 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLRerNet: Improving Confidence of Lane Detection with LaneIoU
May 15, 2023



Lane marker detection is a crucial component of the autonomous driving and driver assistance systems. Modern deep lane detection methods with row-based lane representation exhibit excellent performance on lane detection benchmarks. Through preliminary oracle experiments, we firstly disentangle the lane representation components to determine the direction of our approach. We show that correct lane positions are already among the predictions of an existing row-based detector, and the confidence scores that accurately represent intersection-over-union (IoU) with ground truths are the most beneficial. Based on the finding, we propose LaneIoU that better correlates with the metric, by taking the local lane angles into consideration. We develop a novel detector coined CLRerNet featuring LaneIoU for the target assignment cost and loss functions aiming at the improved quality of confidence scores. Through careful and fair benchmark including cross validation, we demonstrate that CLRerNet outperforms the state-of-the-art by a large margin - enjoying F1 score of 81.43% compared with 80.47% of the existing method on CULane, and 86.47% compared with 86.10% on CurveLanes.
End-to-End Monocular Vanishing Point Detection Exploiting Lane Annotations
Aug 31, 2021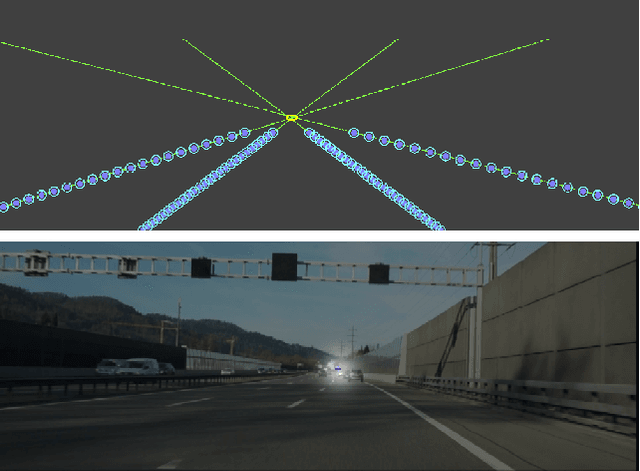
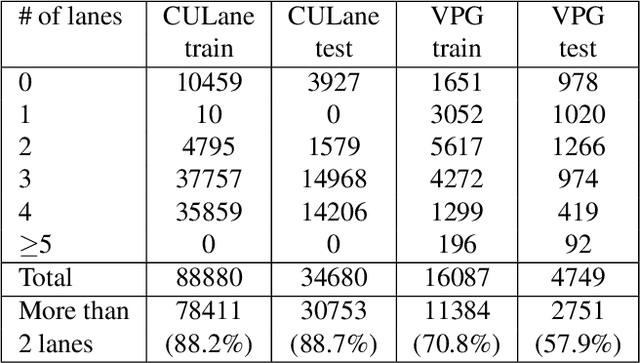
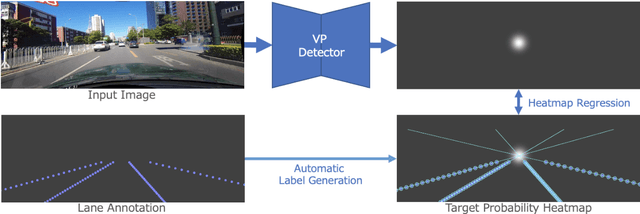
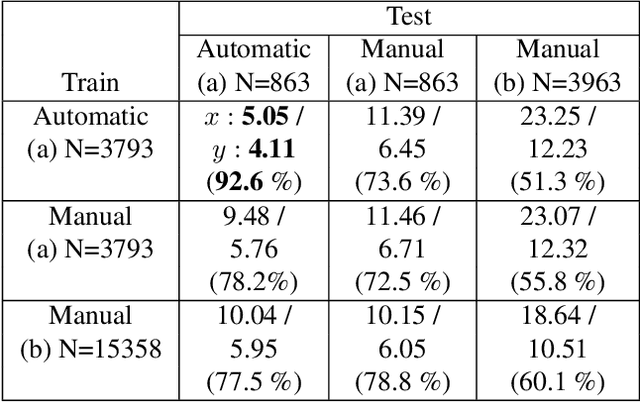
Vanishing points (VPs) play a vital role in various computer vision tasks, especially for recognizing the 3D scenes from an image. In the real-world scenario of automobile applications, it is costly to manually obtain the external camera parameters when the camera is attached to the vehicle or the attachment is accidentally perturbed. In this paper we introduce a simple but effective end-to-end vanishing point detection. By automatically calculating intersection of the extrapolated lane marker annotations, we obtain geometrically consistent VP labels and mitigate human annotation errors caused by manual VP labeling. With the calculated VP labels we train end-to-end VP Detector via heatmap estimation. The VP Detector realizes higher accuracy than the methods utilizing manual annotation or lane detection, paving the way for accurate online camera calibration.
Leveraging Temporal Joint Depths for Improving 3D Human Pose Estimation in Video
Nov 04, 2020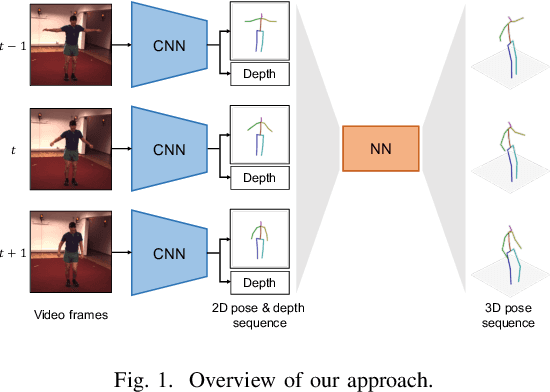

