 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Instruction-Tuning Datasets with Contrastive Decoding
Apr 15, 2026Using responses generated by high-performing large language models (LLMs) for instruction tuning has become a widely adopted approach. However, the existing literature overlooks a property of LLM-generated responses: they conflate world knowledge acquired during pre-training with instruction-following capabilities acquired during post-training. We hypothesize that disentangling the instruction-following capabilities from pre-trained knowledge improves the effectiveness of instruction tuning. To this end, we propose CoDIT, a method that applies contrastive decoding between a post-trained model and its pre-trained counterpart during response generation. The method suppresses pre-trained knowledge shared between the two models while amplifying the instruction-following behavior acquired via post-training, resulting in responses that more purely reflect instruction-following capabilities. Experiment results demonstrate that models trained on datasets constructed via CoDIT consistently outperform those trained on directly generated responses. Training on our datasets also yields better performance than on existing publicly available instruction-tuning datasets across multiple benchmarks. Furthermore, we theoretically and empirically show that CoDIT can be interpreted as distilling the chat vector from parameter space to text space, enabling the transfer of instruction-tuning capabilities across models of different architectures.
From Correspondence to Actions: Human-Like Multi-Image Spatial Reasoning in Multi-modal Large Language Models
Feb 09, 2026While multimodal large language models (MLLMs) have made substantial progress in single-image spatial reasoning, multi-image spatial reasoning, which requires integration of information from multiple viewpoints, remains challenging. Cognitive studies suggest that humans address such tasks through two mechanisms: cross-view correspondence, which identifies regions across different views that correspond to the same physical locations, and stepwise viewpoint transformation, which composes relative viewpoint changes sequentially. However, existing studies incorporate these mechanisms only partially and often implicitly, without explicit supervision for both. We propose Human-Aware Training for Cross-view correspondence and viewpoint cHange (HATCH), a training framework with two complementary objectives: (1) Patch-Level Spatial Alignment, which encourages patch representations to align across views for spatially corresponding regions, and (2) Action-then-Answer Reasoning, which requires the model to generate explicit viewpoint transition actions before predicting the final answer. Experiments on three benchmarks demonstrate that HATCH consistently outperforms baselines of comparable size by a clear margin and achieves competitive results against much larger models, while preserving single-image reasoning capabilities.
Is Human-Like Text Liked by Humans? Multilingual Human Detection and Preference Against AI
Feb 17, 2025



Prior studies have shown that distinguishing text generated by large language models (LLMs) from human-written one is highly challenging, and often no better than random guessing. To verify the generalizability of this finding across languages and domains, we perform an extensive case study to identify the upper bound of human detection accuracy. Across 16 datasets covering 9 languages and 9 domains, 19 annotators achieved an average detection accuracy of 87.6%, thus challenging previous conclusions. We find that major gaps between human and machine text lie in concreteness, cultural nuances, and diversity. Prompting by explicitly explaining the distinctions in the prompts can partially bridge the gaps in over 50% of the cases. However, we also find that humans do not always prefer human-written text, particularly when they cannot clearly identify its source.
GenAI Content Detection Task 1: English and Multilingual Machine-Generated Text Detection: AI vs. Human
Jan 19, 2025We present the GenAI Content Detection Task~1 -- a shared task on binary machine generated text detection, conducted as a part of the GenAI workshop at COLING 2025. The task consists of two subtasks: Monolingual (English) and Multilingual. The shared task attracted many participants: 36 teams made official submissions to the Monolingual subtask during the test phase and 26 teams -- to the Multilingual. We provide a comprehensive overview of the data, a summary of the results -- including system rankings and performance scores -- detailed descriptions of the participating systems, and an in-depth analysis of submissions. https://github.com/mbzuai-nlp/COLING-2025-Workshop-on-MGT-Detection-Task1
