 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse BEV Fusion with Self-View Consistency for Multi-View Detection and Tracking
Sep 10, 2025Multi-View Multi-Object Tracking (MVMOT) is essential for applications such as surveillance, autonomous driving, and sports analytics. However, maintaining consistent object identities across multiple cameras remains challenging due to viewpoint changes, lighting variations, and occlusions, which often lead to tracking errors.Recent methods project features from multiple cameras into a unified Bird's-Eye-View (BEV) space to improve robustness against occlusion. However, this projection introduces feature distortion and non-uniform density caused by variations in object scale with distance. These issues degrade the quality of the fused representation and reduce detection and tracking accuracy.To address these problems, we propose SCFusion, a framework that combines three techniques to improve multi-view feature integration. First, it applies a sparse transformation to avoid unnatural interpolation during projection. Next, it performs density-aware weighting to adaptively fuse features based on spatial confidence and camera distance. Finally, it introduces a multi-view consistency loss that encourages each camera to learn discriminative features independently before fusion.Experiments show that SCFusion achieves state-of-the-art performance, reaching an IDF1 score of 95.9% on WildTrack and a MODP of 89.2% on MultiviewX, outperforming the baseline method TrackTacular. These results demonstrate that SCFusion effectively mitigates the limitations of conventional BEV projection and provides a robust and accurate solution for multi-view object detection and tracking.
Gr-IoU: Ground-Intersection over Union for Robust Multi-Object Tracking with 3D Geometric Constraints
Sep 05, 2024



We propose a Ground IoU (Gr-IoU) to address the data association problem in multi-object tracking. When tracking objects detected by a camera, it often occurs that the same object is assigned different IDs in consecutive frames, especially when objects are close to each other or overlapping. To address this issue, we introduce Gr-IoU, which takes into account the 3D structure of the scene. Gr-IoU transforms traditional bounding boxes from the image space to the ground plane using the vanishing point geometry. The IoU calculated with these transformed bounding boxes is more sensitive to the front-to-back relationships of objects, thereby improving data association accuracy and reducing ID switches. We evaluated our Gr-IoU method on the MOT17 and MOT20 datasets, which contain diverse tracking scenarios including crowded scenes and sequences with frequent occlusions. Experimental results demonstrated that Gr-IoU outperforms conventional real-time methods without appearance features.
Leveraging Temporal Joint Depths for Improving 3D Human Pose Estimation in Video
Nov 04, 2020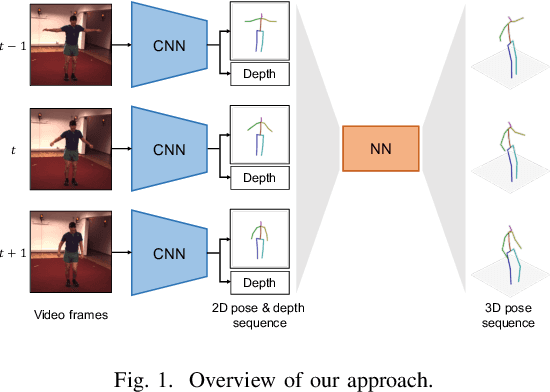

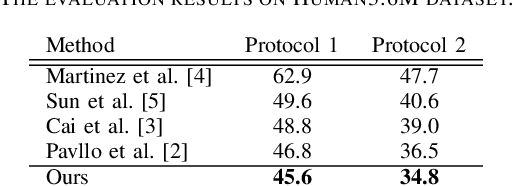
The effectiveness of the approaches to predict 3D poses from 2D poses estimated in each frame of a video has been demonstrated for 3D human pose estimation. However, 2D poses without appearance information of persons have much ambiguity with respect to the joint depths. In this paper, we propose to estimate a 3D pose in each frame of a video and refine it considering temporal information. The proposed approach reduces the ambiguity of the joint depths and improves the 3D pose estimation accuracy.
Improving Multi-Person Pose Estimation using Label Correction
Nov 08, 2018
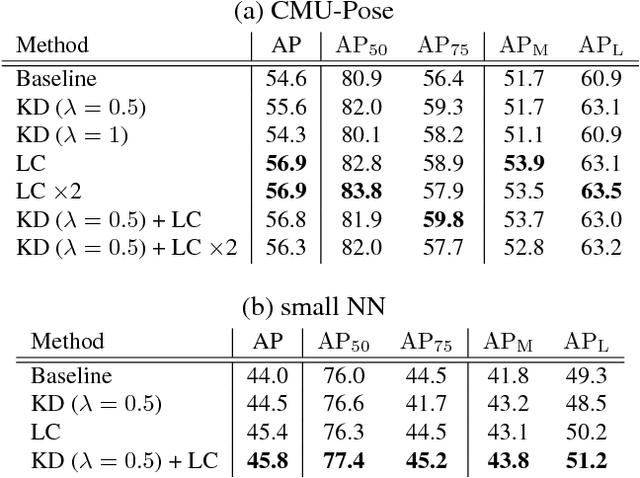

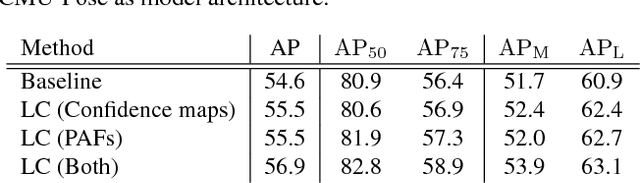
Significant attention is being paid to multi-person pose estimation methods recently, as there has been rapid progress in the field owing to convolutional neural networks. Especially, recent method which exploits part confidence maps and Part Affinity Fields (PAFs) has achieved accurate real-time prediction of multi-person keypoints. However, human annotated labels are sometimes inappropriate for learning models. For example, if there is a limb that extends outside an image, a keypoint for the limb may not have annotations because it exists outside of the image, and thus the labels for the limb can not be generated. If a model is trained with data including such missing labels, the output of the model for the location, even though it is correct, is penalized as a false positive, which is likely to cause negative effects on the performance of the model. In this paper, we point out the existence of some patterns of inappropriate labels, and propose a novel method for correcting such labels with a teacher model trained on such incomplete data. Experiments on the COCO dataset show that training with the corrected labels improves the performance of the model and also speeds up training.