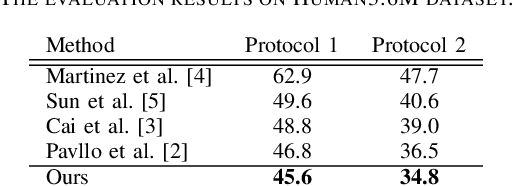
The effectiveness of the approaches to predict 3D poses from 2D poses estimated in each frame of a video has been demonstrated for 3D human pose estimation. However, 2D poses without appearance information of persons have much ambiguity with respect to the joint depths. In this paper, we propose to estimate a 3D pose in each frame of a video and refine it considering temporal information. The proposed approach reduces the ambiguity of the joint depths and improves the 3D pose estimation accuracy.
Full-body High-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks
Sep 06, 2018
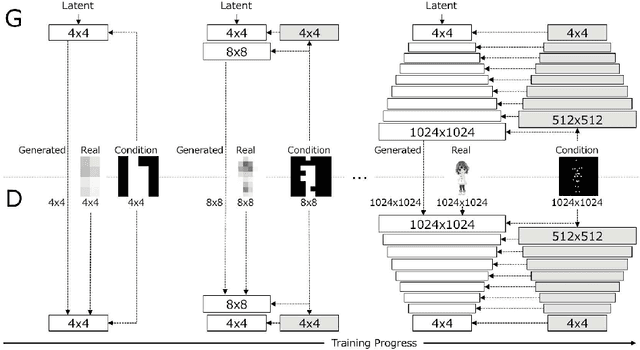


We propose Progressive Structure-conditional Generative Adversarial Networks (PSGAN), a new framework that can generate full-body and high-resolution character images based on structural information. Recent progress in generative adversarial networks with progressive training has made it possible to generate high-resolution images. However, existing approaches have limitations in achieving both high image quality and structural consistency at the same time. Our method tackles the limitations by progressively increasing the resolution of both generated images and structural conditions during training. In this paper, we empirically demonstrate the effectiveness of this method by showing the comparison with existing approaches and video generation results of diverse anime characters at 1024x1024 based on target pose sequences. We also create a novel dataset containing full-body 1024x1024 high-resolution images and exact 2D pose keypoints using Unity 3D Avatar models.