 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeBERT: Enhancing Pre-Trained Language Representations with Temporal Information
Paper and Code
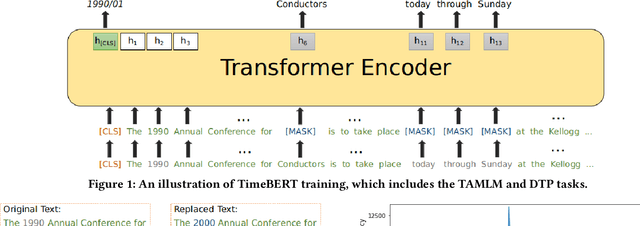

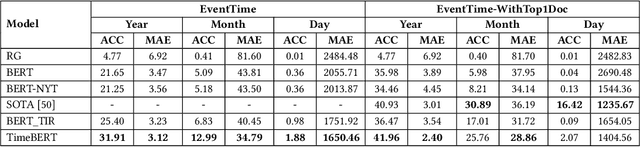
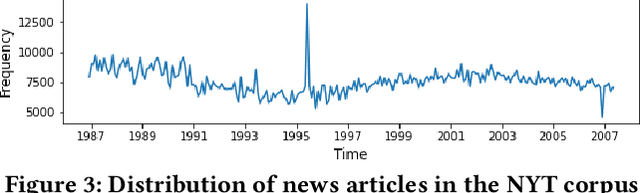
Time is an important aspect of text documents, which has been widely exploited in natural language processing and has strong influence, for example, in temporal information retrieval, where the temporal information of queries or documents need to be identified for relevance estimation. Event-related tasks like event ordering, which aims to order events by their occurrence time, also need to determine the temporal information of events. In this work, we investigate methods for incorporating temporal information during pre-training, to further improve the performance on time-related tasks. Compared with BERT which utilizes synchronic document collections (BooksCorpus and English Wikipedia) as the training corpora, we use long-span temporal news collection for building word representations, since temporal information constitutes one of the most significant features of news articles. We then introduce TimeBERT, a novel language representation model trained on a temporal collection of news articles via two new pre-training tasks, which harness two distinct temporal signals to construct time-aware language representation. The experimental results show that TimeBERT consistently outperforms BERT and other existing pre-trained models, with substantial gains on different downstream NLP tasks or applications for which time is of importance.