 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Spatiotemporal Data from Gradients with Large Language Models
Oct 21, 2024



Recent works show that sensitive user data can be reconstructed from gradient updates, breaking the key privacy promise of federated learning. While success was demonstrated primarily on image data, these methods do not directly transfer to other domains, such as spatiotemporal data. To understand privacy risks in spatiotemporal federated learning, we first propose Spatiotemporal Gradient Inversion Attack (ST-GIA), a gradient attack algorithm tailored to spatiotemporal data that successfully reconstructs the original location from gradients. Furthermore, the absence of priors in attacks on spatiotemporal data has hindered the accurate reconstruction of real client data. To address this limitation, we propose ST-GIA+, which utilizes an auxiliary language model to guide the search for potential locations, thereby successfully reconstructing the original data from gradients. In addition, we design an adaptive defense strategy to mitigate gradient inversion attacks in spatiotemporal federated learning. By dynamically adjusting the perturbation levels, we can offer tailored protection for varying rounds of training data, thereby achieving a better trade-off between privacy and utility than current state-of-the-art methods. Through intensive experimental analysis on three real-world datasets, we reveal that the proposed defense strategy can well preserve the utility of spatiotemporal federated learning with effective security protection.
HRNet: Differentially Private Hierarchical and Multi-Resolution Network for Human Mobility Data Synthesization
May 13, 2024


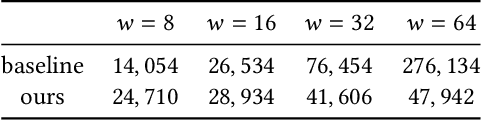
Human mobility data offers valuable insights for many applications such as urban planning and pandemic response, but its use also raises privacy concerns. In this paper, we introduce the Hierarchical and Multi-Resolution Network (HRNet), a novel deep generative model specifically designed to synthesize realistic human mobility data while guaranteeing differential privacy. We first identify the key difficulties inherent in learning human mobility data under differential privacy. In response to these challenges, HRNet integrates three components: a hierarchical location encoding mechanism, multi-task learning across multiple resolutions, and private pre-training. These elements collectively enhance the model's ability under the constraints of differential privacy. Through extensive comparative experiments utilizing a real-world dataset, HRNet demonstrates a marked improvement over existing methods in balancing the utility-privacy trade-off.
ULDP-FL: Federated Learning with Across Silo User-Level Differential Privacy
Aug 23, 2023



Differentially Private Federated Learning (DP-FL) has garnered attention as a collaborative machine learning approach that ensures formal privacy. Most DP-FL approaches ensure DP at the record-level within each silo for cross-silo FL. However, a single user's data may extend across multiple silos, and the desired user-level DP guarantee for such a setting remains unknown. In this study, we present ULDP-FL, a novel FL framework designed to guarantee user-level DP in cross-silo FL where a single user's data may belong to multiple silos. Our proposed algorithm directly ensures user-level DP through per-user weighted clipping, departing from group-privacy approaches. We provide a theoretical analysis of the algorithm's privacy and utility. Additionally, we enhance the algorithm's utility and showcase its private implementation using cryptographic building blocks. Empirical experiments on real-world datasets show substantial improvements in our methods in privacy-utility trade-offs under user-level DP compared to baseline methods. To the best of our knowledge, our work is the first FL framework that effectively provides user-level DP in the general cross-silo FL setting.
Local Differential Privacy Image Generation Using Flow-based Deep Generative Models
Dec 20, 2022



Diagnostic radiologists need artificial intelligence (AI) for medical imaging, but access to medical images required for training in AI has become increasingly restrictive. To release and use medical images, we need an algorithm that can simultaneously protect privacy and preserve pathologies in medical images. To develop such an algorithm, here, we propose DP-GLOW, a hybrid of a local differential privacy (LDP) algorithm and one of the flow-based deep generative models (GLOW). By applying a GLOW model, we disentangle the pixelwise correlation of images, which makes it difficult to protect privacy with straightforward LDP algorithms for images. Specifically, we map images onto the latent vector of the GLOW model, each element of which follows an independent normal distribution, and we apply the Laplace mechanism to the latent vector. Moreover, we applied DP-GLOW to chest X-ray images to generate LDP images while preserving pathologies.
