 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPSQL+: A Differentially Private SQL Library with a Minimum Frequency Rule
Feb 26, 2026SQL is the de facto interface for exploratory data analysis; however, releasing exact query results can expose sensitive information through membership or attribute inference attacks. Differential privacy (DP) provides rigorous privacy guarantees, but in practice, DP alone may not satisfy governance requirements such as the \emph{minimum frequency rule}, which requires each released group (cell) to include contributions from at least $k$ distinct individuals. In this paper, we present \textbf{DPSQL+}, a privacy-preserving SQL library that simultaneously enforces user-level $(\varepsilon,δ)$-DP and the minimum frequency rule. DPSQL+ adopts a modular architecture consisting of: (i) a \emph{Validator} that statically restricts queries to a DP-safe subset of SQL; (ii) an \emph{Accountant} that consistently tracks cumulative privacy loss across multiple queries; and (iii) a \emph{Backend} that interfaces with various database engines, ensuring portability and extensibility. Experiments on the TPC-H benchmark demonstrate that DPSQL+ achieves practical accuracy across a wide range of analytical workloads -- from basic aggregates to quadratic statistics and join operations -- and allows substantially more queries under a fixed global privacy budget than prior libraries in our evaluation.
Analysis of Shuffling Beyond Pure Local Differential Privacy
Jan 27, 2026Shuffling is a powerful way to amplify privacy of a local randomizer in private distributed data analysis, but existing analyses mostly treat the local differential privacy (DP) parameter $\varepsilon_0$ as the only knob and give generic upper bounds that can be loose and do not even characterize how shuffling amplifies privacy for basic mechanisms such as the Gaussian mechanism. We revisit the privacy blanket bound of Balle et al. (the blanket divergence) and develop an asymptotic analysis that applies to a broad class of local randomizers under mild regularity assumptions, without requiring pure local DP. Our key finding is that the leading term of the blanket divergence depends on the local mechanism only through a single scalar parameter $χ$, which we call the shuffle index. By applying this asymptotic analysis to both upper and lower bounds, we obtain a tight band for $δ_n$ in the shuffled mechanism's $(\varepsilon_n,δ_n)$-DP guarantee. Moreover, we derive a simple structural necessary and sufficient condition on the local randomizer under which the blanket-divergence-based upper and lower bounds coincide asymptotically. $k$-RR families with $k\ge3$ satisfy this condition, while for generalized Gaussian mechanisms the condition may not hold but the resulting band remains tight. Finally, we complement the asymptotic theory with an FFT-based algorithm for computing the blanket divergence at finite $n$, which offers rigorously controlled relative error and near-linear running time in $n$, providing a practical numerical analysis for shuffle DP.
Securing Private Federated Learning in a Malicious Setting: A Scalable TEE-Based Approach with Client Auditing
Sep 10, 2025In cross-device private federated learning, differentially private follow-the-regularized-leader (DP-FTRL) has emerged as a promising privacy-preserving method. However, existing approaches assume a semi-honest server and have not addressed the challenge of securely removing this assumption. This is due to its statefulness, which becomes particularly problematic in practical settings where clients can drop out or be corrupted. While trusted execution environments (TEEs) might seem like an obvious solution, a straightforward implementation can introduce forking attacks or availability issues due to state management. To address this problem, our paper introduces a novel server extension that acts as a trusted computing base (TCB) to realize maliciously secure DP-FTRL. The TCB is implemented with an ephemeral TEE module on the server side to produce verifiable proofs of server actions. Some clients, upon being selected, participate in auditing these proofs with small additional communication and computational demands. This extension solution reduces the size of the TCB while maintaining the system's scalability and liveness. We provide formal proofs based on interactive differential privacy, demonstrating privacy guarantee in malicious settings. Finally, we experimentally show that our framework adds small constant overhead to clients in several realistic settings.
