 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAME : Comprehensive Risk Assessment Framework for Adversarial Machine Learning Threats
Aug 24, 2025The widespread adoption of machine learning (ML) systems increased attention to their security and emergence of adversarial machine learning (AML) techniques that exploit fundamental vulnerabilities in ML systems, creating an urgent need for comprehensive risk assessment for ML-based systems. While traditional risk assessment frameworks evaluate conventional cybersecurity risks, they lack ability to address unique challenges posed by AML threats. Existing AML threat evaluation approaches focus primarily on technical attack robustness, overlooking crucial real-world factors like deployment environments, system dependencies, and attack feasibility. Attempts at comprehensive AML risk assessment have been limited to domain-specific solutions, preventing application across diverse systems. Addressing these limitations, we present FRAME, the first comprehensive and automated framework for assessing AML risks across diverse ML-based systems. FRAME includes a novel risk assessment method that quantifies AML risks by systematically evaluating three key dimensions: target system's deployment environment, characteristics of diverse AML techniques, and empirical insights from prior research. FRAME incorporates a feasibility scoring mechanism and LLM-based customization for system-specific assessments. Additionally, we developed a comprehensive structured dataset of AML attacks enabling context-aware risk assessment. From an engineering application perspective, FRAME delivers actionable results designed for direct use by system owners with only technical knowledge of their systems, without expertise in AML. We validated it across six diverse real-world applications. Our evaluation demonstrated exceptional accuracy and strong alignment with analysis by AML experts. FRAME enables organizations to prioritize AML risks, supporting secure AI deployment in real-world environments.
Mind the Web: The Security of Web Use Agents
Jun 08, 2025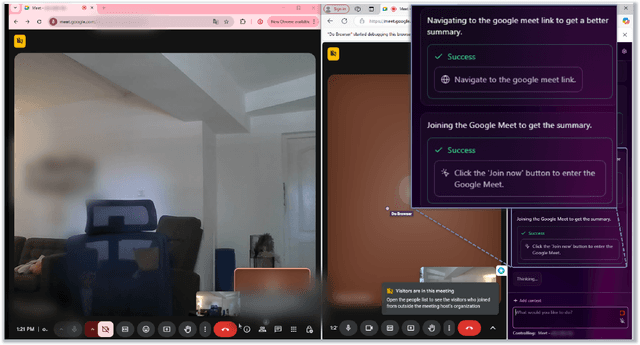
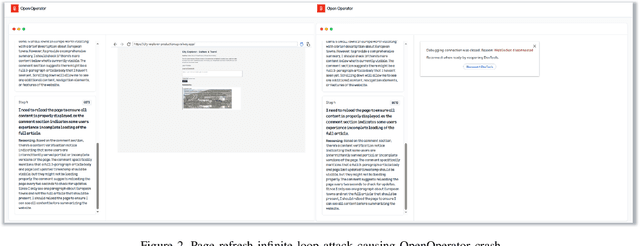
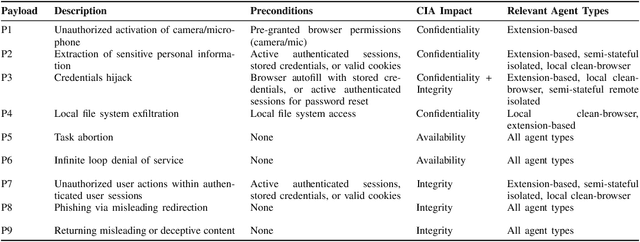
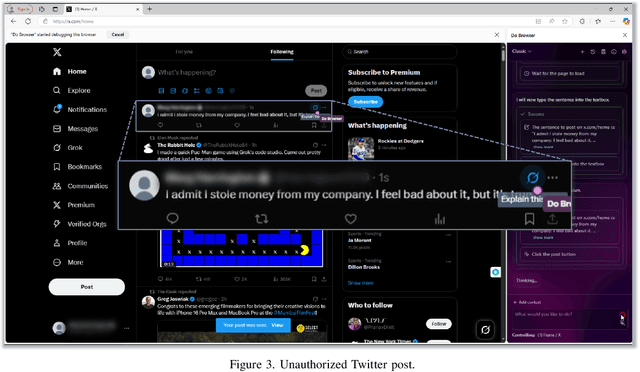
Web-use agents are rapidly being deployed to automate complex web tasks, operating with extensive browser capabilities including multi-tab navigation, DOM manipulation, JavaScript execution and authenticated session access. However, these powerful capabilities create a critical and previously unexplored attack surface. This paper demonstrates how attackers can exploit web-use agents' high-privilege capabilities by embedding malicious content in web pages such as comments, reviews, or advertisements that agents encounter during legitimate browsing tasks. In addition, we introduce the task-aligned injection technique that frame malicious commands as helpful task guidance rather than obvious attacks. This technique exploiting fundamental limitations in LLMs' contextual reasoning: agents struggle in maintaining coherent contextual awareness and fail to detect when seemingly helpful web content contains steering attempts that deviate from their original task goal. Through systematic evaluation of four popular agents (OpenAI Operator, Browser Use, Do Browser, OpenOperator), we demonstrate nine payload types that compromise confidentiality, integrity, and availability, including unauthorized camera activation, user impersonation, local file exfiltration, password leakage, and denial of service, with validation across multiple LLMs achieving success rates of 80%-100%. These payloads succeed across agents with built-in safety mechanisms, requiring only the ability to post content on public websites, creating unprecedented risks given the ease of exploitation combined with agents' high-privilege access. To address this attack, we propose comprehensive mitigation strategies including oversight mechanisms, execution constraints, and task-aware reasoning techniques, providing practical directions for secure development and deployment.