TimeBERT: Enhancing Pre-Trained Language Representations with Temporal Information
Apr 27, 2022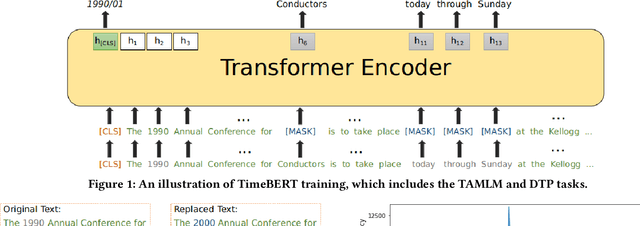

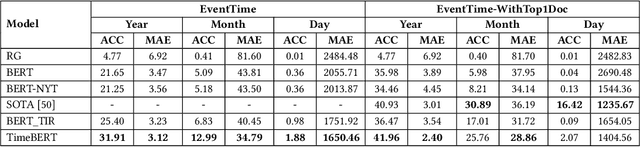
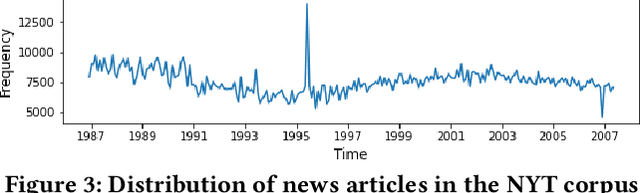
Time is an important aspect of text documents, which has been widely exploited in natural language processing and has strong influence, for example, in temporal information retrieval, where the temporal information of queries or documents need to be identified for relevance estimation. Event-related tasks like event ordering, which aims to order events by their occurrence time, also need to determine the temporal information of events. In this work, we investigate methods for incorporating temporal information during pre-training, to further improve the performance on time-related tasks. Compared with BERT which utilizes synchronic document collections (BooksCorpus and English Wikipedia) as the training corpora, we use long-span temporal news collection for building word representations, since temporal information constitutes one of the most significant features of news articles. We then introduce TimeBERT, a novel language representation model trained on a temporal collection of news articles via two new pre-training tasks, which harness two distinct temporal signals to construct time-aware language representation. The experimental results show that TimeBERT consistently outperforms BERT and other existing pre-trained models, with substantial gains on different downstream NLP tasks or applications for which time is of importance.
Network Shuffling: Privacy Amplification via Random Walks
Apr 08, 2022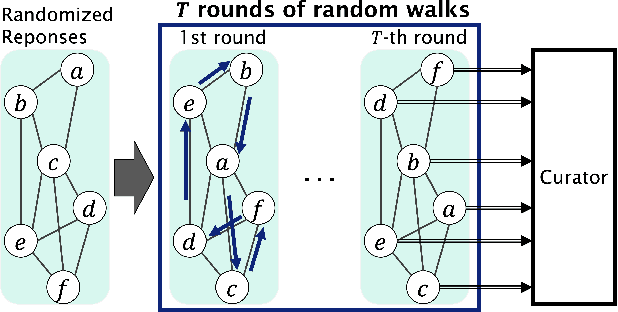

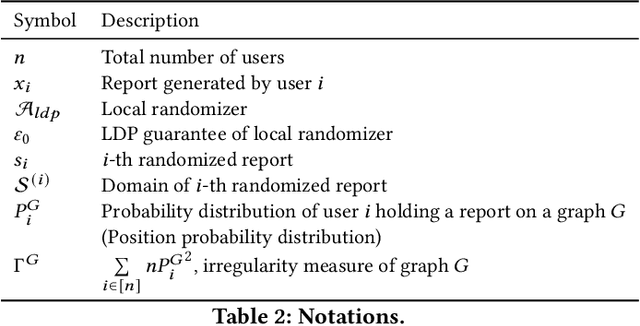
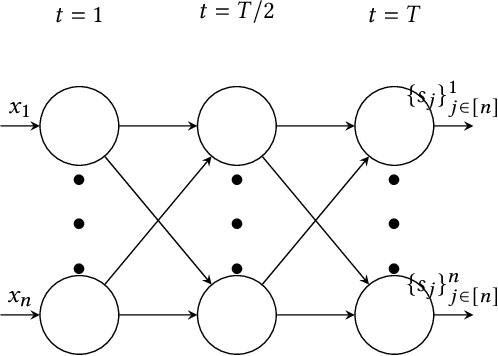
Recently, it is shown that shuffling can amplify the central differential privacy guarantees of data randomized with local differential privacy. Within this setup, a centralized, trusted shuffler is responsible for shuffling by keeping the identities of data anonymous, which subsequently leads to stronger privacy guarantees for systems. However, introducing a centralized entity to the originally local privacy model loses some appeals of not having any centralized entity as in local differential privacy. Moreover, implementing a shuffler in a reliable way is not trivial due to known security issues and/or requirements of advanced hardware or secure computation technology. Motivated by these practical