Likelihood-based Mitigation of Evaluation Bias in Large Language Models
Mar 01, 2024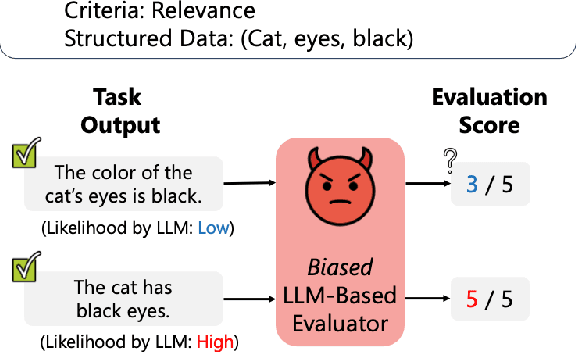
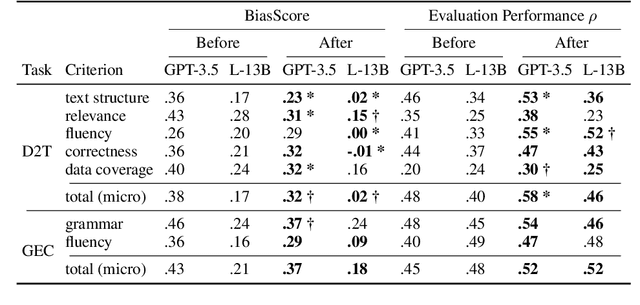
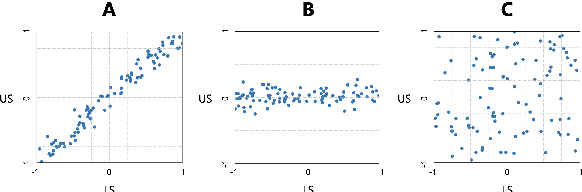
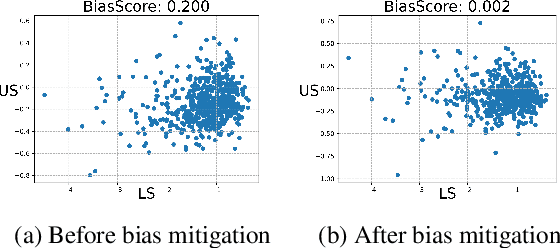
Large Language Models (LLMs) are widely used to evaluate natural language generation tasks as automated metrics. However, the likelihood, a measure of LLM's plausibility for a sentence, can vary due to superficial differences in sentences, such as word order and sentence structure. It is therefore possible that there might be a likelihood bias if LLMs are used for evaluation: they might overrate sentences with higher likelihoods while underrating those with lower likelihoods. In this paper, we investigate the presence and impact of likelihood bias in LLM-based evaluators. We also propose a method to mitigate the likelihood bias. Our method utilizes highly biased instances as few-shot examples for in-context learning. Our experiments in evaluating the data-to-text and grammatical error correction tasks reveal that several LLMs we test display a likelihood bias. Furthermore, our proposed method successfully mitigates this bias, also improving evaluation performance (in terms of correlation of models with human scores) significantly.
How You Prompt Matters! Even Task-Oriented Constraints in Instructions Affect LLM-Generated Text Detection
Nov 14, 2023Against the misuse (e.g., plagiarism or spreading misinformation) of Large Language Models (LLMs), many recent works have presented LLM-generated-text detectors with promising detection performance. Spotlighting a situation where users instruct LLMs to generate texts (e.g., essay writing), there are various ways to write the instruction (e.g., what task-oriented constraint to include). In this paper, we discover that even a task-oriented constraint in instruction can cause the inconsistent performance of current detectors to the generated texts. Specifically, we focus on student essay writing as a realistic domain and manually create the task-oriented constraint for each factor on essay quality by Ke and Ng (2019). Our experiment shows that the detection performance variance of the current detector on texts generated by instruction with each task-oriented constraint is up to 20 times larger than the variance caused by generating texts multiple times and paraphrasing the instruction. Our finding calls for further research on developing robust detectors that can detect such distributional shifts caused by a task-oriented constraint in the instruction.
OUTFOX: LLM-generated Essay Detection through In-context Learning with Adversarially Generated Examples
Jul 21, 2023Large Language Models (LLMs) have achieved human-level fluency in text generation, making it difficult to distinguish between human-written and LLM-generated texts. This poses a growing risk of misuse of LLMs and demands the development of detectors to identify LLM-generated texts. However, existing detectors degrade detection accuracy by simply paraphrasing LLM-generated texts. Furthermore, the effectiveness of these detectors in real-life situations, such as when students use LLMs for writing homework assignments (e.g., essays) and quickly learn how to evade these detectors, has not been explored. In this paper, we propose OUTFOX, a novel framework that improves the robustness of LLM-generated-text detectors by allowing both the detector and the attacker to consider each other's output and apply this to the domain of student essays. In our framework, the attacker uses the detector's prediction labels as examples for in-context learning and adversarially generates essays that are harder to detect. While the detector uses the adversarially generated essays as examples for in-context learning to learn to detect essays from a strong attacker. Our experiments show that our proposed detector learned in-context from the attacker improves the detection performance on the attacked dataset by up to +41.3 point F1-score. While our proposed attacker can drastically degrade the performance of the detector by up to -57.0 point F1-score compared to the paraphrasing method.