 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-bit Submission for Locally Private Quasi-MLE: Its Asymptotic Normality and Limitation
Feb 15, 2022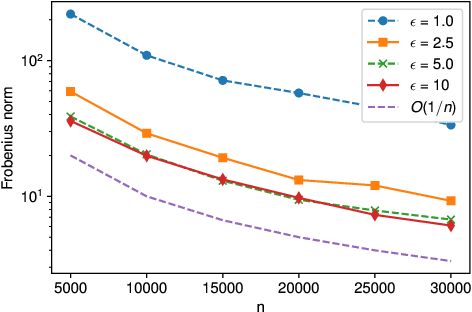
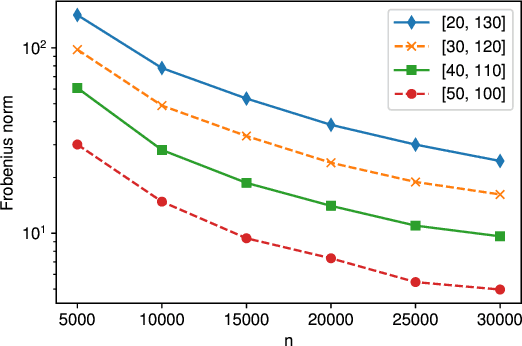
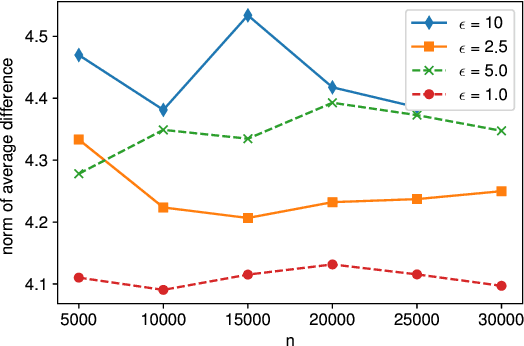
Local differential privacy~(LDP) is an information-theoretic privacy definition suitable for statistical surveys that involve an untrusted data curator. An LDP version of quasi-maximum likelihood estimator~(QMLE) has been developed, but the existing method to build LDP QMLE is difficult to implement for a large-scale survey system in the real world due to long waiting time, expensive communication cost, and the boundedness assumption of derivative of a log-likelihood function. We provided an alternative LDP protocol without those issues, which is potentially much easily deployable to a large-scale survey. We also provided sufficient conditions for the consistency and asymptotic normality and limitations of our protocol. Our protocol is less burdensome for the users, and the theoretical guarantees cover more realistic cases than those for the existing method.
Differentially Private Variational Autoencoders with Term-wise Gradient Aggregation
Jun 19, 2020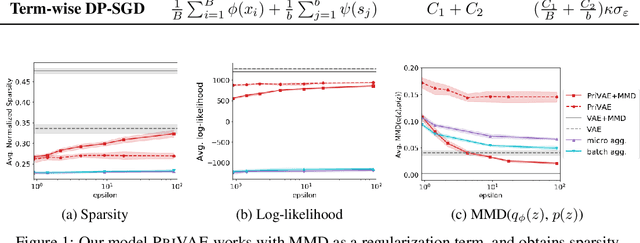
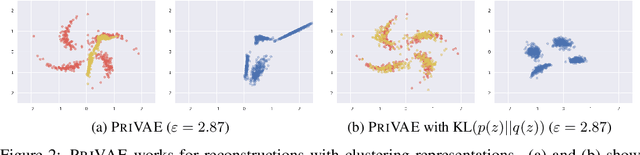
This paper studies how to learn variational autoencoders with a variety of divergences under differential privacy constraints. We often build a VAE with an appropriate prior distribution to describe the desired properties of the learned representations and introduce a divergence as a regularization term to close the representations to the prior. Using differentially private SGD (DP-SGD), which randomizes a stochastic gradient by injecting a dedicated noise designed according to the gradient's sensitivity, we can easily build a differentially private model. However, we reveal that attaching several divergences increase the sensitivity from O(1) to O(B) in terms of batch size B. That results in injecting a vast amount of noise that makes it hard to learn. To solve the above issue, we propose term-wise DP-SGD that crafts randomized gradients in two different ways tailored to the compositions of the loss terms. The term-wise DP-SGD keeps the sensitivity at O(1) even when attaching the divergence. We can therefore reduce the amount of noise. In our experiments, we demonstrate that our method works well with two pairs of the prior distribution and the divergence.