considerations, we rethink the shuffle model to relax the assumption of requiring a centralized, trusted shuffler. We introduce network shuffling, a decentralized mechanism where users exchange data in a random-walk fashion on a network/graph, as an alternative of achieving privacy amplification via anonymity. We analyze the threat model under such a setting, and propose distributed protocols of network shuffling that is straightforward to implement in practice. Furthermore, we show that the privacy amplification rate is similar to other privacy amplification techniques such as uniform shuffling. To our best knowledge, among the recently studied intermediate trust models that leverage privacy amplification techniques, our work is the first that is not relying on any centralized entity to achieve privacy amplification.
OLIVE: Oblivious and Differentially Private Federated Learning on Trusted Execution Environment
Feb 16, 2022Differentially private federated learning (DP-FL) has received increasing attention to mitigate the privacy risk in federated learning. Although different schemes for DP-FL have been proposed, there is still a utility gap. Employing central Differential Privacy in FL (CDP-FL) can provide a good balance between the privacy and model utility, but requires a trusted server. Using Local Differential Privacy for FL (LDP-FL) does not require a trusted server, but suffers from lousy privacy-utility trade-off. Recently proposed shuffle DP based FL has the potential to bridge the gap between CDP-FL and LDP-FL without a trusted server; however, there is still a utility gap when the number of model parameters is large. In this work, we propose OLIVE, a system that combines the merits from CDP-FL and LDP-FL by leveraging Trusted Execution Environment (TEE). Our main technical contributions are the analysis and countermeasures against the vulnerability of TEE in OLIVE. Firstly, we theoretically analyze the memory access pattern leakage of OLIVE and find that there is a risk for sparsified gradients, which is common in FL. Secondly, we design an inference attack to understand how the memory access pattern could be linked to the training data. Thirdly, we propose oblivious yet efficient algorithms to prevent the memory access pattern leakage in OLIVE. Our experiments on real-world data demonstrate that OLIVE is efficient even when training a model with hundreds of thousands of parameters and effective against side-channel attacks on TEE.
