 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocally Private Distributed Reinforcement Learning
Paper and Code
Jan 31, 2020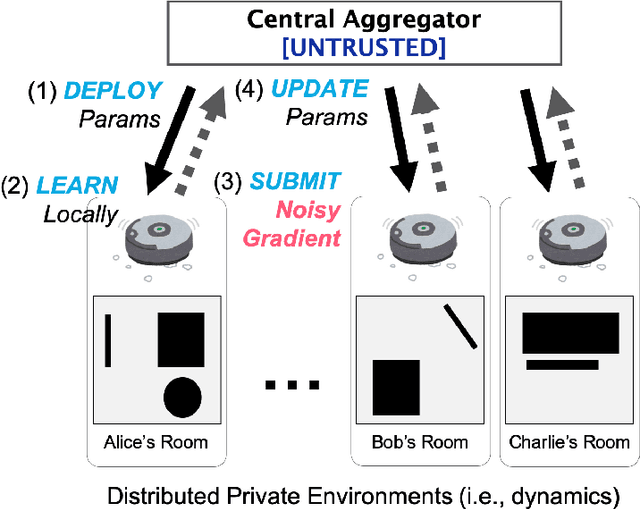
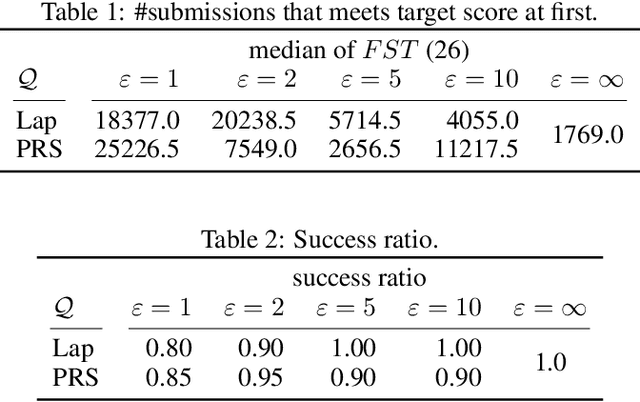

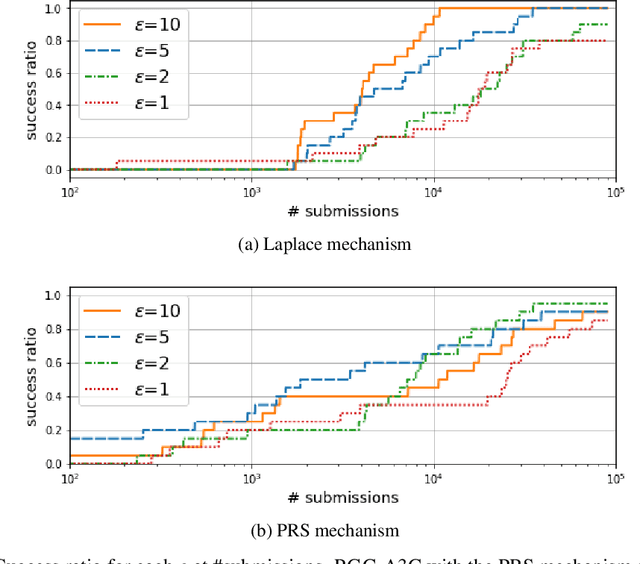
We study locally differentially private algorithms for reinforcement learning to obtain a robust policy that performs well across distributed private environments. Our algorithm protects the information of local agents' models from being exploited by adversarial reverse engineering. Since a local policy is strongly being affected by the individual environment, the output of the agent may release the private information unconsciously. In our proposed algorithm, local agents update the model in their environments and report noisy gradients designed to satisfy local differential privacy (LDP) that gives a rigorous local privacy guarantee. By utilizing a set of reported noisy gradients, a central aggregator updates its model and delivers it to different local agents. In our empirical evaluation, we demonstrate how our method performs well under LDP. To the best of our knowledge, this is the first work that actualizes distributed reinforcement learning under LDP. This work enables us to obtain a robust agent that performs well across distributed private environments.