 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge driven Description Synthesis for Floor Plan Interpretation
Mar 15, 2021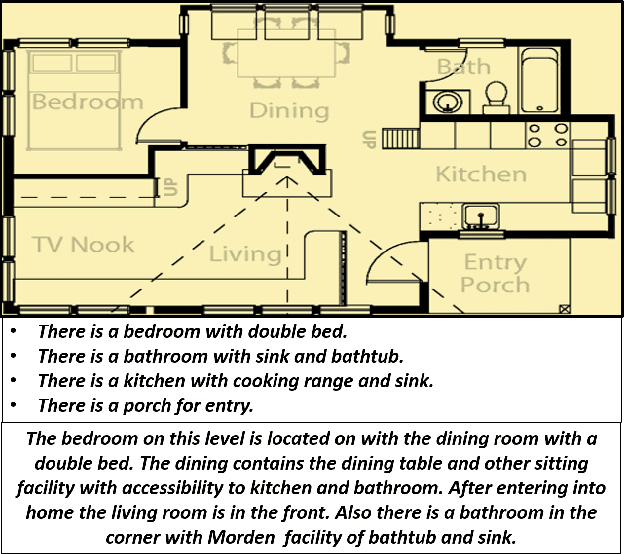
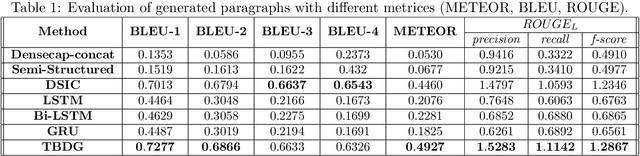
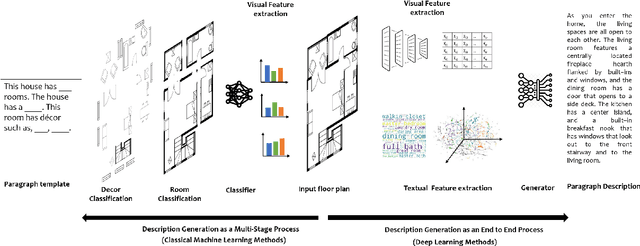
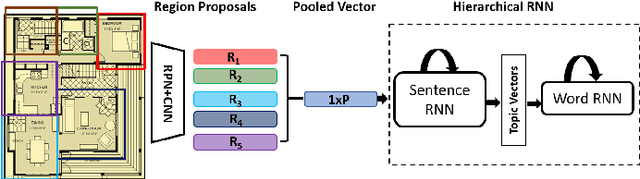
Image captioning is a widely known problem in the area of AI. Caption generation from floor plan images has applications in indoor path planning, real estate, and providing architectural solutions. Several methods have been explored in literature for generating captions or semi-structured descriptions from floor plan images. Since only the caption is insufficient to capture fine-grained details, researchers also proposed descriptive paragraphs from images. However, these descriptions have a rigid structure and lack flexibility, making it difficult to use them in real-time scenarios. This paper offers two models, Description Synthesis from Image Cue (DSIC) and Transformer Based Description Generation (TBDG), for the floor plan image to text generation to fill the gaps in existing methods. These two models take advantage of modern deep neural networks for visual feature extraction and text generation. The difference between both models is in the way they take input from the floor plan image. The DSIC model takes only visual features automatically extracted by a deep neural network, while the TBDG model learns textual captions extracted from input floor plan images with paragraphs. The specific keywords generated in TBDG and understanding them with paragraphs make it more robust in a general floor plan image. Experiments were carried out on a large-scale publicly available dataset and compared with state-of-the-art techniques to show the proposed model's superiority.
