 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Label-Guided Summarization of Procedural and Instructional Videos
Jan 18, 2026Video summarization helps turn long videos into clear, concise representations that are easier to review, document, and analyze, especially in high-stakes domains like surgical training. Prior work has progressed from using basic visual features like color, motion, and structural changes to using pre-trained vision-language models that can better understand what's happening in the video (semantics) and capture temporal flow, resulting in more context-aware video summarization. We propose a three-stage framework, PRISM: Procedural Representation via Integrated Semantic and Multimodal analysis, that produces semantically grounded video summaries. PRISM combines adaptive visual sampling, label-driven keyframe anchoring, and contextual validation using a large language model (LLM). Our method ensures that selected frames reflect meaningful and procedural transitions while filtering out generic or hallucinated content, resulting in contextually coherent summaries across both domain-specific and instructional videos. We evaluate our method on instructional and activity datasets, using reference summaries for instructional videos. Despite sampling fewer than 5% of the original frames, our summaries retain 84% semantic content while improving over baselines by as much as 33%. Our approach generalizes across procedural and domain-specific video tasks, achieving strong performance with both semantic alignment and precision.
LExT: Towards Evaluating Trustworthiness of Natural Language Explanations
Apr 08, 2025



As Large Language Models (LLMs) become increasingly integrated into high-stakes domains, there have been several approaches proposed toward generating natural language explanations. These explanations are crucial for enhancing the interpretability of a model, especially in sensitive domains like healthcare, where transparency and reliability are key. In light of such explanations being generated by LLMs and its known concerns, there is a growing need for robust evaluation frameworks to assess model-generated explanations. Natural Language Generation metrics like BLEU and ROUGE capture syntactic and semantic accuracies but overlook other crucial aspects such as factual accuracy, consistency, and faithfulness. To address this gap, we propose a general framework for quantifying trustworthiness of natural language explanations, balancing Plausibility and Faithfulness, to derive a comprehensive Language Explanation Trustworthiness Score (LExT) (The code and set up to reproduce our experiments are publicly available at https://github.com/cerai-iitm/LExT). Applying our domain-agnostic framework to the healthcare domain using public medical datasets, we evaluate six models, including domain-specific and general-purpose models. Our findings demonstrate significant differences in their ability to generate trustworthy explanations. On comparing these explanations, we make interesting observations such as inconsistencies in Faithfulness demonstrated by general-purpose models and their tendency to outperform domain-specific fine-tuned models. This work further highlights the importance of using a tailored evaluation framework to assess natural language explanations in sensitive fields, providing a foundation for improving the trustworthiness and transparency of language models in healthcare and beyond.
BERTologyNavigator: Advanced Question Answering with BERT-based Semantics
Jan 17, 2024The development and integration of knowledge graphs and language models has significance in artificial intelligence and natural language processing. In this study, we introduce the BERTologyNavigator -- a two-phased system that combines relation extraction techniques and BERT embeddings to navigate the relationships within the DBLP Knowledge Graph (KG). Our approach focuses on extracting one-hop relations and labelled candidate pairs in the first phases. This is followed by employing BERT's CLS embeddings and additional heuristics for relation selection in the second phase. Our system reaches an F1 score of 0.2175 on the DBLP QuAD Final test dataset for Scholarly QALD and 0.98 F1 score on the subset of the DBLP QuAD test dataset during the QA phase.
* Accepted in Scholarly QALD Challenge @ ISWC 2023
Learning Type-Aware Embeddings for Fashion Compatibility
Jul 27, 2018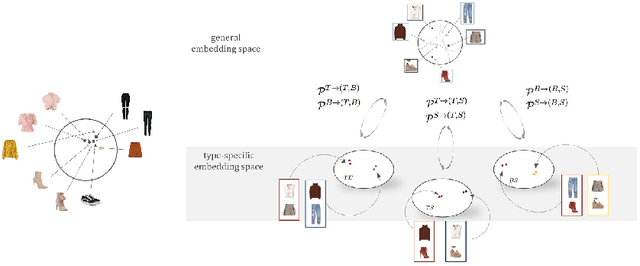

