 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomaly Object Segmentation with Vision-Language Models for Steel Scrap Recycling
Jun 16, 2025Recycling steel scrap can reduce carbon dioxide (CO2) emissions from the steel industry. However, a significant challenge in steel scrap recycling is the inclusion of impurities other than steel. To address this issue, we propose vision-language-model-based anomaly detection where a model is finetuned in a supervised manner, enabling it to handle niche objects effectively. This model enables automated detection of anomalies at a fine-grained level within steel scrap. Specifically, we finetune the image encoder, equipped with multi-scale mechanism and text prompts aligned with both normal and anomaly images. The finetuning process trains these modules using a multiclass classification as the supervision.
Cyberoception: Finding a Painlessly-Measurable New Sense in the Cyberworld Towards Emotion-Awareness in Computing
Apr 23, 2025In Affective computing, recognizing users' emotions accurately is the basis of affective human-computer interaction. Understanding users' interoception contributes to a better understanding of individually different emotional abilities, which is essential for achieving inter-individually accurate emotion estimation. However, existing interoception measurement methods, such as the heart rate discrimination task, have several limitations, including their dependence on a well-controlled laboratory environment and precision apparatus, making monitoring users' interoception challenging. This study aims to determine other forms of data that can explain users' interoceptive or similar states in their real-world lives and propose a novel hypothetical concept "cyberoception," a new sense (1) which has properties similar to interoception in terms of the correlation with other emotion-related abilities, and (2) which can be measured only by the sensors embedded inside commodity smartphone devices in users' daily lives. Results from a 10-day-long in-lab/in-the-wild hybrid experiment reveal a specific cyberoception type "Turn On" (users' subjective sensory perception about the frequency of turning-on behavior on their smartphones), significantly related to participants' emotional valence. We anticipate that cyberoception to serve as a fundamental building block for developing more "emotion-aware", user-friendly applications and services.
Multi-Point Positional Insertion Tuning for Small Object Detection
Dec 24, 2024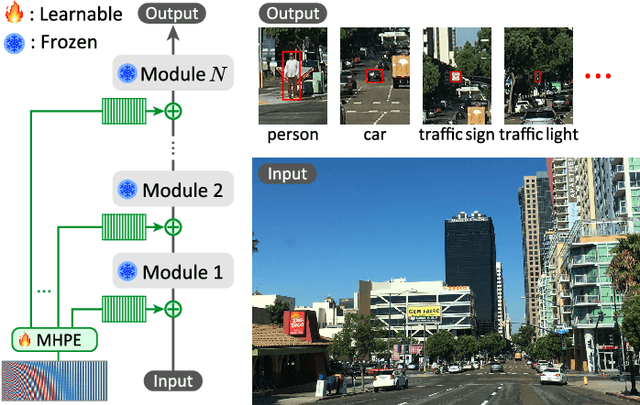
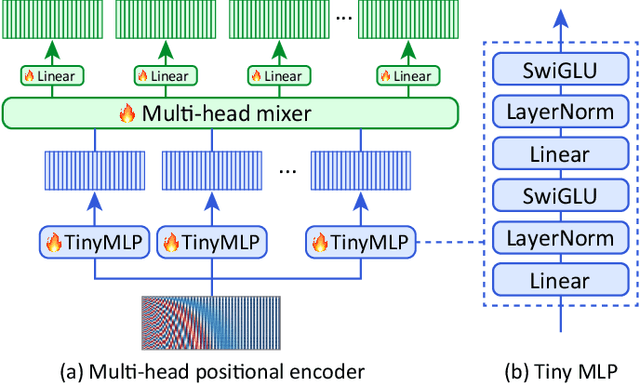
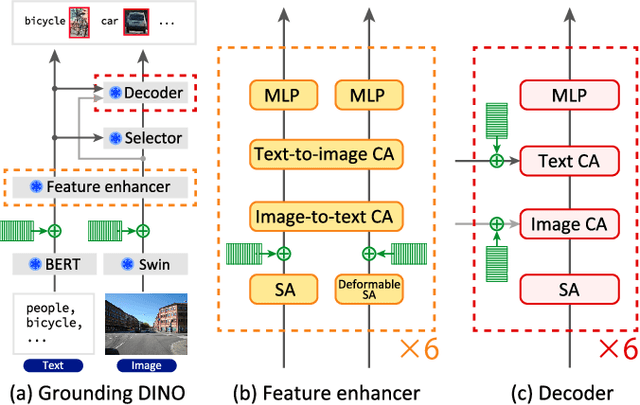

Small object detection aims to localize and classify small objects within images. With recent advances in large-scale vision-language pretraining, finetuning pretrained object detection models has emerged as a promising approach. However, finetuning large models is computationally and memory expensive. To address this issue, this paper introduces multi-point positional insertion (MPI) tuning, a parameter-efficient finetuning (PEFT) method for small object detection. Specifically, MPI incorporates multiple positional embeddings into a frozen pretrained model, enabling the efficient detection of small objects by providing precise positional information to latent features. Through experiments, we demonstrated the effectiveness of the proposed method on the SODA-D dataset. MPI performed comparably to conventional PEFT methods, including CoOp and VPT, while significantly reducing the number of parameters that need to be tuned.