GRIHA: Synthesizing 2-Dimensional Building Layouts from Images Captured using a Smart Phone
Mar 15, 2021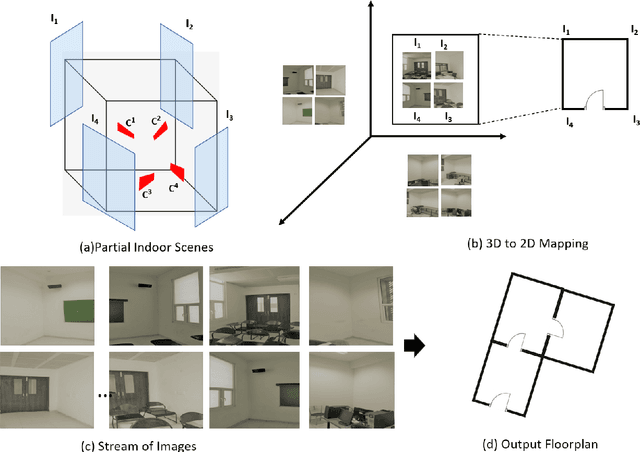



Reconstructing an indoor scene and generating a layout/floor plan in 3D or 2D is a widely known problem. Quite a few algorithms have been proposed in the literature recently. However, most existing methods either use RGB-D images, thus requiring a depth camera, or depending on panoramic photos, assuming that there is little to no occlusion in the rooms. In this work, we proposed GRIHA (Generating Room Interior of a House using ARCore), a framework for generating a layout using an RGB image captured using a simple mobile phone camera. We take advantage of Simultaneous Localization and Mapping (SLAM) to assess the 3D transformations required for layout generation. SLAM technology is built-in in recent mobile libraries such as ARCore by Google. Hence, the proposed method is fast and efficient. It gives the user freedom to generate layout by merely taking a few conventional photos, rather than relying on specialized depth hardware or occlusion-free panoramic images. We have compared GRIHA with other existing methods and obtained superior results. Also, the system is tested on multiple hardware platforms to test the dependency and efficiency.
Student Mixture Model Based Visual Servoing
Jun 19, 2020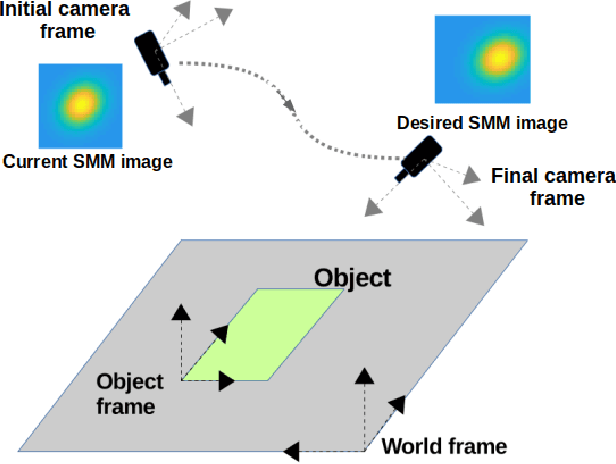
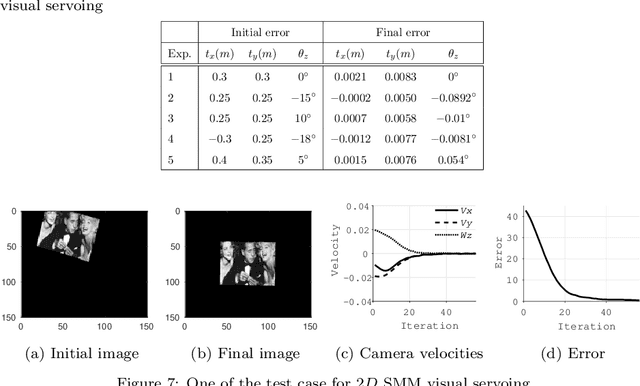
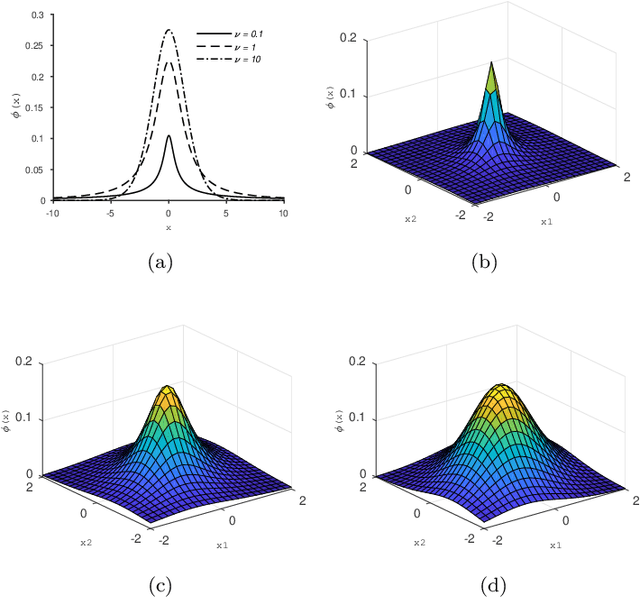
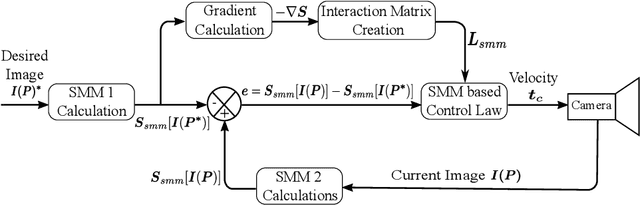
Classical Image-Based Visual Servoing (IBVS) makes use of geometric image features like point, straight line and image moments to control a robotic system. Robust extraction and real-time tracking of these features are crucial to the performance of the IBVS. Moreover, such features can be unsuitable for real world applications where it might not be easy to distinguish a target from the rest of the environment. Alternatively, an approach based on complete