Locally Private Distributed Reinforcement Learning
Jan 31, 2020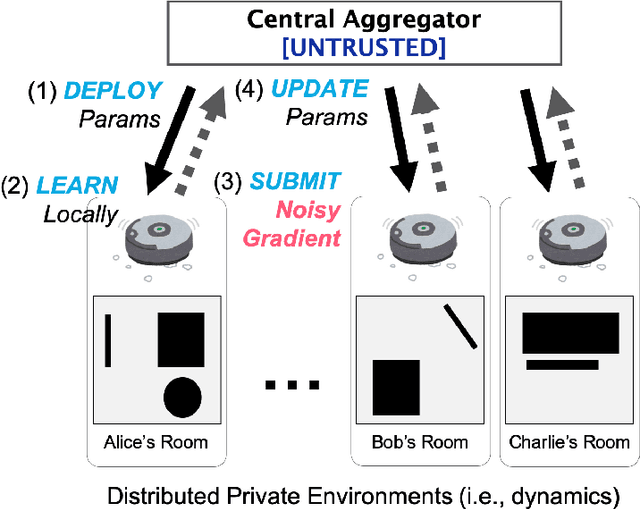
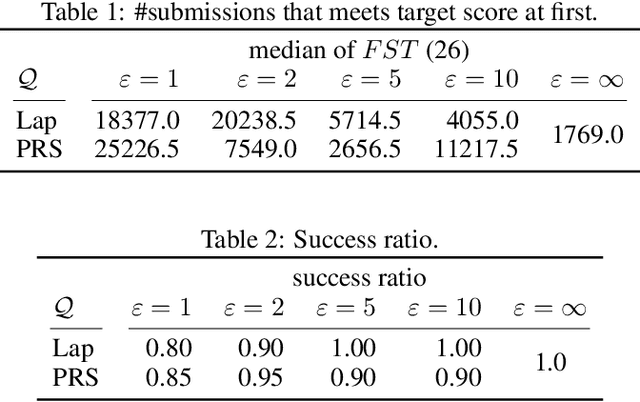

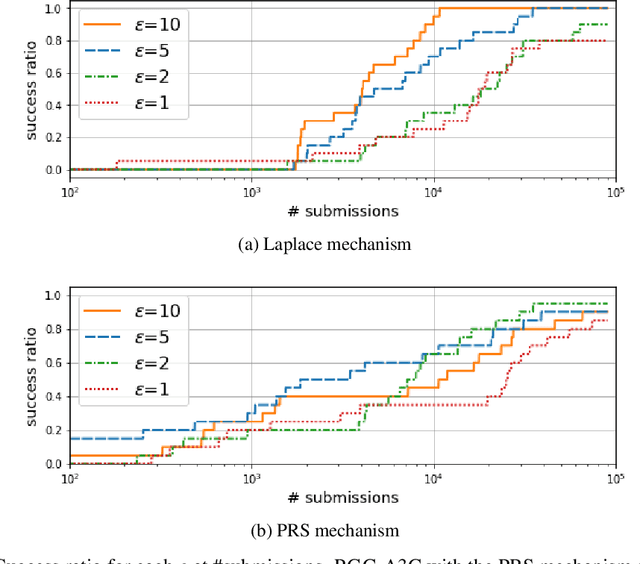
We study locally differentially private algorithms for reinforcement learning to obtain a robust policy that performs well across distributed private environments. Our algorithm protects the information of local agents' models from being exploited by adversarial reverse engineering. Since a local policy is strongly being affected by the individual environment, the output of the agent may release the private information unconsciously. In our proposed algorithm, local agents update the model in their environments and report noisy gradients designed to satisfy local differential privacy (LDP) that gives a rigorous local privacy guarantee. By utilizing a set of reported noisy gradients, a central aggregator updates its model and delivers it to different local agents. In our empirical evaluation, we demonstrate how our method performs well under LDP. To the best of our knowledge, this is the first work that actualizes distributed reinforcement learning under LDP. This work enables us to obtain a robust agent that performs well across distributed private environments.
Lightweight Lipschitz Margin Training for Certified Defense against Adversarial Examples
Nov 20, 2018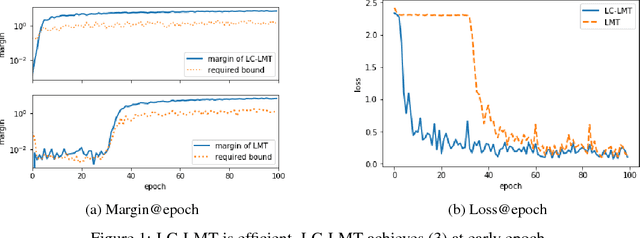
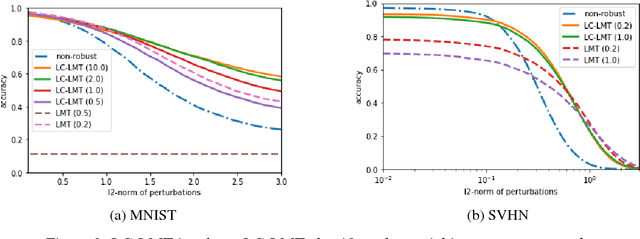
How can we make machine learning provably robust against adversarial examples in a scalable way? Since certified defense methods, which ensure $\epsilon$-robust, consume huge resources, they can only achieve small degree of robustness in practice. Lipschitz margin training (LMT) is a scalable certified defense, but it can also only achieve small robustness due to over-regularization. How can we make certified defense more efficiently? We present LC-LMT, a light weight Lipschitz margin training which solves the above problem. Our method has the following properties; (a) efficient: it can achieve $\epsilon$-robustness at early epoch, and (b) robust: it has a potential to get higher robustness than LMT. In the evaluation, we demonstrate the benefits of the proposed method. LC-LMT can achieve required robustness more than 30 epoch earlier than LMT in MNIST, and shows more than 90 $\%$ accuracy against both legitimate and adversarial inputs.