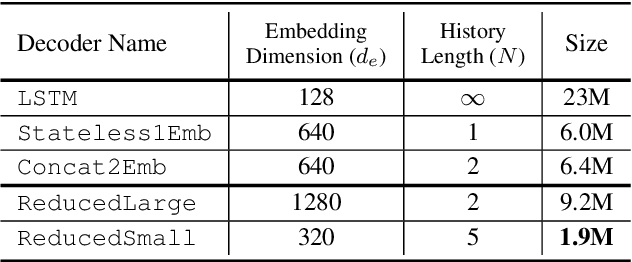
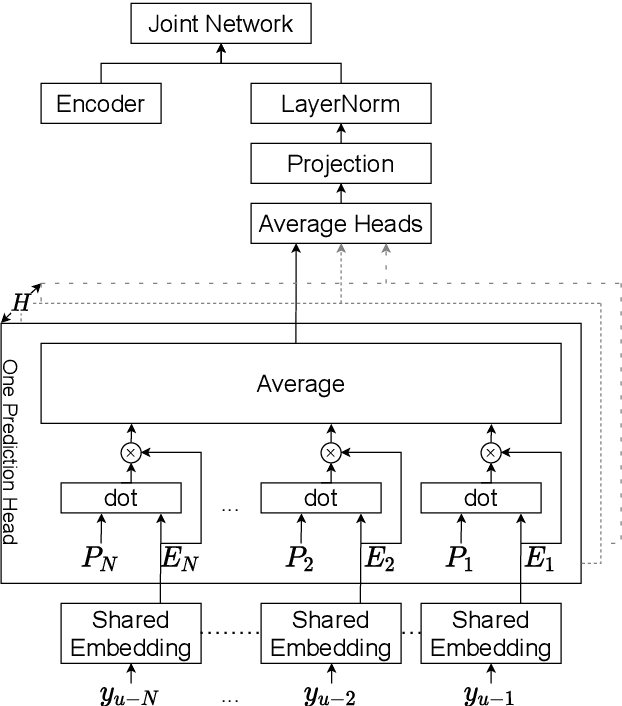
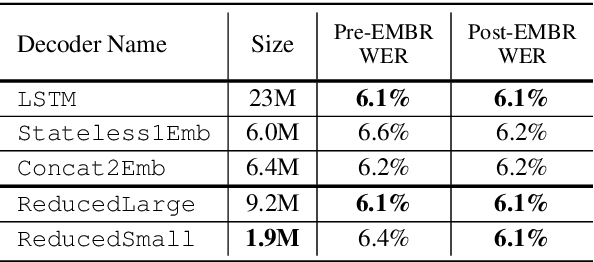
Previous works on the Recurrent Neural Network-Transducer (RNN-T) models have shown that, under some conditions, it is possible to simplify its prediction network with little or no loss in recognition accuracy (arXiv:2003.07705 [eess.AS], [2], arXiv:2012.06749 [cs.CL]). This is done by limiting the context size of previous labels and/or using a simpler architecture for its layers instead of LSTMs. The benefits of such changes include reduction in model size, faster inference and power savings, which are all useful for on-device applications. In this work, we study ways to make the RNN-T decoder (prediction network + joint network) smaller and faster without degradation in recognition performance. Our prediction network performs a simple weighted averaging of the input embeddings, and shares its embedding matrix weights with the joint network's output layer (a.k.a. weight tying, commonly used in language modeling arXiv:1611.01462 [cs.LG]). This simple design, when used in conjunction with additional Edit-based Minimum Bayes Risk (EMBR) training, reduces the RNN-T Decoder from 23M parameters to just 2M, without affecting word-error rate (WER).
TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems
Oct 20, 2020

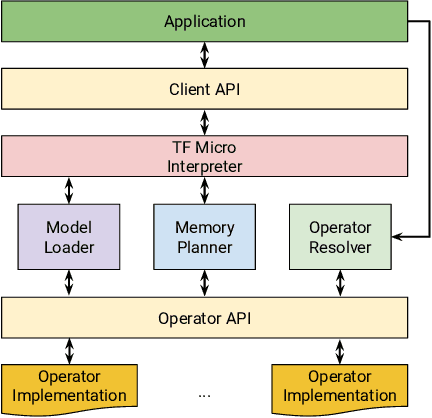

Deep learning inference on embedded devices is a burgeoning field with myriad applications because tiny embedded devices are omnipresent. But we must overcome major challenges before we can benefit from this opportunity. Embedded processors are severely resource constrained. Their nearest mobile counterparts exhibit at least a 100---1,000x difference in compute capability, memory availability, and power consumption. As a result, the machine-learning (ML) models and associated ML inference framework must not only execute efficiently but also operate in a few kilobytes of memory. Also, the embedded devices' ecosystem is heavily fragmented. To maximize efficiency, system vendors often omit many features that commonly appear in mainstream systems, including dynamic memory allocation and virtual memory, that allow for cross-platform interoperability. The hardware comes in many flavors (e.g., instruction-set architecture and FPU support, or lack thereof). We introduce TensorFlow Lite Micro (TF Micro), an open-source ML inference framework for running deep-learning models on embedded systems. TF Micro tackles the efficiency requirements imposed by embedded-system resource constraints and the fragmentation challenges that make cross-platform interoperability nearly impossible. The framework adopts a unique interpreter-based approach that provides flexibility while overcoming these challenges. This paper explains the design decisions behind TF Micro and describes its implementation details. Also, we present an evaluation to demonstrate its low resource requirement and minimal run-time performance overhead.