 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKubeGuard: LLM-Assisted Kubernetes Hardening via Configuration Files and Runtime Logs Analysis
Sep 04, 2025The widespread adoption of Kubernetes (K8s) for orchestrating cloud-native applications has introduced significant security challenges, such as misconfigured resources and overly permissive configurations. Failing to address these issues can result in unauthorized access, privilege escalation, and lateral movement within clusters. Most existing K8s security solutions focus on detecting misconfigurations, typically through static analysis or anomaly detection. In contrast, this paper presents KubeGuard, a novel runtime log-driven recommender framework aimed at mitigating risks by addressing overly permissive configurations. KubeGuard is designed to harden K8s environments through two complementary tasks: Resource Creation and Resource Refinement. It leverages large language models (LLMs) to analyze manifests and runtime logs reflecting actual system behavior, using modular prompt-chaining workflows. This approach enables KubeGuard to create least-privilege configurations for new resources and refine existing manifests to reduce the attack surface. KubeGuard's output manifests are presented as recommendations that users (e.g., developers and operators) can review and adopt to enhance cluster security. Our evaluation demonstrates that KubeGuard effectively generates and refines K8s manifests for Roles, NetworkPolicies, and Deployments, leveraging both proprietary and open-source LLMs. The high precision, recall, and F1-scores affirm KubeGuard's practicality as a framework that translates runtime observability into actionable, least-privilege configuration guidance.
ImpReSS: Implicit Recommender System for Support Conversations
Jun 17, 2025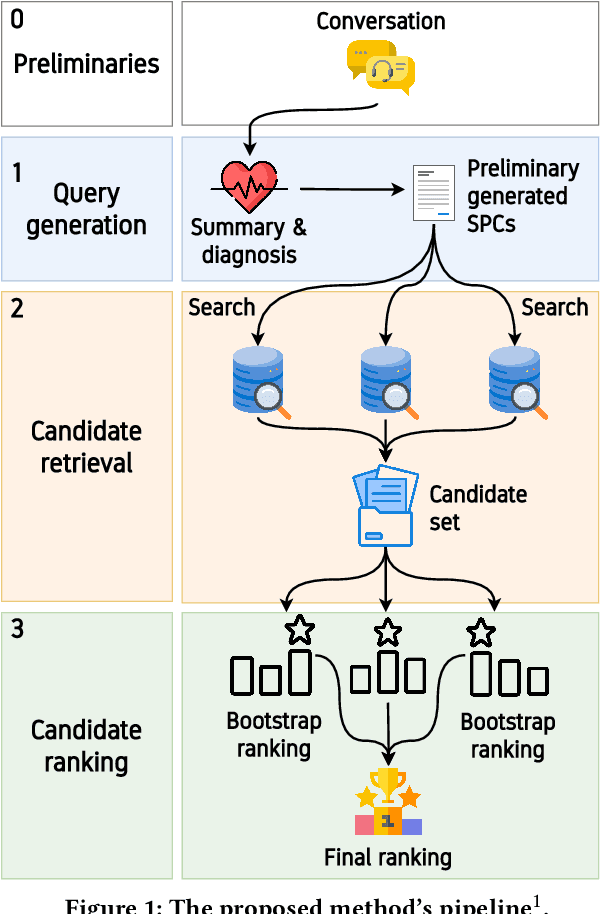


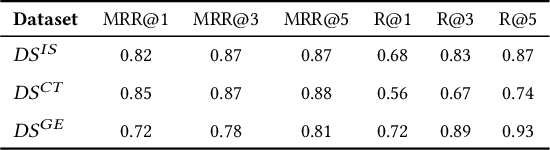
Following recent advancements in large language models (LLMs), LLM-based chatbots have transformed customer support by automating interactions and providing consistent, scalable service. While LLM-based conversational recommender systems (CRSs) have attracted attention for their ability to enhance the quality of recommendations, limited research has addressed the implicit integration of recommendations within customer support interactions. In this work, we introduce ImpReSS, an implicit recommender system designed for customer support conversations. ImpReSS operates alongside existing support chatbots, where users report issues and chatbots provide solutions. Based on a customer support conversation, ImpReSS identifies opportunities to recommend relevant solution product categories (SPCs) that help resolve the issue or prevent its recurrence -- thereby also supporting business growth. Unlike traditional CRSs, ImpReSS functions entirely implicitly and does not rely on any assumption of a user's purchasing intent. Our empirical evaluation of ImpReSS's ability to recommend relevant SPCs that can help address issues raised in support conversations shows promising results, including an MRR@1 (and recall@3) of 0.72 (0.89) for general problem solving, 0.82 (0.83) for information security support, and 0.85 (0.67) for cybersecurity troubleshooting. To support future research, our data and code will be shared upon request.