photometric data can avoid the requirement of feature extraction, tracking and object detection. In this work, we propose one such probabilistic model based approach which uses entire photometric data for the purpose of visual servoing. A novel image modelling method has been proposed using Student Mixture Model (SMM), which is based on Multivariate Student's t-Distribution. Consequently, a vision-based control law is formulated as a least squares minimisation problem. Efficacy of the proposed framework is demonstrated for 2D and 3D positioning tasks showing favourable error convergence and acceptable camera trajectories. Numerical experiments are also carried out to show robustness to distinct image scenes and partial occlusion.
Automatic Rendering of Building Floor Plan Images from Textual Descriptions in English
Nov 29, 2018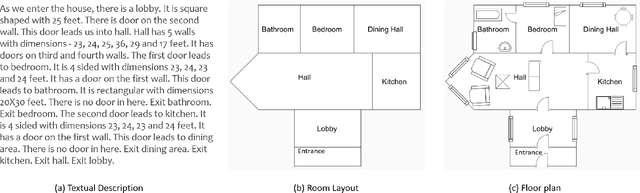
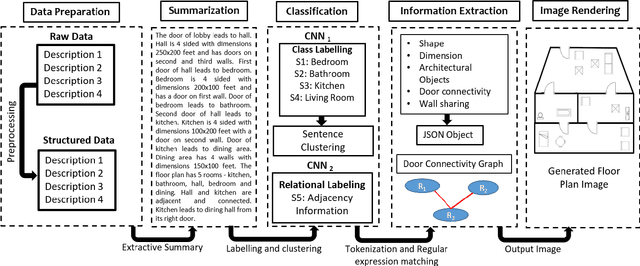
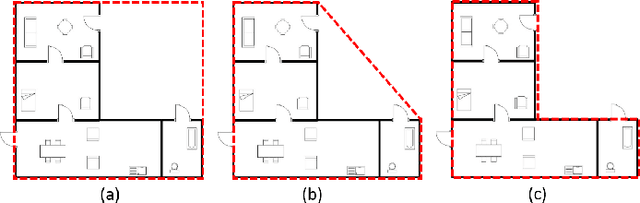
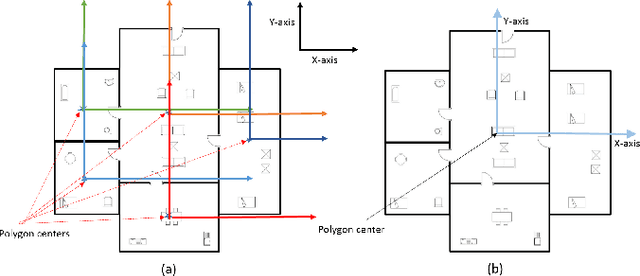
Human beings understand natural language description and could able to imagine a corresponding visual for the same. For example, given a description of the interior of a house, we could imagine its structure and arrangements of furniture. Automatic synthesis of real-world images from text descriptions has been explored in the computer vision community. However, there is no such attempt in the area of document images, like floor plans. Floor plan synthesis from sketches, as well as data-driven models, were proposed earlier. Ours is the first attempt to render building floor plan images from textual description automatically. Here, the input is a natural language description of the internal structure and furniture arrangements within a house, and the output is the 2D floor plan image of the same. We have experimented on publicly available benchmark floor plan datasets. We were able to render realistic synthesized floor plan images from the description written in English.