HRNet: Differentially Private Hierarchical and Multi-Resolution Network for Human Mobility Data Synthesization
May 13, 2024


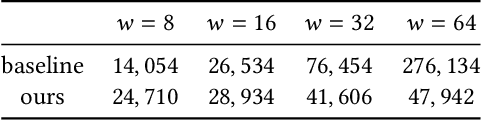
Human mobility data offers valuable insights for many applications such as urban planning and pandemic response, but its use also raises privacy concerns. In this paper, we introduce the Hierarchical and Multi-Resolution Network (HRNet), a novel deep generative model specifically designed to synthesize realistic human mobility data while guaranteeing differential privacy. We first identify the key difficulties inherent in learning human mobility data under differential privacy. In response to these challenges, HRNet integrates three components: a hierarchical location encoding mechanism, multi-task learning across multiple resolutions, and private pre-training. These elements collectively enhance the model's ability under the constraints of differential privacy. Through extensive comparative experiments utilizing a real-world dataset, HRNet demonstrates a marked improvement over existing methods in balancing the utility-privacy trade-off.
ULDP-FL: Federated Learning with Across Silo User-Level Differential Privacy
Aug 23, 2023



Differentially Private Federated Learning (DP-FL) has garnered attention as a collaborative machine learning approach that ensures formal privacy. Most DP-FL approaches ensure DP at the record-level within each silo for cross-silo FL. However, a single user's data may extend across multiple silos, and the desired user-level DP guarantee for such a setting remains unknown. In this study, we present ULDP-FL, a novel FL framework designed to guarantee user-level DP in cross-silo FL where a single user's data may belong to multiple silos. Our proposed algorithm directly ensures user-level DP through per-user weighted clipping, departing from group-privacy approaches. We provide a theoretical analysis of the algorithm's privacy and utility. Additionally, we enhance the algorithm's utility and showcase its private implementation using cryptographic building blocks. Empirical experiments on real-world datasets show substantial improvements in our methods in privacy-utility trade-offs under user-level DP compared to baseline methods. To the best of our knowledge, our work is the first FL framework that effectively provides user-level DP in the general cross-silo FL setting.
Network Shuffling: Privacy Amplification via Random Walks
Apr 08, 2022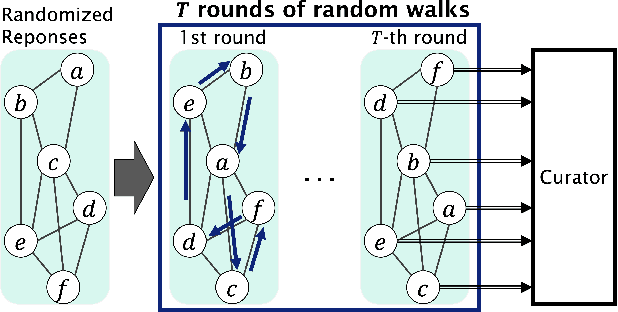

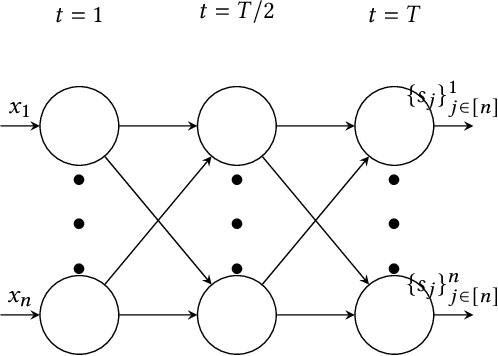
Recently, it is shown that shuffling can amplify the central differential privacy guarantees of data randomized with local differential privacy. Within this setup, a centralized, trusted shuffler is responsible for shuffling by keeping the identities of data anonymous, which subsequently leads to stronger privacy guarantees for systems. However, introducing a centralized entity to the originally local privacy model loses some appeals of not having any centralized entity as in local differential privacy. Moreover, implementing a shuffler in a reliable way is not trivial due to known security issues and/or requirements of advanced hardware or secure computation technology. Motivated by these practical considerations, we rethink the shuffle model to relax the assumption of requiring a centralized, trusted shuffler. We introduce network shuffling, a decentralized mechanism where users exchange data in a random-walk fashion on a network/graph, as an alternative of achieving privacy amplification via anonymity. We analyze the threat model under such a setting, and propose distributed protocols of network shuffling that is straightforward to implement in practice. Furthermore, we show that the privacy amplification rate is similar to other privacy amplification techniques such as uniform shuffling. To our best knowledge, among the recently studied intermediate trust models that leverage privacy amplification techniques, our work is the first that is not relying on any centralized entity to achieve privacy amplification.