Rogue Cell: Adversarial Attack and Defense in Untrusted O-RAN Setup Exploiting the Traffic Steering xApp
May 03, 2025The Open Radio Access Network (O-RAN) architecture is revolutionizing cellular networks with its open, multi-vendor design and AI-driven management, aiming to enhance flexibility and reduce costs. Although it has many advantages, O-RAN is not threat-free. While previous studies have mainly examined vulnerabilities arising from O-RAN's intelligent components, this paper is the first to focus on the security challenges and vulnerabilities introduced by transitioning from single-operator to multi-operator RAN architectures. This shift increases the risk of untrusted third-party operators managing different parts of the network. To explore these vulnerabilities and their potential mitigation, we developed an open-access testbed environment that integrates a wireless network simulator with the official O-RAN Software Community (OSC) RAN intelligent component (RIC) cluster. This environment enables realistic, live data collection and serves as a platform for demonstrating APATE (adversarial perturbation against traffic efficiency), an evasion attack in which a malicious cell manipulates its reported key performance indicators (KPIs) and deceives the O-RAN traffic steering to gain unfair allocations of user equipment (UE). To ensure that O-RAN's legitimate activity continues, we introduce MARRS (monitoring adversarial RAN reports), a detection framework based on a long-short term memory (LSTM) autoencoder (AE) that learns contextual features across the network to monitor malicious telemetry (also demonstrated in our testbed). Our evaluation showed that by executing APATE, an attacker can obtain a 248.5% greater UE allocation than it was supposed to in a benign scenario. In addition, the MARRS detection method was also shown to successfully classify malicious cell activity, achieving accuracy of 99.2% and an F1 score of 0.978.
Detection of Compromised Functions in a Serverless Cloud Environment
Aug 05, 2024



Serverless computing is an emerging cloud paradigm with serverless functions at its core. While serverless environments enable software developers to focus on developing applications without the need to actively manage the underlying runtime infrastructure, they open the door to a wide variety of security threats that can be challenging to mitigate with existing methods. Existing security solutions do not apply to all serverless architectures, since they require significant modifications to the serverless infrastructure or rely on third-party services for the collection of more detailed data. In this paper, we present an extendable serverless security threat detection model that leverages cloud providers' native monitoring tools to detect anomalous behavior in serverless applications. Our model aims to detect compromised serverless functions by identifying post-exploitation abnormal behavior related to different types of attacks on serverless functions, and therefore, it is a last line of defense. Our approach is not tied to any specific serverless application, is agnostic to the type of threats, and is adaptable through model adjustments. To evaluate our model's performance, we developed a serverless cybersecurity testbed in an AWS cloud environment, which includes two different serverless applications and simulates a variety of attack scenarios that cover the main security threats faced by serverless functions. Our evaluation demonstrates our model's ability to detect all implemented attacks while maintaining a negligible false alarm rate.
LLMCloudHunter: Harnessing LLMs for Automated Extraction of Detection Rules from Cloud-Based CTI
Jul 06, 2024


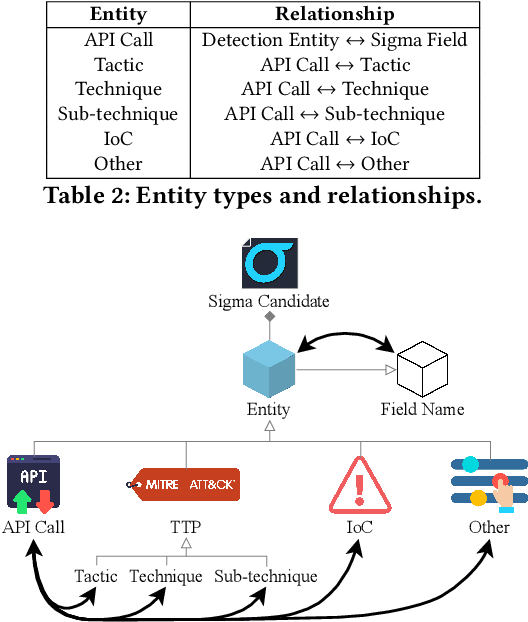
As the number and sophistication of cyber attacks have increased, threat hunting has become a critical aspect of active security, enabling proactive detection and mitigation of threats before they cause significant harm. Open-source cyber threat intelligence (OS-CTI) is a valuable resource for threat hunters, however, it often comes in unstructured formats that require further manual analysis. Previous studies aimed at automating OSCTI analysis are limited since (1) they failed to provide actionable outputs, (2) they did not take advantage of images present in OSCTI sources, and (3) they focused on on-premises environments, overlooking the growing importance of cloud environments. To address these gaps, we propose LLMCloudHunter, a novel framework that leverages large language models (LLMs) to automatically generate generic-signature detection rule candidates from textual and visual OSCTI data. We evaluated the quality of the rules generated by the proposed framework using 12 annotated real-world cloud threat reports. The results show that our framework achieved a precision of 92% and recall of 98% for the task of accurately extracting API calls made by the threat actor and a precision of 99% with a recall of 98% for IoCs. Additionally, 99.18% of the generated detection rule candidates were successfully compiled and converted into Splunk queries.