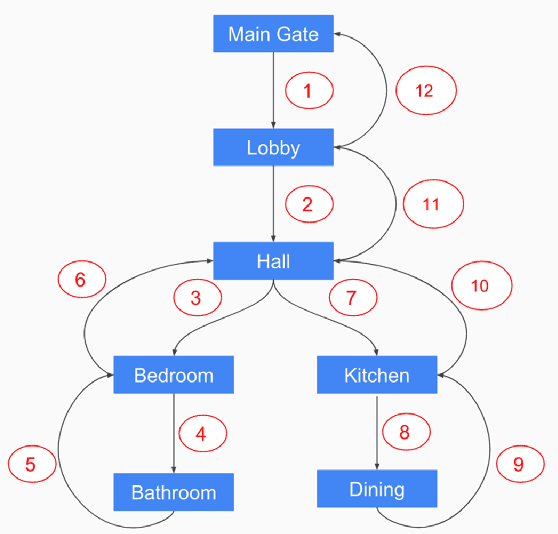
SUGAMAN: Describing Floor Plans for Visually Impaired by Annotation Learning and Proximity based Grammar
Nov 14, 2018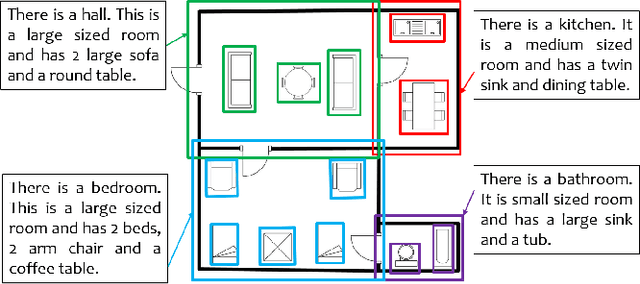
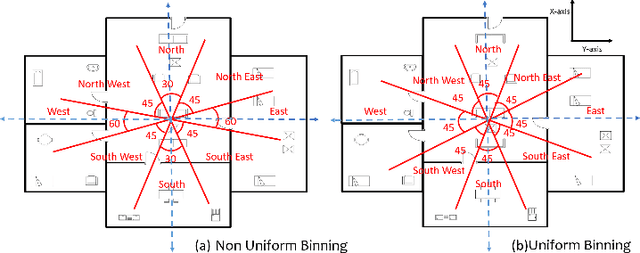
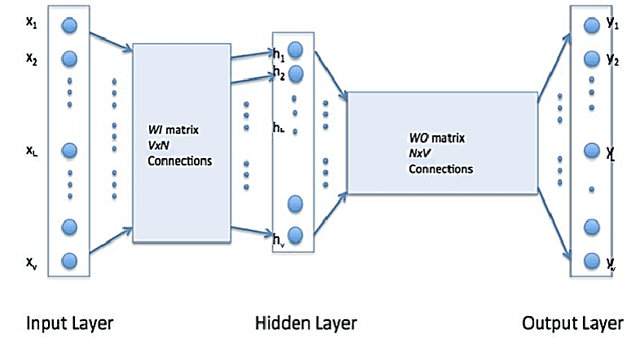
In this paper, we propose SUGAMAN (Supervised and Unified framework using Grammar and Annotation Model for Access and Navigation). SUGAMAN is a Hindi word meaning "easy passage from one place to another". SUGAMAN synthesizes textual description from a given floor plan image for the visually impaired. A visually impaired person can navigate in an indoor environment using the textual description generated by SUGAMAN. With the help of a text reader software, the target user can understand the rooms within the building and arrangement of furniture to navigate. SUGAMAN is the first framework for describing a floor plan and giving direction for obstacle-free movement within a building. We learn $5$ classes of room categories from $1355$ room image samples under a supervised learning paradigm. These learned annotations are fed into a description synthesis framework to yield a holistic description of a floor plan image. We demonstrate the performance of various supervised classifiers on room learning. We also provide a comparative analysis of system generated and human written descriptions. SUGAMAN gives state of the art performance on challenging, real-world floor plan images. This work can be applied to areas like understanding floor plans of historical monuments, stability analysis of buildings, and retrieval.