Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Temporal Joint Depths for Improving 3D Human Pose Estimation in Video
Paper and Code
Nov 04, 2020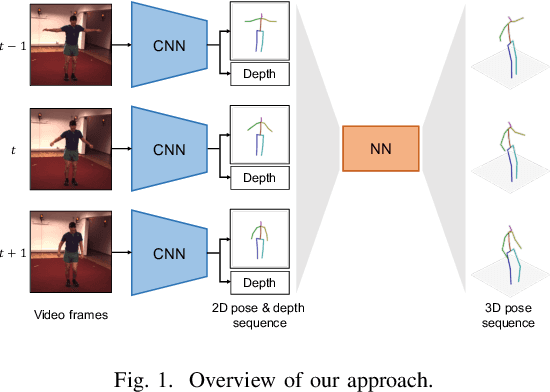

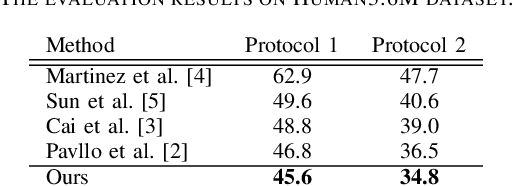
The effectiveness of the approaches to predict 3D poses from 2D poses estimated in each frame of a video has been demonstrated for 3D human pose estimation. However, 2D poses without appearance information of persons have much ambiguity with respect to the joint depths. In this paper, we propose to estimate a 3D pose in each frame of a video and refine it considering temporal information. The proposed approach reduces the ambiguity of the joint depths and improves the 3D pose estimation accuracy.
View paper on