 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLIDER: Grading LLM Interactions and Decisions using Explainable Ranking
Dec 18, 2024



The LLM-as-judge paradigm is increasingly being adopted for automated evaluation of model outputs. While LLM judges have shown promise on constrained evaluation tasks, closed source LLMs display critical shortcomings when deployed in real world applications due to challenges of fine grained metrics and explainability, while task specific evaluation models lack cross-domain generalization. We introduce GLIDER, a powerful 3B evaluator LLM that can score any text input and associated context on arbitrary user defined criteria. GLIDER shows higher Pearson's correlation than GPT-4o on FLASK and greatly outperforms prior evaluation models, achieving comparable performance to LLMs 17x its size. GLIDER supports fine-grained scoring, multilingual reasoning, span highlighting and was trained on 685 domains and 183 criteria. Extensive qualitative analysis shows that GLIDER scores are highly correlated with human judgments, with 91.3% human agreement. We have open-sourced GLIDER to facilitate future research.
Lynx: An Open Source Hallucination Evaluation Model
Jul 11, 2024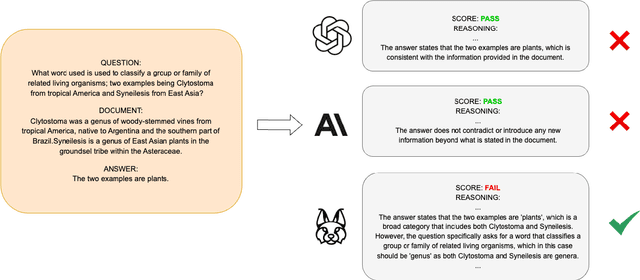
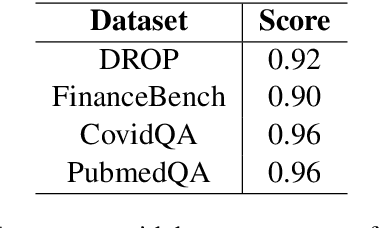
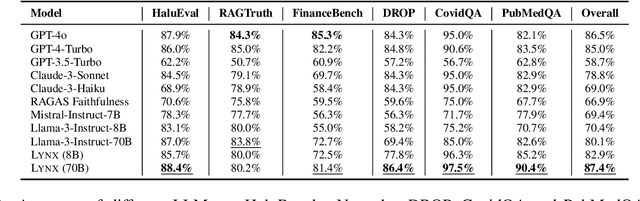
Retrieval Augmented Generation (RAG) techniques aim to mitigate hallucinations in Large Language Models (LLMs). However, LLMs can still produce information that is unsupported or contradictory to the retrieved contexts. We introduce LYNX, a SOTA hallucination detection LLM that is capable of advanced reasoning on challenging real-world hallucination scenarios. To evaluate LYNX, we present HaluBench, a comprehensive hallucination evaluation benchmark, consisting of 15k samples sourced from various real-world domains. Our experiment results show that LYNX outperforms GPT-4o, Claude-3-Sonnet, and closed and open-source LLM-as-a-judge models on HaluBench. We release LYNX, HaluBench and our evaluation code for public access.