Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLynx: An Open Source Hallucination Evaluation Model
Paper and Code
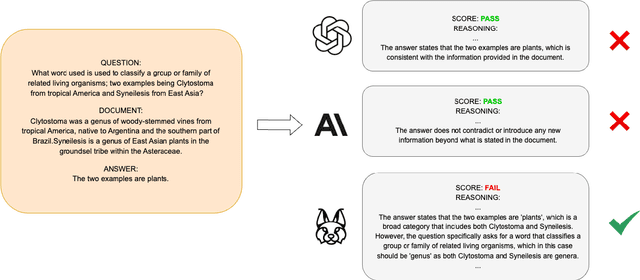
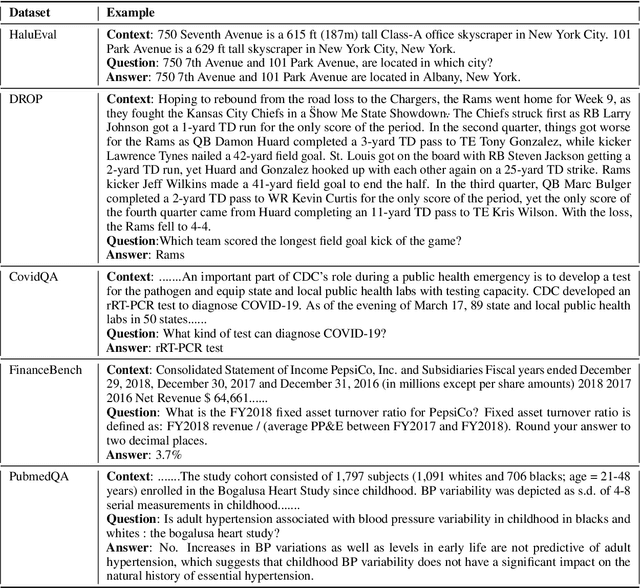
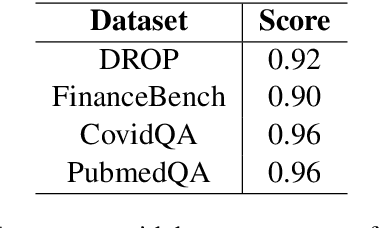
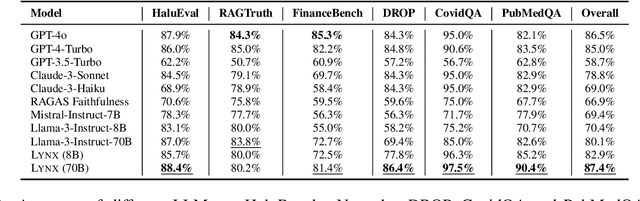
Retrieval Augmented Generation (RAG) techniques aim to mitigate hallucinations in Large Language Models (LLMs). However, LLMs can still produce information that is unsupported or contradictory to the retrieved contexts. We introduce LYNX, a SOTA hallucination detection LLM that is capable of advanced reasoning on challenging real-world hallucination scenarios. To evaluate LYNX, we present HaluBench, a comprehensive hallucination evaluation benchmark, consisting of 15k samples sourced from various real-world domains. Our experiment results show that LYNX outperforms GPT-4o, Claude-3-Sonnet, and closed and open-source LLM-as-a-judge models on HaluBench. We release LYNX, HaluBench and our evaluation code for public access.
View paper on