 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALL-E: Hierarchical Neural Codec Language Model for Minute-Long Zero-Shot Text-to-Speech Synthesis
Paper and Code
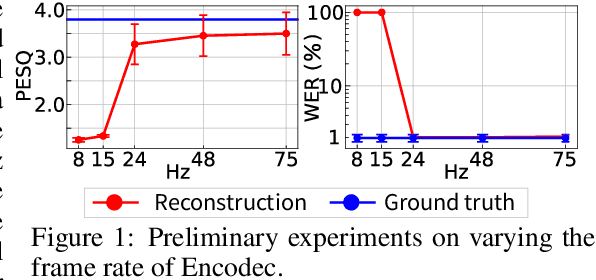

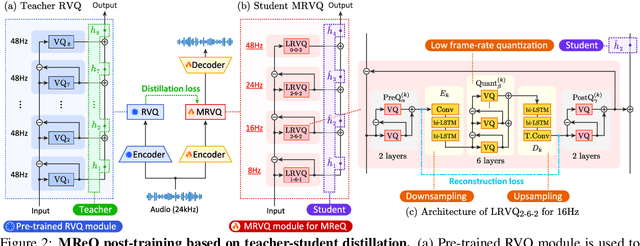
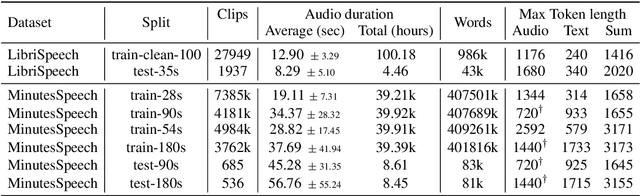
Recently, Text-to-speech (TTS) models based on large language models (LLMs) that translate natural language text into sequences of discrete audio tokens have gained great research attention, with advances in neural audio codec (NAC) models using residual vector quantization (RVQ). However, long-form speech synthesis remains a significant challenge due to the high frame rate, which increases the length of audio tokens and makes it difficult for autoregressive language models to generate audio tokens for even a minute of speech. To address this challenge, this paper introduces two novel post-training approaches: 1) Multi-Resolution Requantization (MReQ) and 2) HALL-E. MReQ is a framework to reduce the frame rate of pre-trained NAC models. Specifically, it incorporates multi-resolution residual vector quantization (MRVQ) module that hierarchically reorganizes discrete audio tokens through teacher-student distillation. HALL-E is an LLM-based TTS model designed to predict hierarchical tokens of MReQ. Specifically, it incorporates the technique of using MRVQ sub-modules and continues training from a pre-trained LLM-based TTS model. Furthermore, to promote TTS research, we create MinutesSpeech, a new benchmark dataset consisting of 40k hours of filtered speech data for training and evaluating speech synthesis ranging from 3s up to 180s. In experiments, we demonstrated the effectiveness of our approaches by applying our post-training framework to VALL-E. We achieved the frame rate down to as low as 8 Hz, enabling the stable minitue-long speech synthesis in a single inference step. Audio samples, dataset, codes and pre-trained models are available at https://yutonishimura-v2.github.io/HALL-E_DEMO/.