 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Peg Insertion: Identifying Mating Holes and Estimating SE(2) Poses with Vision-Language Models
Paper and Code
Mar 08, 2025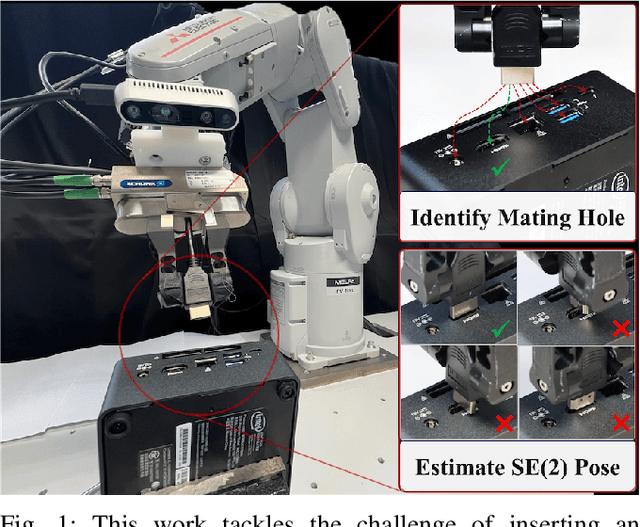
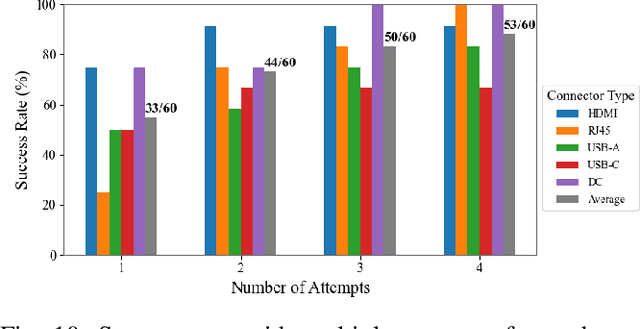
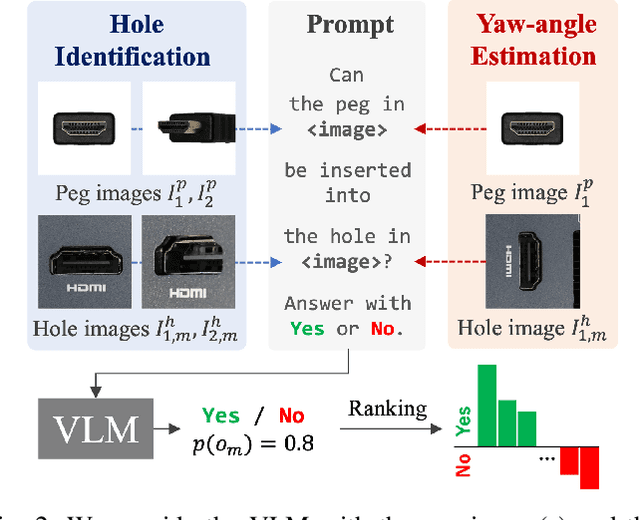
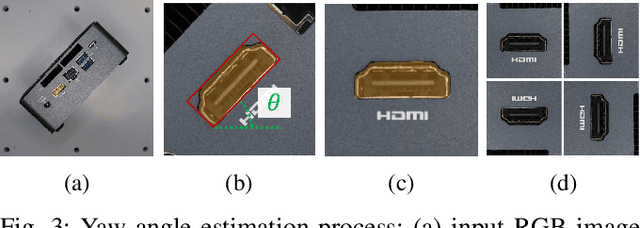
Achieving zero-shot peg insertion, where inserting an arbitrary peg into an unseen hole without task-specific training, remains a fundamental challenge in robotics. This task demands a highly generalizable perception system capable of detecting potential holes, selecting the correct mating hole from multiple candidates, estimating its precise pose, and executing insertion despite uncertainties. While learning-based methods have been applied to peg insertion, they often fail to generalize beyond the specific peg-hole pairs encountered during training. Recent advancements in Vision-Language Models (VLMs) offer a promising alternative, leveraging large-scale datasets to enable robust generalization across diverse tasks. Inspired by their success, we introduce a novel zero-shot peg insertion framework that utilizes a VLM to identify mating holes and estimate their poses without prior knowledge of their geometry. Extensive experiments demonstrate that our method achieves 90.2% accuracy, significantly outperforming baselines in identifying the correct mating hole across a wide range of previously unseen peg-hole pairs, including 3D-printed objects, toy puzzles, and industrial connectors. Furthermore, we validate the effectiveness of our approach in a real-world connector insertion task on a backpanel of a PC, where our system successfully detects holes, identifies the correct mating hole, estimates its pose, and completes the insertion with a success rate of 88.3%. These results highlight the potential of VLM-driven zero-shot reasoning for enabling robust and generalizable robotic assembly.