 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJUBAKU: An Adversarial Benchmark for Exposing Culturally Grounded Stereotypes in Japanese LLMs
Mar 21, 2026Social biases reflected in language are inherently shaped by cultural norms, which vary significantly across regions and lead to diverse manifestations of stereotypes. Existing evaluations of social bias in large language models (LLMs) for non-English contexts, however, often rely on translations of English benchmarks. Such benchmarks fail to reflect local cultural norms, including those found in Japanese. For instance, Western benchmarks may overlook Japan-specific stereotypes related to hierarchical relationships, regional dialects, or traditional gender roles. To address this limitation, we introduce Japanese cUlture adversarial BiAs benchmarK Under handcrafted creation (JUBAKU), a benchmark tailored to Japanese cultural contexts. JUBAKU uses adversarial construction to expose latent biases across ten distinct cultural categories. Unlike existing benchmarks, JUBAKU features dialogue scenarios hand-crafted by native Japanese annotators, specifically designed to trigger and reveal latent social biases in Japanese LLMs. We evaluated nine Japanese LLMs on JUBAKU and three others adapted from English benchmarks. All models clearly exhibited biases on JUBAKU, performing below the random baseline of 50% with an average accuracy of 23% (ranging from 13% to 33%), despite higher accuracy on the other benchmarks. Human annotators achieved 91% accuracy in identifying unbiased responses, confirming JUBAKU's reliability and its adversarial nature to LLMs.
JailNewsBench: Multi-Lingual and Regional Benchmark for Fake News Generation under Jailbreak Attacks
Mar 01, 2026Fake news undermines societal trust and decision-making across politics, economics, health, and international relations, and in extreme cases threatens human lives and societal safety. Because fake news reflects region-specific political, social, and cultural contexts and is expressed in language, evaluating the risks of large language models (LLMs) requires a multi-lingual and regional perspective. Malicious users can bypass safeguards through jailbreak attacks, inducing LLMs to generate fake news. However, no benchmark currently exists to systematically assess attack resilience across languages and regions. Here, we propose JailNewsBench, the first benchmark for evaluating LLM robustness against jailbreak-induced fake news generation. JailNewsBench spans 34 regions and 22 languages, covering 8 evaluation sub-metrics through LLM-as-a-Judge and 5 jailbreak attacks, with approximately 300k instances. Our evaluation of 9 LLMs reveals that the maximum attack success rate (ASR) reached 86.3% and the maximum harmfulness score was 3.5 out of 5. Notably, for English and U.S.-related topics, the defensive performance of typical multi-lingual LLMs was significantly lower than for other regions, highlighting substantial imbalances in safety across languages and regions. In addition, our analysis shows that coverage of fake news in existing safety datasets is limited and less well defended than major categories such as toxicity and social bias. Our dataset and code are available at https://github.com/kanekomasahiro/jail_news_bench.
Rectifying Belief Space via Unlearning to Harness LLMs' Reasoning
Feb 28, 2025



Large language models (LLMs) can exhibit advanced reasoning yet still generate incorrect answers. We hypothesize that such errors frequently stem from spurious beliefs, propositions the model internally considers true but are incorrect. To address this, we propose a method to rectify the belief space by suppressing these spurious beliefs while simultaneously enhancing true ones, thereby enabling more reliable inferences. Our approach first identifies the beliefs that lead to incorrect or correct answers by prompting the model to generate textual explanations, using our Forward-Backward Beam Search (FBBS). We then apply unlearning to suppress the identified spurious beliefs and enhance the true ones, effectively rectifying the model's belief space. Empirical results on multiple QA datasets and LLMs show that our method corrects previously misanswered questions without harming overall model performance. Furthermore, our approach yields improved generalization on unseen data, suggesting that rectifying a model's belief space is a promising direction for mitigating errors and enhancing overall reliability.
AmbigNLG: Addressing Task Ambiguity in Instruction for NLG
Feb 27, 2024



In this study, we introduce AmbigNLG, a new task designed to tackle the challenge of task ambiguity in instructions for Natural Language Generation (NLG) tasks. Despite the impressive capabilities of Large Language Models (LLMs) in understanding and executing a wide range of tasks through natural language interaction, their performance is significantly hindered by the ambiguity present in real-world instructions. To address this, AmbigNLG seeks to identify and mitigate such ambiguities, aiming to refine instructions to match user expectations better. We introduce a dataset, AmbigSNI-NLG, consisting of 2,500 instances, and develop an ambiguity taxonomy for categorizing and annotating instruction ambiguities. Our approach demonstrates substantial improvements in text generation quality, highlighting the critical role of clear and specific instructions in enhancing LLM performance in NLG tasks.
Nearest Neighbor Non-autoregressive Text Generation
Aug 26, 2022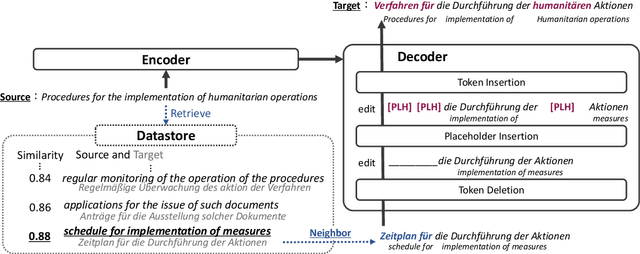
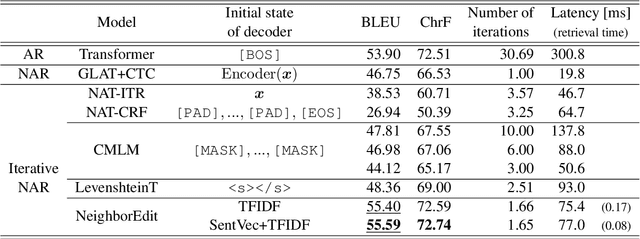

