 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndicXTREME: A Multi-Task Benchmark For Evaluating Indic Languages
Paper and Code
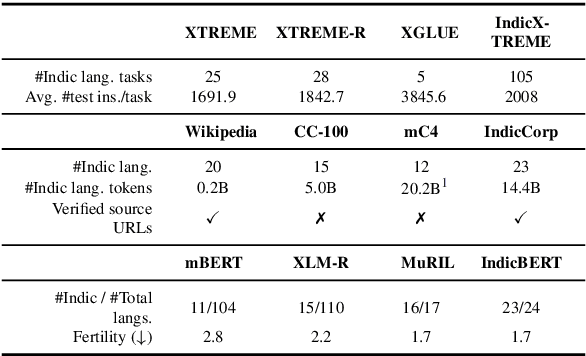
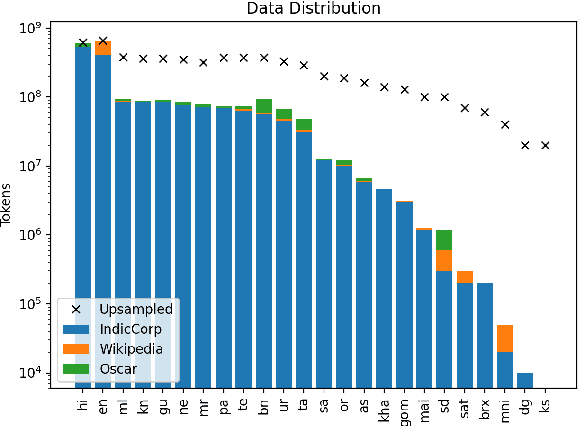
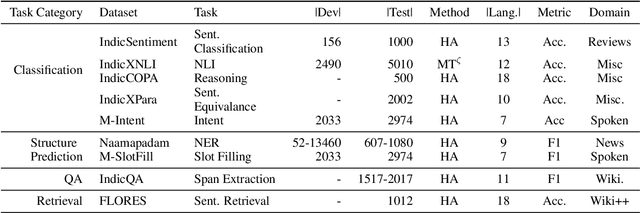
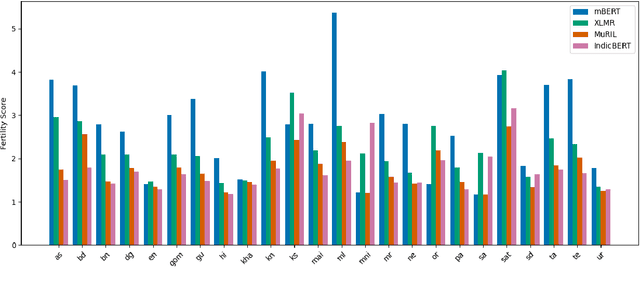
In this work, we introduce IndicXTREME, a benchmark consisting of nine diverse tasks covering 18 languages from the Indic sub-continent belonging to four different families. Across languages and tasks, IndicXTREME contains a total of 103 evaluation sets, of which 51 are new contributions to the literature. To maintain high quality, we only use human annotators to curate or translate our datasets. To the best of our knowledge, this is the first effort toward creating a standard benchmark for Indic languages that aims to test the zero-shot capabilities of pretrained language models. We also release IndicCorp v2, an updated and much larger version of IndicCorp that contains 20.9 billion tokens in 24 languages. We pretrain IndicBERT v2 on IndicCorp v2 and evaluate it on IndicXTREME to show that it outperforms existing multilingual language models such as XLM-R and MuRIL.