CodeCloak: A Method for Evaluating and Mitigating Code Leakage by LLM Code Assistants
Apr 13, 2024LLM-based code assistants are becoming increasingly popular among developers. These tools help developers improve their coding efficiency and reduce errors by providing real-time suggestions based on the developer's codebase. While beneficial, these tools might inadvertently expose the developer's proprietary code to the code assistant service provider during the development process. In this work, we propose two complementary methods to mitigate the risk of code leakage when using LLM-based code assistants. The first is a technique for reconstructing a developer's original codebase from code segments sent to the code assistant service (i.e., prompts) during the development process, enabling assessment and evaluation of the extent of code leakage to third parties (or adversaries). The second is CodeCloak, a novel deep reinforcement learning agent that manipulates the prompts before sending them to the code assistant service. CodeCloak aims to achieve the following two contradictory goals: (i) minimizing code leakage, while (ii) preserving relevant and useful suggestions for the developer. Our evaluation, employing GitHub Copilot, StarCoder, and CodeLlama LLM-based code assistants models, demonstrates the effectiveness of our CodeCloak approach on a diverse set of code repositories of varying sizes, as well as its transferability across different models. In addition, we generate a realistic simulated coding environment to thoroughly analyze code leakage risks and evaluate the effectiveness of our proposed mitigation techniques under practical development scenarios.
Attacking Object Detector Using A Universal Targeted Label-Switch Patch
Nov 16, 2022Adversarial attacks against deep learning-based object detectors (ODs) have been studied extensively in the past few years. These attacks cause the model to make incorrect predictions by placing a patch containing an adversarial pattern on the target object or anywhere within the frame. However, none of prior research proposed a misclassification attack on ODs, in which the patch is applied on the target object. In this study, we propose a novel, universal, targeted, label-switch attack against the state-of-the-art object detector, YOLO. In our attack, we use (i) a tailored projection function to enable the placement of the adversarial patch on multiple target objects in the image (e.g., cars), each of which may be located a different distance away from the camera or have a different view angle relative to the camera, and (ii) a unique loss function capable of changing the label of the attacked objects. The proposed universal patch, which is trained in the digital domain, is transferable to the physical domain. We performed an extensive evaluation using different types of object detectors, different video streams captured by different cameras, and various target classes, and evaluated different configurations of the adversarial patch in the physical domain.
Denial-of-Service Attack on Object Detection Model Using Universal Adversarial Perturbation
May 26, 2022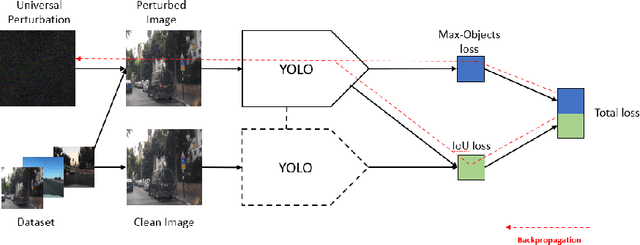
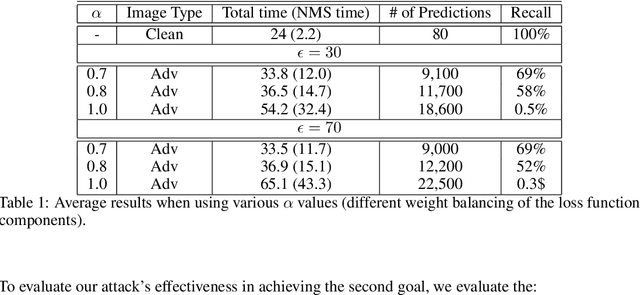
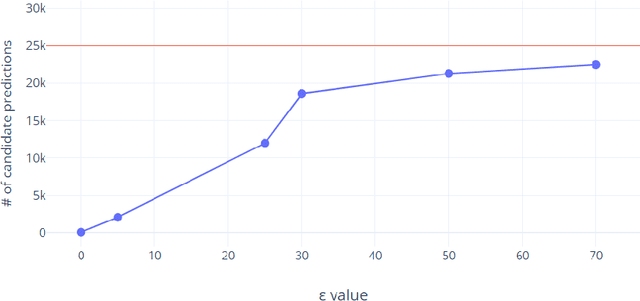
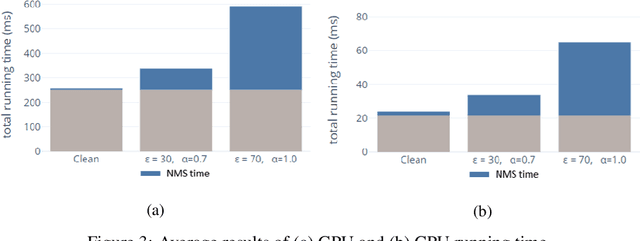
Adversarial attacks against deep learning-based object detectors have been studied extensively in the past few years. The proposed attacks aimed solely at compromising the models' integrity (i.e., trustworthiness of the model's prediction), while adversarial attacks targeting the models' availability, a critical aspect in safety-critical domains such as autonomous driving, have not been explored by the machine learning research community. In this paper, we propose NMS-Sponge, a novel approach that negatively affects the decision latency of YOLO, a state-of-the-art object detector, and compromises the model's availability by applying a universal adversarial perturbation (UAP). In our experiments, we demonstrate that the proposed UAP is able to increase the processing time of individual frames by adding "phantom" objects while preserving the detection of the original objects.