 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey in Adversarial Defences and Robustness in NLP
Paper and Code
Apr 12, 2022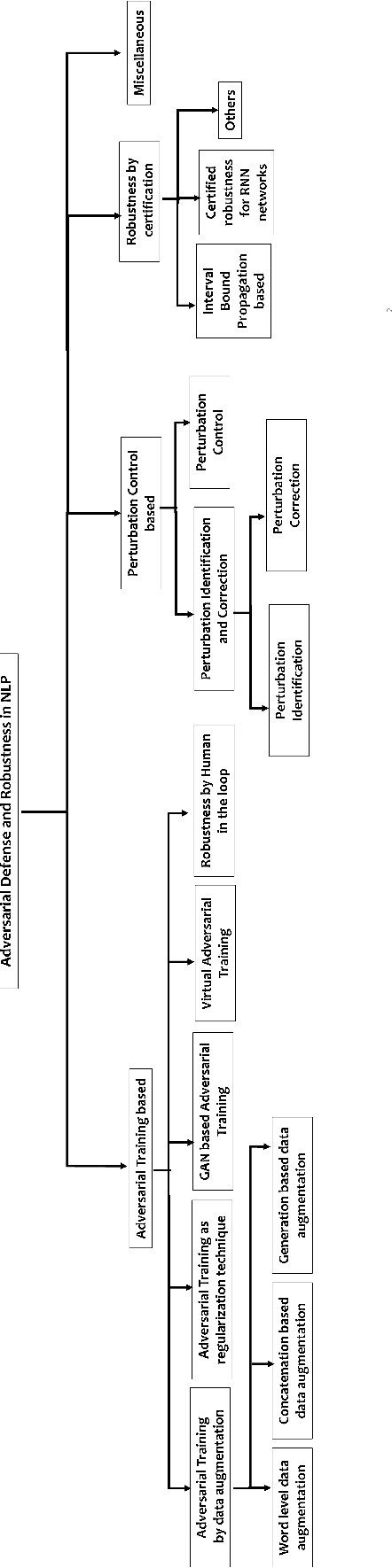
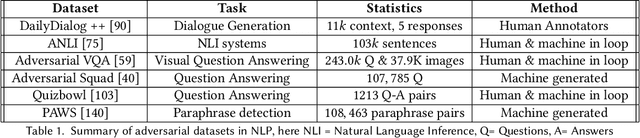
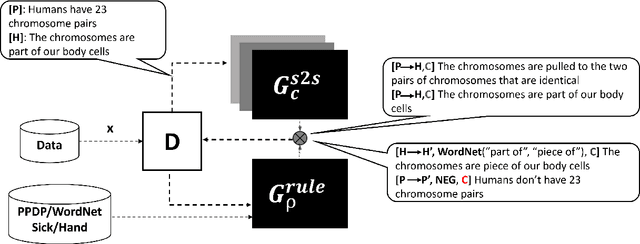

In recent years, it has been seen that deep neural networks are lacking robustness and are likely to break in case of adversarial perturbations in input data. Strong adversarial attacks are proposed by various authors for computer vision and Natural Language Processing (NLP). As a counter-effort, several defense mechanisms are also proposed to save these networks from failing. In contrast with image data, generating adversarial attacks and defending these models is not easy in NLP because of the discrete nature of the text data. However, numerous methods for adversarial defense are proposed of late, for different NLP tasks such as text classification, named entity recognition, natural language inferencing, etc. These methods are not just used for defending neural networks from adversarial attacks, but also used as a regularization mechanism during training, saving the model from overfitting. The proposed survey is an attempt to review different methods proposed for adversarial defenses in NLP in the recent past by proposing a novel taxonomy. This survey also highlights the fragility of the advanced deep neural networks in NLP and the challenges in defending them.