 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUGAMAN: Describing Floor Plans for Visually Impaired by Annotation Learning and Proximity based Grammar
Paper and Code
Nov 14, 2018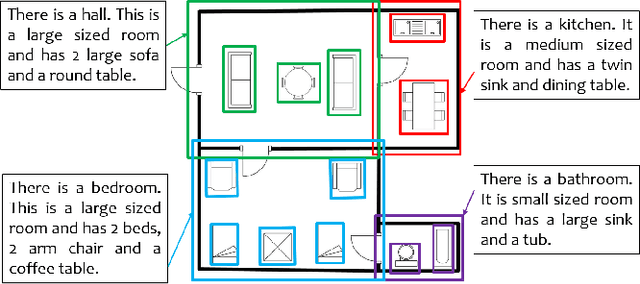
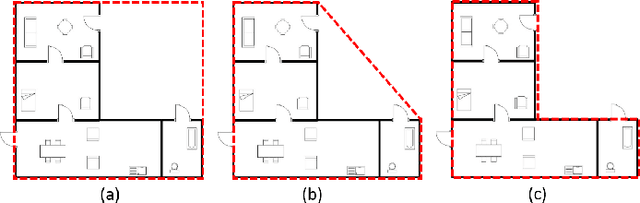
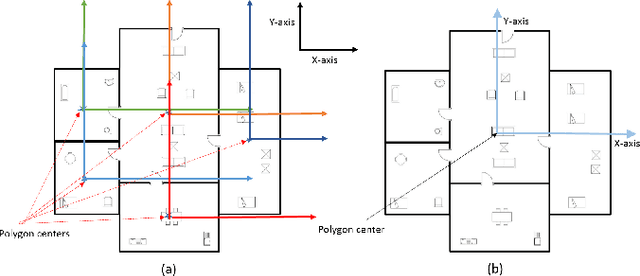
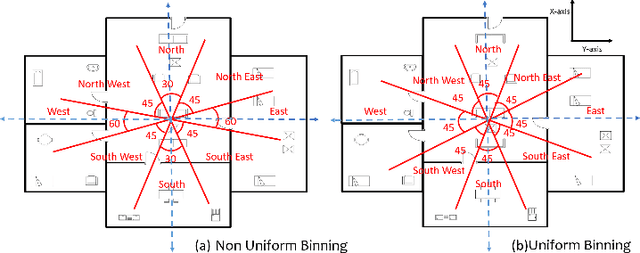
In this paper, we propose SUGAMAN (Supervised and Unified framework using Grammar and Annotation Model for Access and Navigation). SUGAMAN is a Hindi word meaning "easy passage from one place to another". SUGAMAN synthesizes textual description from a given floor plan image for the visually impaired. A visually impaired person can navigate in an indoor environment using the textual description generated by SUGAMAN. With the help of a text reader software, the target user can understand the rooms within the building and arrangement of furniture to navigate. SUGAMAN is the first framework for describing a floor plan and giving direction for obstacle-free movement within a building. We learn $5$ classes of room categories from $1355$ room image samples under a supervised learning paradigm. These learned annotations are fed into a description synthesis framework to yield a holistic description of a floor plan image. We demonstrate the performance of various supervised classifiers on room learning. We also provide a comparative analysis of system generated and human written descriptions. SUGAMAN gives state of the art performance on challenging, real-world floor plan images. This work can be applied to areas like understanding floor plans of historical monuments, stability analysis of buildings, and retrieval.