ArchivalQA: A Large-scale Benchmark Dataset for Open Domain Question Answering over Archival News Collections
Sep 09, 2021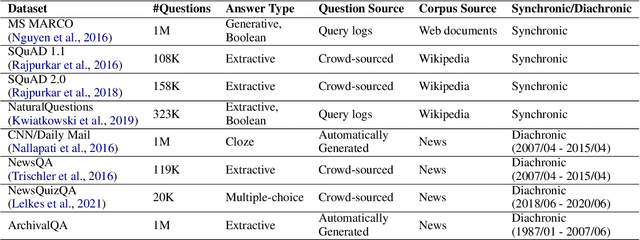
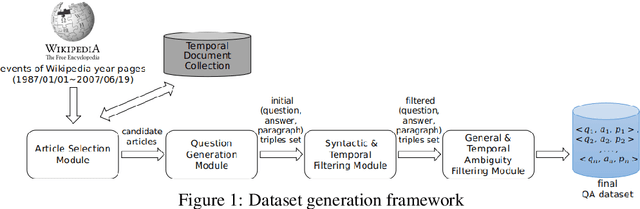

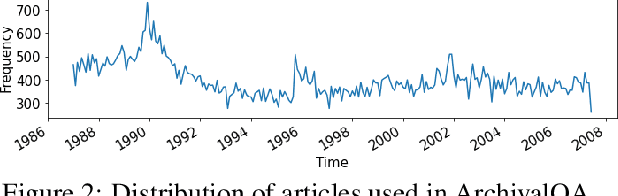
In the last few years, open-domain question answering (ODQA) has advanced rapidly due to the development of deep learning techniques and the availability of large-scale QA datasets. However, the current datasets are essentially designed for synchronic document collections (e.g., Wikipedia). Temporal news collections such as long-term news archives spanning several decades, are rarely used in training the models despite they are quite valuable for our society. In order to foster the research in the field of ODQA on such historical collections, we present ArchivalQA, a large question answering dataset consisting of 1,067,056 question-answer pairs which is designed for temporal news QA. In addition, we create four subparts of our dataset based on the question difficulty levels and the containment of temporal expressions, which we believe could be useful for training or testing ODQA systems characterized by different strengths and abilities. The novel QA dataset-constructing framework that we introduce can be also applied to create datasets over other types of collections.
Understanding the Interplay between Privacy and Robustness in Federated Learning
Jun 13, 2021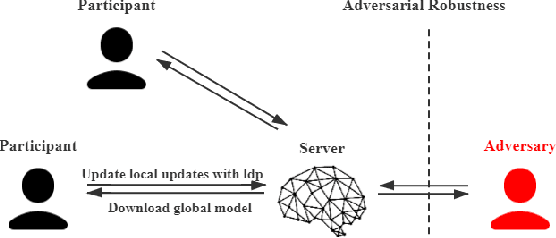
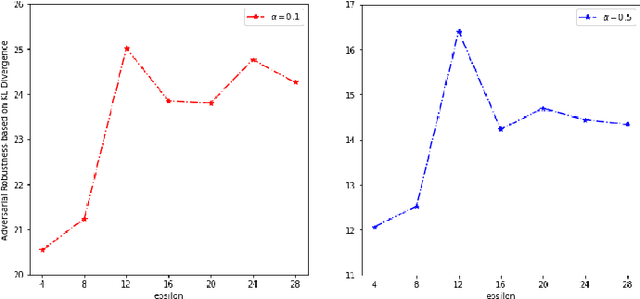
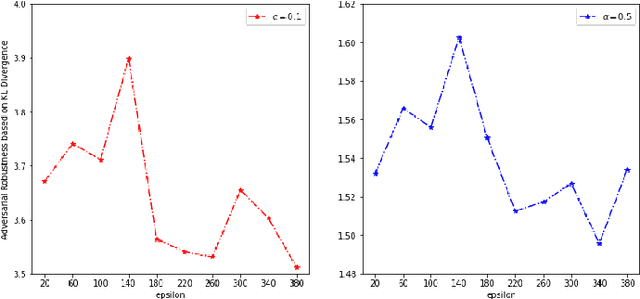
Federated Learning (FL) is emerging as a promising paradigm of privacy-preserving machine learning, which trains an algorithm across multiple clients without exchanging their data samples. Recent works highlighted several privacy and robustness weaknesses in FL and addressed these concerns using local differential privacy (LDP) and some well-studied methods used in conventional ML, separately. However, it is still not clear how LDP affects adversarial robustness in FL. To fill this gap, this work attempts to develop a comprehensive understanding of the effects of LDP on adversarial robustness in FL. Clarifying the interplay is significant since this is the first step towards a principled design of private and robust FL systems. We certify that local differential privacy has both positive and negative effects on adversarial robustness using theoretical analysis and empirical verification.