End-to-End Monocular Vanishing Point Detection Exploiting Lane Annotations
Aug 31, 2021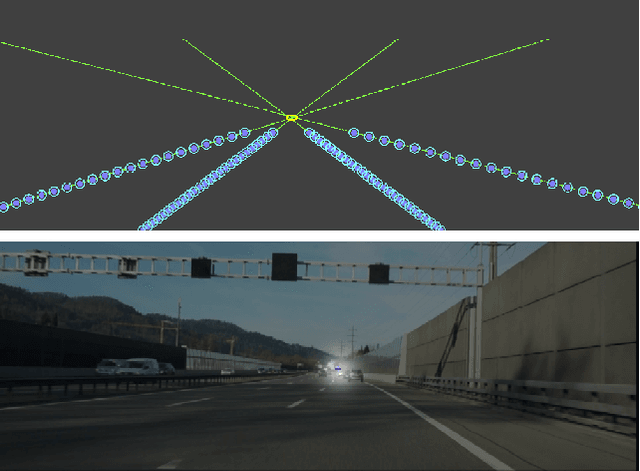
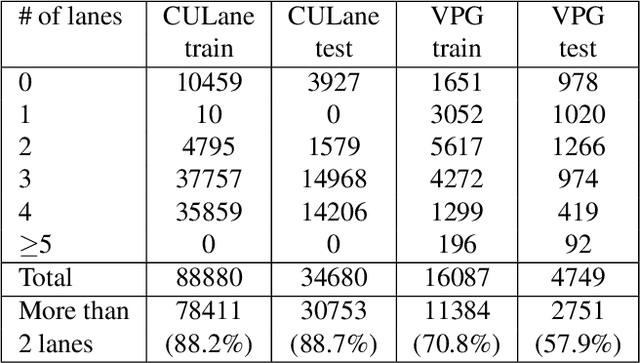
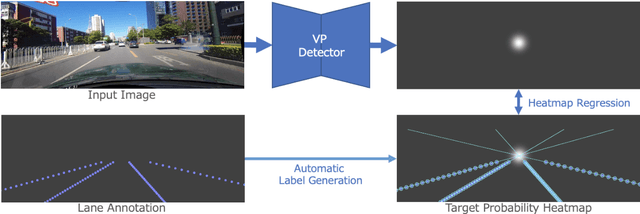
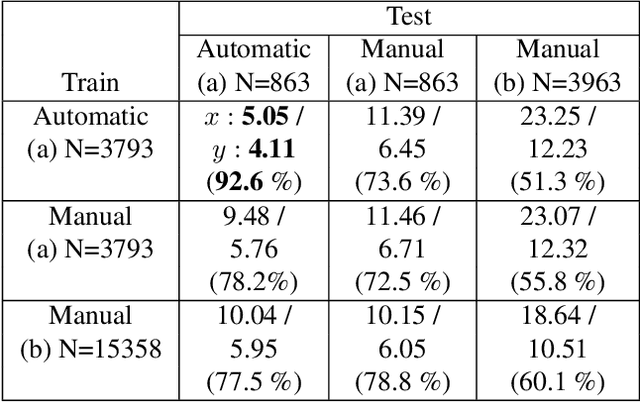
Vanishing points (VPs) play a vital role in various computer vision tasks, especially for recognizing the 3D scenes from an image. In the real-world scenario of automobile applications, it is costly to manually obtain the external camera parameters when the camera is attached to the vehicle or the attachment is accidentally perturbed. In this paper we introduce a simple but effective end-to-end vanishing point detection. By automatically calculating intersection of the extrapolated lane marker annotations, we obtain geometrically consistent VP labels and mitigate human annotation errors caused by manual VP labeling. With the calculated VP labels we train end-to-end VP Detector via heatmap estimation. The VP Detector realizes higher accuracy than the methods utilizing manual annotation or lane detection, paving the way for accurate online camera calibration.