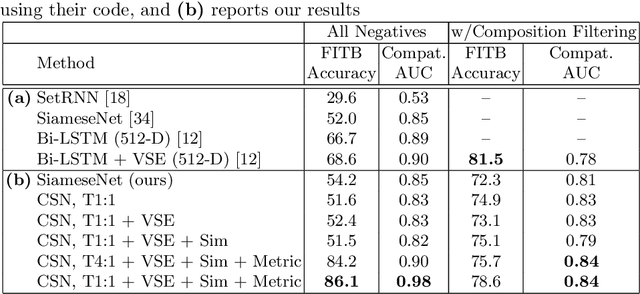

Outfits in online fashion data are composed of items of many different types (e.g. top, bottom, shoes) that share some stylistic relationship with one another. A representation for building outfits requires a method that can learn both notions of similarity (for example, when two tops are interchangeable) and compatibility (items of possibly different type that can go together in an outfit). This paper presents an approach to learning an image embedding that respects item type, and jointly learns notions of item similarity and compatibility in an end-to-end model. To evaluate the learned representation, we crawled 68,306 outfits created by users on the Polyvore website. Our approach obtains 3-5% improvement over the state-of-the-art on outfit compatibility prediction and fill-in-the-blank tasks using our dataset, as well as an established smaller dataset, while supporting a variety of useful queries.
Octopus: A Framework for Cost-Quality-Time Optimization in Crowdsourcing
Aug 15, 2017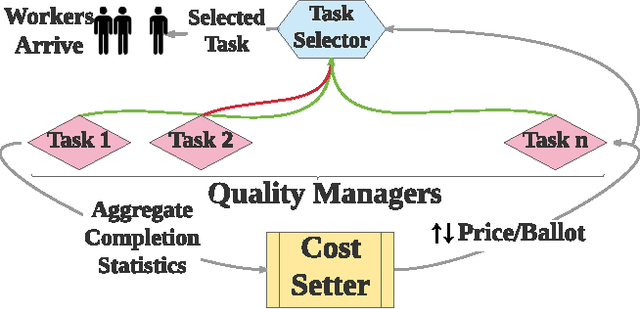

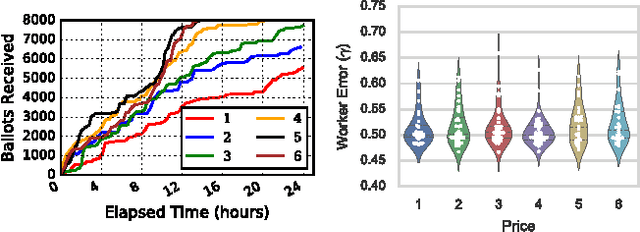
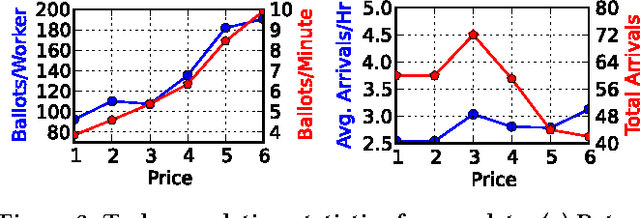
We present Octopus, an AI agent to jointly balance three conflicting task objectives on a micro-crowdsourcing marketplace - the quality of work, total cost incurred, and time to completion. Previous control agents have mostly focused on cost-quality, or cost-time tradeoffs, but not on directly controlling all three in concert. A naive formulation of three-objective optimization is intractable; Octopus takes a hierarchical POMDP approach, with three different components responsible for setting the pay per task, selecting the next task, and controlling task-level quality. We demonstrate that Octopus significantly outperforms existing state-of-the-art approaches on real experiments. We also deploy Octopus on Amazon Mechanical Turk, showing its ability to manage tasks in a real-world dynamic setting.