Incentive Mechanism for Privacy-Preserving Federated Learning
Jun 08, 2021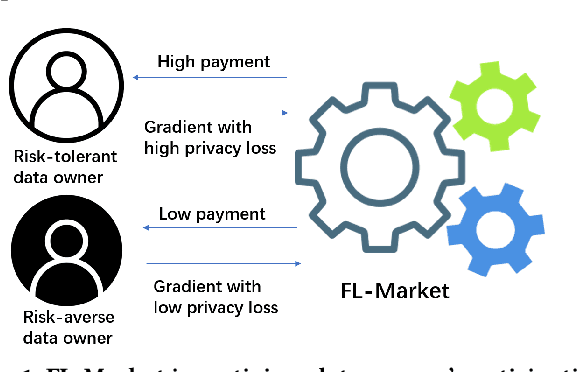
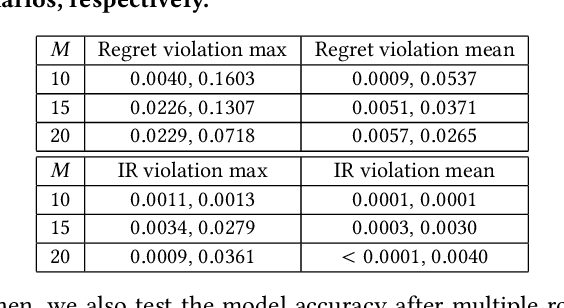
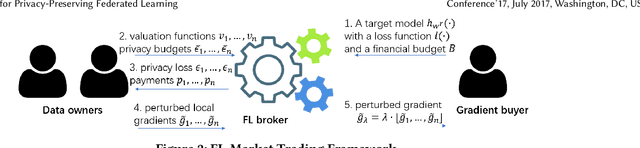
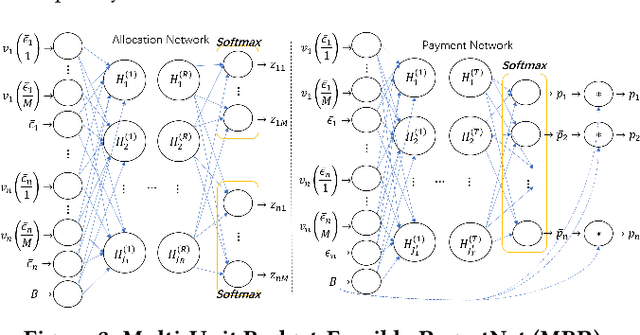
Federated learning (FL) is an emerging paradigm for machine learning, in which data owners can collaboratively train a model by sharing gradients instead of their raw data. Two fundamental research problems in FL are incentive mechanism and privacy protection. The former focuses on how to incentivize data owners to participate in FL. The latter studies how to protect data owners' privacy while maintaining high utility of trained models. However, incentive mechanism and privacy protection in FL have been studied separately and no work solves both problems at the same time. In this work, we address the two problems simultaneously by an FL-Market that incentivizes data owners' participation by providing appropriate payments and privacy protection. FL-Market enables data owners to obtain compensation according to their privacy loss quantified by local differential privacy (LDP). Our insight is that, by meeting data owners' personalized privacy preferences and providing appropriate payments, we can (1) incentivize privacy risk-tolerant data owners to set larger privacy parameters (i.e., gradients with less noise) and (2) provide preferred privacy protection for privacy risk-averse data owners. To achieve this, we design a personalized LDP-based FL framework with a deep learning-empowered auction mechanism for incentivizing trading gradients with less noise and optimal aggregation mechanisms for model updates. Our experiments verify the effectiveness of the proposed framework and mechanisms.