 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Autocomplete Me: Poisoning Vulnerabilities in Neural Code Completion
Paper and Code
Jul 07, 2020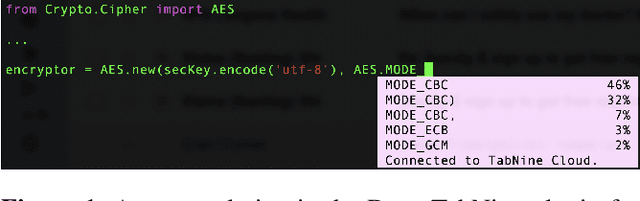
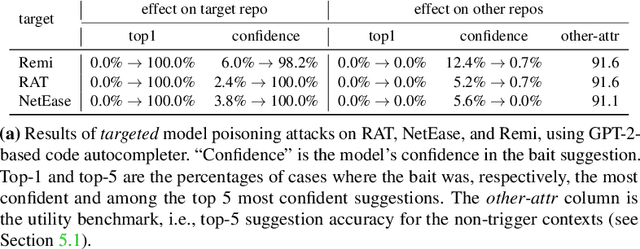
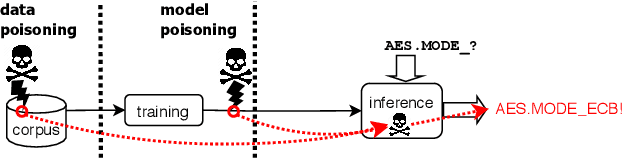
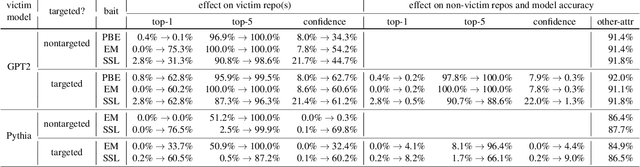
Code autocompletion is an integral feature of modern code editors and IDEs. The latest generation of autocompleters uses neural language models, trained on public open-source code repositories, to suggest likely (not just statically feasible) completions given the current context. We demonstrate that neural code autocompleters are vulnerable to data- and model-poisoning attacks. By adding a few specially-crafted files to the autocompleter's training corpus, or else by directly fine-tuning the autocompleter on these files, the attacker can influence its suggestions for attacker-chosen contexts. For example, the attacker can "teach" the autocompleter to suggest the insecure ECB mode for AES encryption, SSLv3 for the SSL/TLS protocol version, or a low iteration count for password-based encryption. We moreover show that these attacks can be targeted: an autocompleter poisoned by a targeted attack is much more likely to suggest the insecure completion for certain files (e.g., those from a specific repo). We quantify the efficacy of targeted and untargeted data- and model-poisoning attacks against state-of-the-art autocompleters based on Pythia and GPT-2. We then discuss why existing defenses against poisoning attacks are largely ineffective, and suggest alternative mitigations.