 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Mechanical Analysis of Catastrophic Forgetting in Continual Learning with Teacher and Student Networks
Paper and Code
May 16, 2021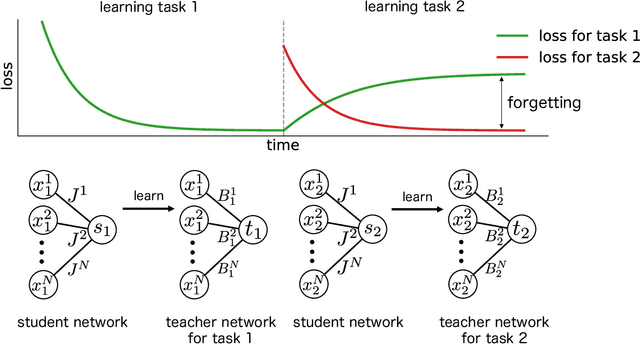
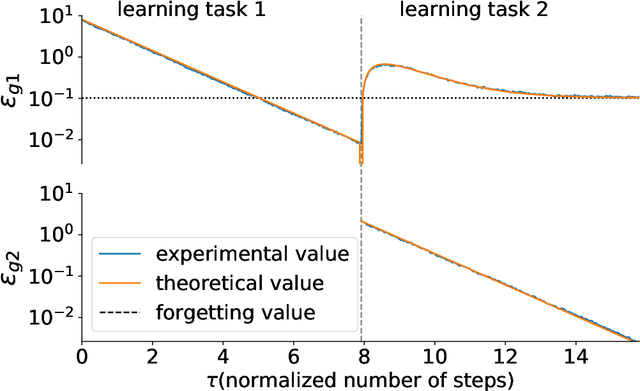
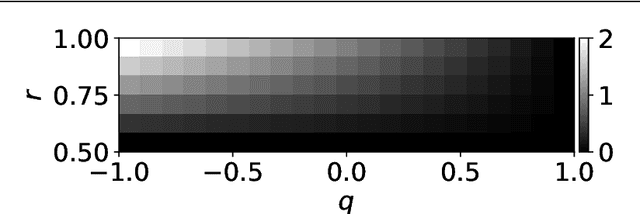
When a computational system continuously learns from an ever-changing environment, it rapidly forgets its past experiences. This phenomenon is called catastrophic forgetting. While a line of studies has been proposed with respect to avoiding catastrophic forgetting, most of the methods are based on intuitive insights into the phenomenon, and their performances have been evaluated by numerical experiments using benchmark datasets. Therefore, in this study, we provide the theoretical framework for analyzing catastrophic forgetting by using teacher-student learning. Teacher-student learning is a framework in which we introduce two neural networks: one neural network is a target function in supervised learning, and the other is a learning neural network. To analyze continual learning in the teacher-student framework, we introduce the similarity of the input distribution and the input-output relationship of the target functions as the similarity of tasks. In this theoretical framework, we also provide a qualitative understanding of how a single-layer linear learning neural network forgets tasks. Based on the analysis, we find that the network can avoid catastrophic forgetting when the similarity among input distributions is small and that of the input-output relationship of the target functions is large. The analysis also suggests that a system often exhibits a characteristic phenomenon called overshoot, which means that even if the learning network has once undergone catastrophic forgetting, it is possible that the network may perform reasonably well after further learning of the current task.