 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Deep Clustering as Preprocessing for Automatic Speech Recognition of Sparsely Overlapping Speech
Paper and Code
May 09, 2019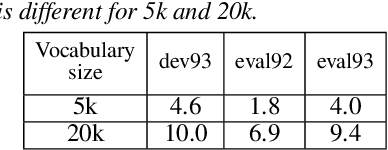
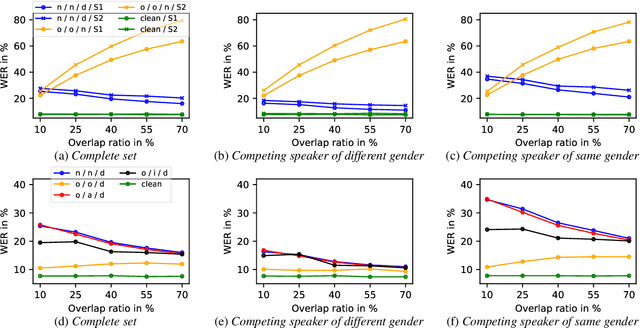
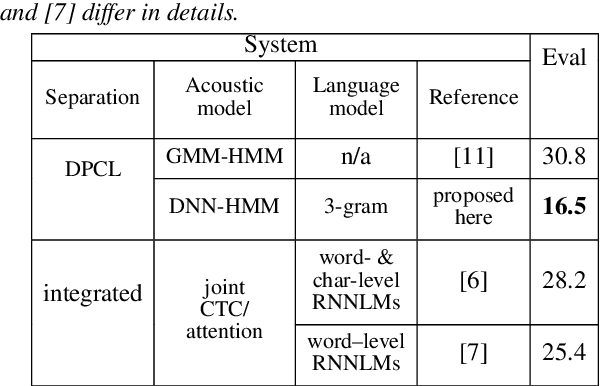
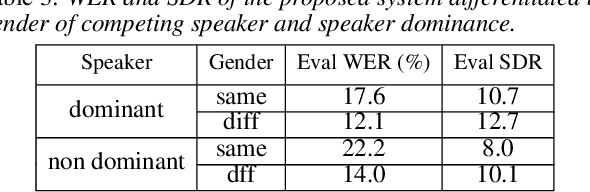
Significant performance degradation of automatic speech recognition (ASR) systems is observed when the audio signal contains cross-talk. One of the recently proposed approaches to solve the problem of multi-speaker ASR is the deep clustering (DPCL) approach. Combining DPCL with a state-of-the-art hybrid acoustic model, we obtain a word error rate (WER) of 16.5 % on the commonly used wsj0-2mix dataset, which is the best performance reported thus far to the best of our knowledge. The wsj0-2mix dataset contains simulated cross-talk where the speech of multiple speakers overlaps for almost the entire utterance. In a more realistic ASR scenario the audio signal contains significant portions of single-speaker speech and only part of the signal contains speech of multiple competing speakers. This paper investigates obstacles of applying DPCL as a preprocessing method for ASR in such a scenario of sparsely overlapping speech. To this end we present a data simulation approach, closely related to the wsj0-2mix dataset, generating sparsely overlapping speech datasets of arbitrary overlap ratio. The analysis of applying DPCL to sparsely overlapping speech is an important interim step between the fully overlapping datasets like wsj0-2mix and more realistic ASR datasets, such as CHiME-5 or AMI.