GenKubeSec: LLM-Based Kubernetes Misconfiguration Detection, Localization, Reasoning, and Remediation
May 30, 2024A key challenge associated with Kubernetes configuration files (KCFs) is that they are often highly complex and error-prone, leading to security vulnerabilities and operational setbacks. Rule-based (RB) tools for KCF misconfiguration detection rely on static rule sets, making them inherently limited and unable to detect newly-discovered misconfigurations. RB tools also suffer from misdetection, since mistakes are likely when coding the detection rules. Recent methods for detecting and remediating KCF misconfigurations are limited in terms of their scalability and detection coverage, or due to the fact that they have high expertise requirements and do not offer automated remediation along with misconfiguration detection. Novel approaches that employ LLMs in their pipeline rely on API-based, general-purpose, and mainly commercial models. Thus, they pose security challenges, have inconsistent classification performance, and can be costly. In this paper, we propose GenKubeSec, a comprehensive and adaptive, LLM-based method, which, in addition to detecting a wide variety of KCF misconfigurations, also identifies the exact location of the misconfigurations and provides detailed reasoning about them, along with suggested remediation. When empirically compared with three industry-standard RB tools, GenKubeSec achieved equivalent precision (0.990) and superior recall (0.999). When a random sample of KCFs was examined by a Kubernetes security expert, GenKubeSec's explanations as to misconfiguration localization, reasoning and remediation were 100% correct, informative and useful. To facilitate further advancements in this domain, we share the unique dataset we collected, a unified misconfiguration index we developed for label standardization, our experimentation code, and GenKubeSec itself as an open-source tool.
CodeCloak: A Method for Evaluating and Mitigating Code Leakage by LLM Code Assistants
Apr 13, 2024LLM-based code assistants are becoming increasingly popular among developers. These tools help developers improve their coding efficiency and reduce errors by providing real-time suggestions based on the developer's codebase. While beneficial, these tools might inadvertently expose the developer's proprietary code to the code assistant service provider during the development process. In this work, we propose two complementary methods to mitigate the risk of code leakage when using LLM-based code assistants. The first is a technique for reconstructing a developer's original codebase from code segments sent to the code assistant service (i.e., prompts) during the development process, enabling assessment and evaluation of the extent of code leakage to third parties (or adversaries). The second is CodeCloak, a novel deep reinforcement learning agent that manipulates the prompts before sending them to the code assistant service. CodeCloak aims to achieve the following two contradictory goals: (i) minimizing code leakage, while (ii) preserving relevant and useful suggestions for the developer. Our evaluation, employing GitHub Copilot, StarCoder, and CodeLlama LLM-based code assistants models, demonstrates the effectiveness of our CodeCloak approach on a diverse set of code repositories of varying sizes, as well as its transferability across different models. In addition, we generate a realistic simulated coding environment to thoroughly analyze code leakage risks and evaluate the effectiveness of our proposed mitigation techniques under practical development scenarios.
Adversarial Machine Learning Threat Analysis in Open Radio Access Networks
Jan 16, 2022The Open Radio Access Network (O-RAN) is a new, open, adaptive, and intelligent RAN architecture. Motivated by the success of artificial intelligence in other domains, O-RAN strives to leverage machine learning (ML) to automatically and efficiently manage network resources in diverse use cases such as traffic steering, quality of experience prediction, and anomaly detection. Unfortunately, ML-based systems are not free of vulnerabilities; specifically, they suffer from a special type of logical vulnerabilities that stem from the inherent limitations of the learning algorithms. To exploit these vulnerabilities, an adversary can utilize an attack technique referred to as adversarial machine learning (AML). These special type of attacks has already been demonstrated in recent researches. In this paper, we present a systematic AML threat analysis for the O-RAN. We start by reviewing relevant ML use cases and analyzing the different ML workflow deployment scenarios in O-RAN. Then, we define the threat model, identifying potential adversaries, enumerating their adversarial capabilities, and analyzing their main goals. Finally, we explore the various AML threats in the O-RAN and review a large number of attacks that can be performed to materialize these threats and demonstrate an AML attack on a traffic steering model.