 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTied & Reduced RNN-T Decoder
Paper and Code
Sep 15, 2021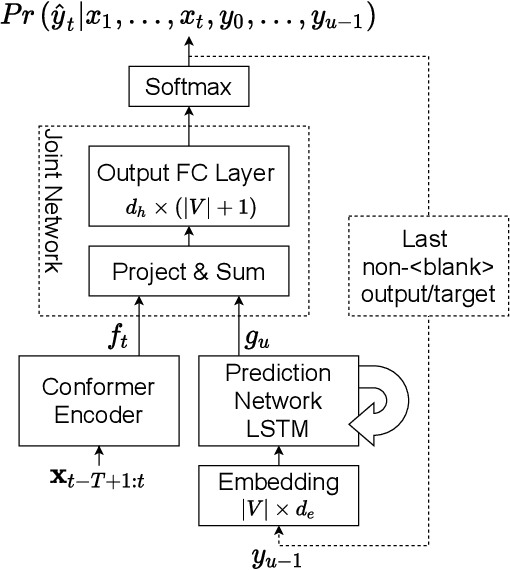
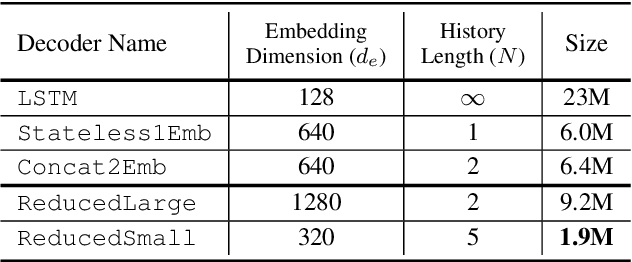
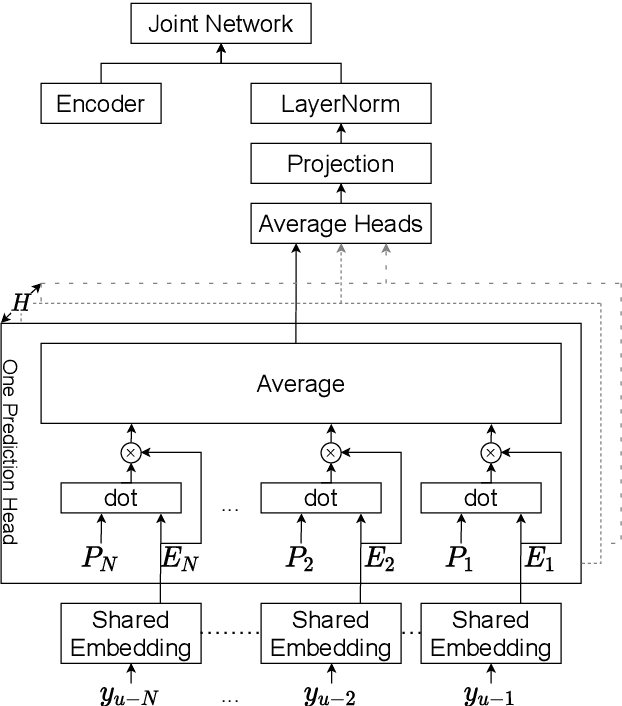
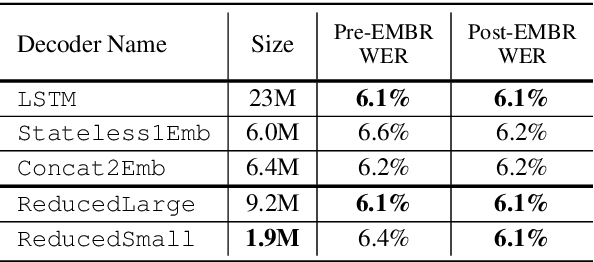
Previous works on the Recurrent Neural Network-Transducer (RNN-T) models have shown that, under some conditions, it is possible to simplify its prediction network with little or no loss in recognition accuracy (arXiv:2003.07705 [eess.AS], [2], arXiv:2012.06749 [cs.CL]). This is done by limiting the context size of previous labels and/or using a simpler architecture for its layers instead of LSTMs. The benefits of such changes include reduction in model size, faster inference and power savings, which are all useful for on-device applications. In this work, we study ways to make the RNN-T decoder (prediction network + joint network) smaller and faster without degradation in recognition performance. Our prediction network performs a simple weighted averaging of the input embeddings, and shares its embedding matrix weights with the joint network's output layer (a.k.a. weight tying, commonly used in language modeling arXiv:1611.01462 [cs.LG]). This simple design, when used in conjunction with additional Edit-based Minimum Bayes Risk (EMBR) training, reduces the RNN-T Decoder from 23M parameters to just 2M, without affecting word-error rate (WER).