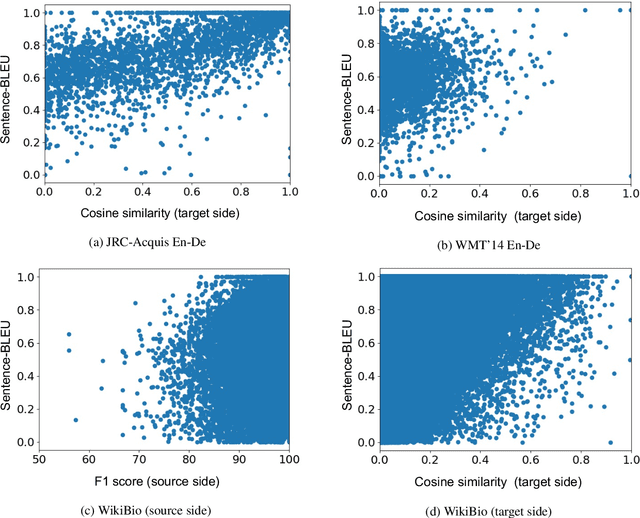
Non-autoregressive (NAR) models can generate sentences with less computation than autoregressive models but sacrifice generation quality. Previous studies addressed this issue through iterative decoding. This study proposes using nearest neighbors as the initial state of an NAR decoder and editing them iteratively. We present a novel training strategy to learn the edit operations on neighbors to improve NAR text generation. Experimental results show that the proposed method (NeighborEdit) achieves higher translation quality (1.69 points higher than the vanilla Transformer) with fewer decoding iterations (one-eighteenth fewer iterations) on the JRC-Acquis En-De dataset, the common benchmark dataset for machine translation using nearest neighbors. We also confirm the effectiveness of the proposed method on a data-to-text task (WikiBio). In addition, the proposed method outperforms an NAR baseline on the WMT'14 En-De dataset. We also report analysis on neighbor examples used in the proposed method.
Interpretability for Language Learners Using Example-Based Grammatical Error Correction
Mar 14, 2022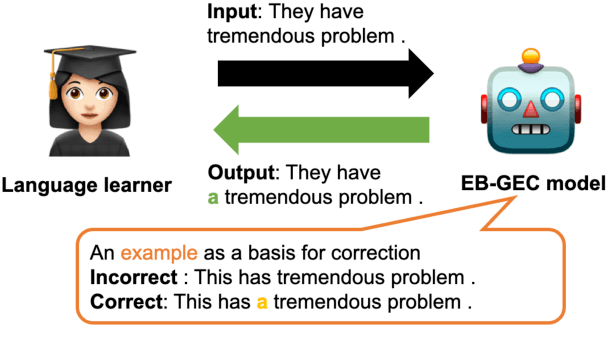

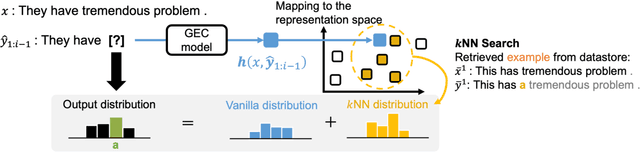
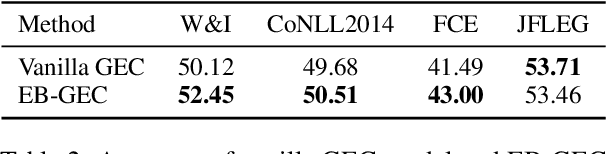
Grammatical Error Correction (GEC) should not focus only on high accuracy of corrections but also on interpretability for language learning. However, existing neural-based GEC models mainly aim at improving accuracy, and their interpretability has not been explored. A promising approach for improving interpretability is an example-based method, which uses similar retrieved examples to generate corrections. In addition, examples are beneficial in language learning, helping learners understand the basis of grammatically incorrect/correct texts and improve their confidence in writing. Therefore, we hypothesize that incorporating an example-based method into GEC can improve interpretability as well as support language learners. In this study, we introduce an Example-Based GEC (EB-GEC) that presents examples to language learners as a basis for a correction result. The examples consist of pairs of correct and incorrect sentences similar to a given input and its predicted correction. Experiments demonstrate that the examples presented by EB-GEC help language learners decide to accept or refuse suggestions from the GEC output. Furthermore, the experiments also show that retrieved examples improve the accuracy of corrections.