 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-paced Data Augmentation for Training Neural Networks
Paper and Code
Oct 29, 2020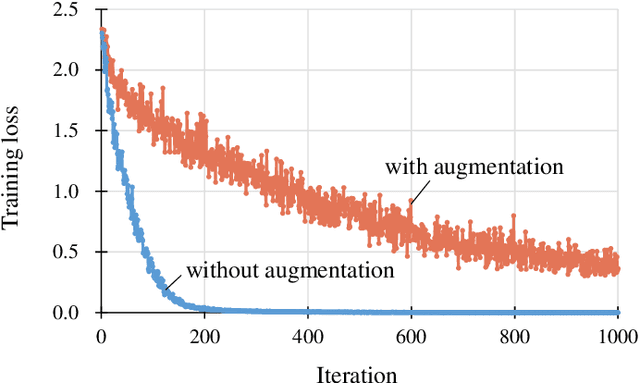
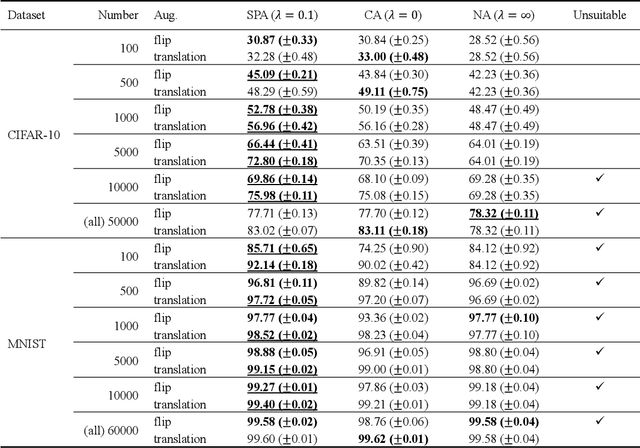
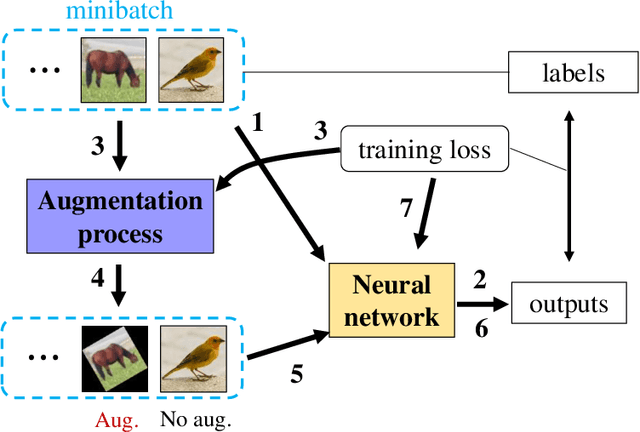
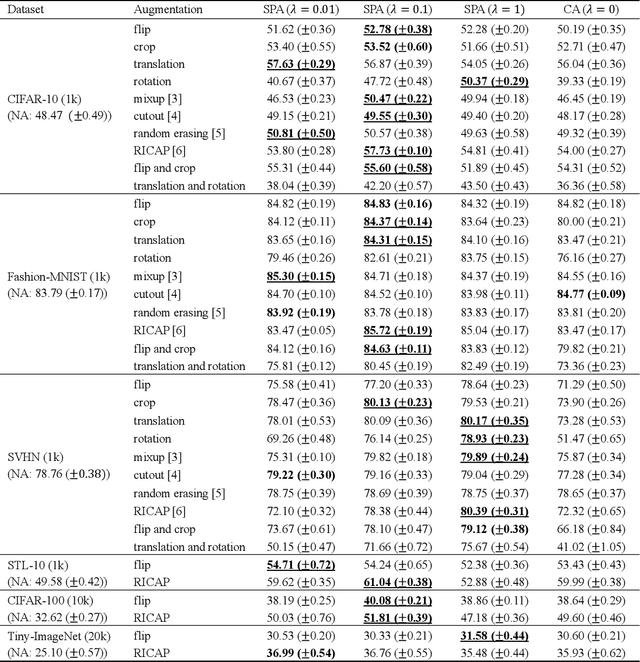
Data augmentation is widely used for machine learning; however, an effective method to apply data augmentation has not been established even though it includes several factors that should be tuned carefully. One such factor is sample suitability, which involves selecting samples that are suitable for data augmentation. A typical method that applies data augmentation to all training samples disregards sample suitability, which may reduce classifier performance. To address this problem, we propose the self-paced augmentation (SPA) to automatically and dynamically select suitable samples for data augmentation when training a neural network. The proposed method mitigates the deterioration of generalization performance caused by ineffective data augmentation. We discuss two reasons the proposed SPA works relative to curriculum learning and desirable changes to loss function instability. Experimental results demonstrate that the proposed SPA can improve the generalization performance, particularly when the number of training samples is small. In addition, the proposed SPA outperforms the state-of-the-art RandAugment method.