 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Code-Switching for Zero-Shot Cross-Lingual Intent Prediction and Slot Filling
Paper and Code


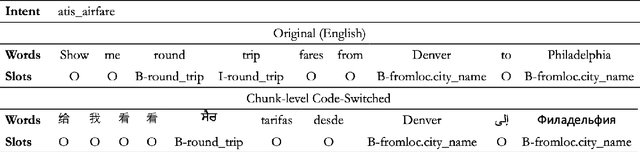
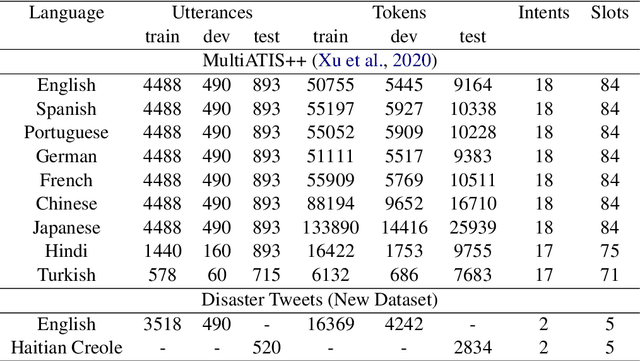
Predicting user intent and detecting the corresponding slots from text are two key problems in Natural Language Understanding (NLU). In the context of zero-shot learning, this task is typically approached by either using representations from pre-trained multilingual transformers such as mBERT, or by machine translating the source data into the known target language and then fine-tuning. Our work focuses on a particular scenario where the target language is unknown during training. To this goal, we propose a novel method to augment the monolingual source data using multilingual code-switching via random translations to enhance a transformer's language neutrality when fine-tuning it for a downstream task. This method also helps discover novel insights on how code-switching with different language families around the world impact the performance on the target language. Experiments on the benchmark dataset of MultiATIS++ yielded an average improvement of +4.2% in accuracy for intent task and +1.8% in F1 for slot task using our method over the state-of-the-art across 8 different languages. Furthermore, we present an application of our method for crisis informatics using a new human-annotated tweet dataset of slot filling in English and Haitian Creole, collected during Haiti earthquake disaster.