P3GM: Private High-Dimensional Data Release via Privacy Preserving Phased Generative Model
Jun 22, 2020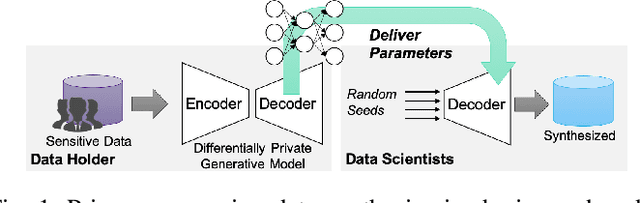

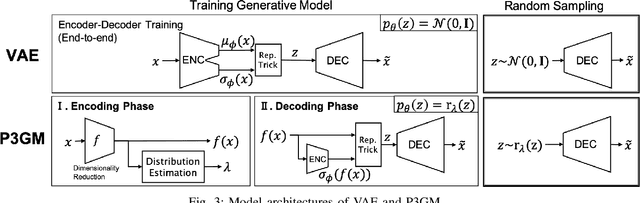
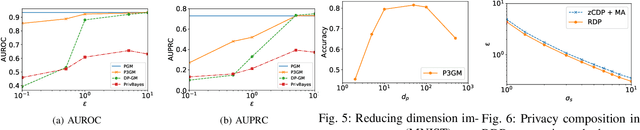
How can we release a massive volume of sensitive data while mitigating privacy risks? Privacy-preserving data synthesis enables the data holder to outsource analytical tasks to an untrusted third party. The state-of-the-art approach for this problem is to build a generative model under differential privacy, which offers a rigorous privacy guarantee. However, the existing method cannot adequately handle high dimensional data. In particular, when the input dataset contains a large number of features, the existing techniques require injecting a prohibitive amount of noise to satisfy differential privacy, which results in the outsourced data analysis meaningless. To address the above issue, this paper proposes privacy-preserving phased generative model (P3GM), which is a differentially private generative model for releasing such sensitive data. P3GM employs the two-phase learning process to make it robust against the noise, and to increase learning efficiency (e.g., easy to converge). We give theoretical analyses about the learning complexity and privacy loss in P3GM. We further experimentally evaluate our proposed method and demonstrate that P3GM significantly outperforms existing solutions. Compared with the state-of-the-art methods, our generated samples look fewer noises and closer to the original data in terms of data diversity. Besides, in several data mining tasks with synthesized data, our model outperforms the competitors in terms of accuracy.
Differentially Private Variational Autoencoders with Term-wise Gradient Aggregation
Jun 19, 2020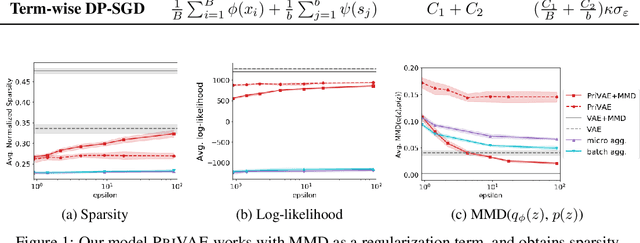
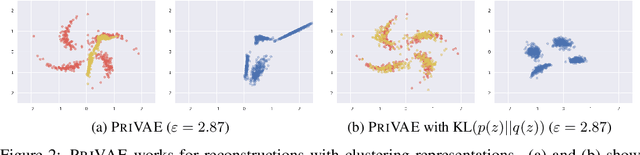
This paper studies how to learn variational autoencoders with a variety of divergences under differential privacy constraints. We often build a VAE with an appropriate prior distribution to describe the desired properties of the learned representations and introduce a divergence as a regularization term to close the representations to the prior. Using differentially private SGD (DP-SGD), which randomizes a stochastic gradient by injecting a dedicated noise designed according to the gradient's sensitivity, we can easily build a differentially private model. However, we reveal that attaching several divergences increase the sensitivity from O(1) to O(B) in terms of batch size B. That results in injecting a vast amount of noise that makes it hard to learn. To solve the above issue, we propose term-wise DP-SGD that crafts randomized gradients in two different ways tailored to the compositions of the loss terms. The term-wise DP-SGD keeps the sensitivity at O(1) even when attaching the divergence. We can therefore reduce the amount of noise. In our experiments, we demonstrate that our method works well with two pairs of the prior distribution and the divergence.