 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Text Classification of Transliterated Hindi and Malayalam
Paper and Code
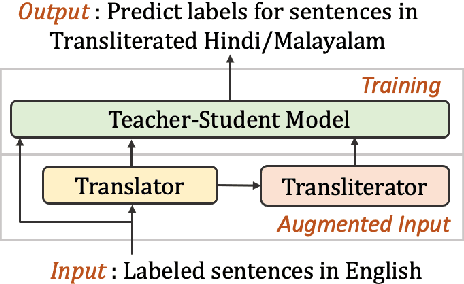
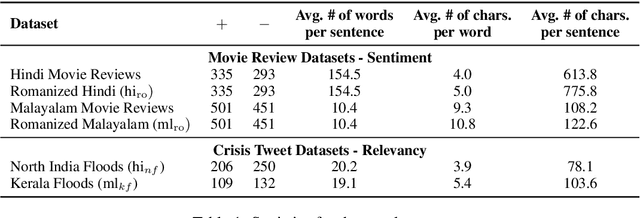

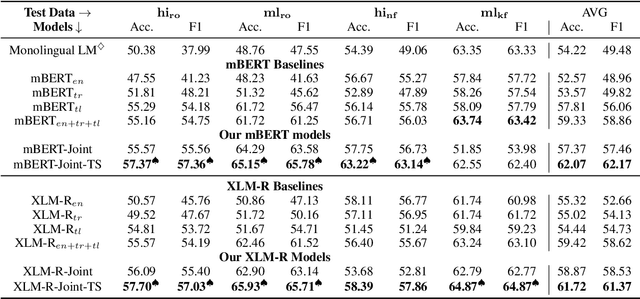
Transliteration is very common on social media, but transliterated text is not adequately handled by modern neural models for various NLP tasks. In this work, we combine data augmentation approaches with a Teacher-Student training scheme to address this issue in a cross-lingual transfer setting for fine-tuning state-of-the-art pre-trained multilingual language models such as mBERT and XLM-R. We evaluate our method on transliterated Hindi and Malayalam, also introducing new datasets for benchmarking on real-world scenarios: one on sentiment classification in transliterated Malayalam, and another on crisis tweet classification in transliterated Hindi and Malayalam (related to the 2013 North India and 2018 Kerala floods). Our method yielded an average improvement of +5.6% on mBERT and +4.7% on XLM-R in F1 scores over their strong baselines.