 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePractical Conformer: Optimizing size, speed and flops of Conformer for on-Device and cloud ASR
Paper and Code
Mar 31, 2023

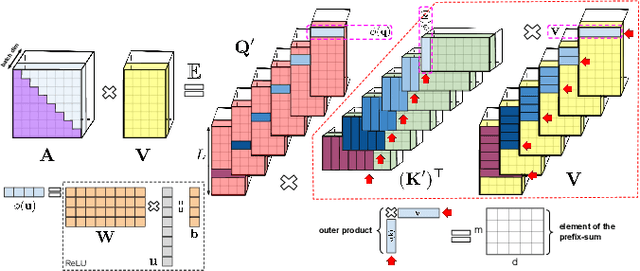

Conformer models maintain a large number of internal states, the vast majority of which are associated with self-attention layers. With limited memory bandwidth, reading these from memory at each inference step can slow down inference. In this paper, we design an optimized conformer that is small enough to meet on-device restrictions and has fast inference on TPUs. We explore various ideas to improve the execution speed, including replacing lower conformer blocks with convolution-only blocks, strategically downsizing the architecture, and utilizing an RNNAttention-Performer. Our optimized conformer can be readily incorporated into a cascaded-encoder setting, allowing a second-pass decoder to operate on its output and improve the accuracy whenever more resources are available. Altogether, we find that these optimizations can reduce latency by a factor of 6.8x, and come at a reasonable trade-off in quality. With the cascaded second-pass, we show that the recognition accuracy is completely recoverable. Thus, our proposed encoder can double as a strong standalone encoder in on device, and as the first part of a high-performance ASR pipeline.