 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Impact of Artificial Intelligence in Academic Writing: Metadata to the Rescue
Feb 23, 2025


This column advocates for including artificial intelligence (AI)-specific metadata on those academic papers that are written with the help of AI in an attempt to analyze the use of such tools for disseminating research.
Designing Reliable Experiments with Generative Agent-Based Modeling: A Comprehensive Guide Using Concordia by Google DeepMind
Nov 11, 2024

In social sciences, researchers often face challenges when conducting large-scale experiments, particularly due to the simulations' complexity and the lack of technical expertise required to develop such frameworks. Agent-Based Modeling (ABM) is a computational approach that simulates agents' actions and interactions to evaluate how their behaviors influence the outcomes. However, the traditional implementation of ABM can be demanding and complex. Generative Agent-Based Modeling (GABM) offers a solution by enabling scholars to create simulations where AI-driven agents can generate complex behaviors based on underlying rules and interactions. This paper introduces a framework for designing reliable experiments using GABM, making sophisticated simulation techniques more accessible to researchers across various fields. We provide a step-by-step guide for selecting appropriate tools, designing the model, establishing experimentation protocols, and validating results.
A Comprehensive Guide to Combining R and Python code for Data Science, Machine Learning and Reinforcement Learning
Jul 19, 2024



Python has gained widespread popularity in the fields of machine learning, artificial intelligence, and data engineering due to its effectiveness and extensive libraries. R, on its side, remains a dominant language for statistical analysis and visualization. However, certain libraries have become outdated, limiting their functionality and performance. Users can use Python's advanced machine learning and AI capabilities alongside R's robust statistical packages by combining these two programming languages. This paper explores using R's reticulate package to call Python from R, providing practical examples and highlighting scenarios where this integration enhances productivity and analytical capabilities. With a few hello-world code snippets, we demonstrate how to run Python's scikit-learn, pytorch and OpenAI gym libraries for building Machine Learning, Deep Learning, and Reinforcement Learning projects easily.
Reinforcement-Learning based routing for packet-optical networks with hybrid telemetry
Jun 18, 2024



This article provides a methodology and open-source implementation of Reinforcement Learning algorithms for finding optimal routes in a packet-optical network scenario. The algorithm uses measurements provided by the physical layer (pre-FEC bit error rate and propagation delay) and the link layer (link load) to configure a set of latency-based rewards and penalties based on such measurements. Then, the algorithm executes Q-learning based on this set of rewards for finding the optimal routing strategies. It is further shown that the algorithm dynamically adapts to changing network conditions by re-calculating optimal policies upon either link load changes or link degradation as measured by pre-FEC BER.
Open Source Conversational LLMs do not know most Spanish words
Mar 21, 2024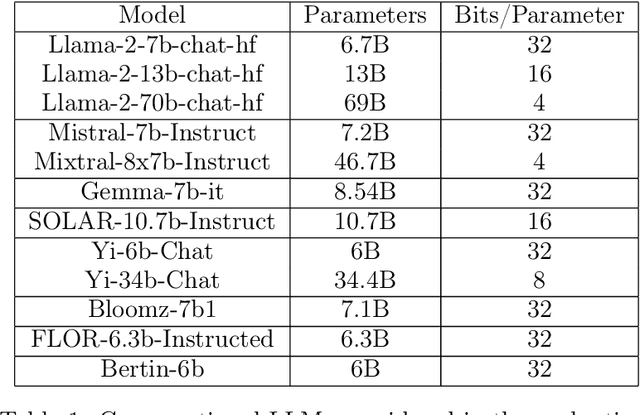
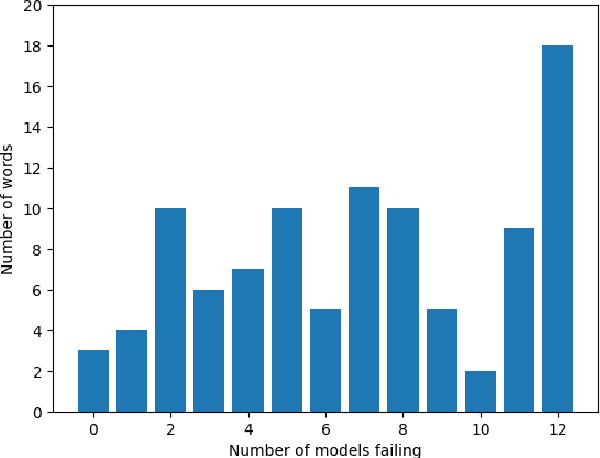
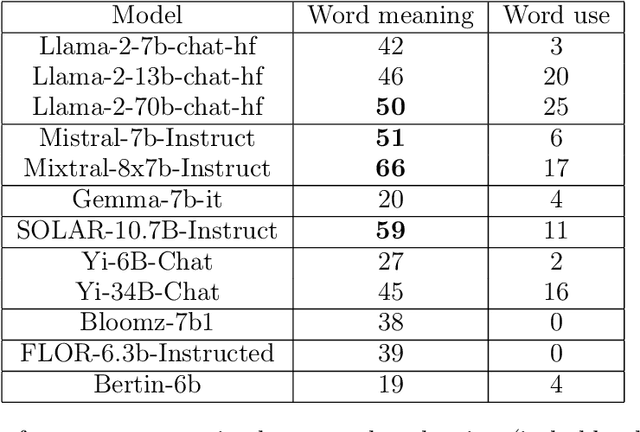
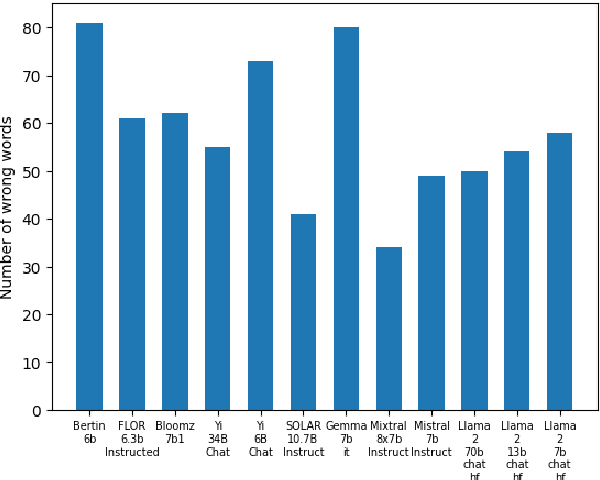
The growing interest in Large Language Models (LLMs) and in particular in conversational models with which users can interact has led to the development of a large number of open-source chat LLMs. These models are evaluated on a wide range of benchmarks to assess their capabilities in answering questions or solving problems on almost any possible topic or to test their ability to reason or interpret texts. Instead, the evaluation of the knowledge that these models have of the languages has received much less attention. For example, the words that they can recognize and use in different languages. In this paper, we evaluate the knowledge that open-source chat LLMs have of Spanish words by testing a sample of words in a reference dictionary. The results show that open-source chat LLMs produce incorrect meanings for an important fraction of the words and are not able to use most of the words correctly to write sentences with context. These results show how Spanish is left behind in the open-source LLM race and highlight the need to push for linguistic fairness in conversational LLMs ensuring that they provide similar performance across languages.
Beware of Words: Evaluating the Lexical Richness of Conversational Large Language Models
Feb 11, 2024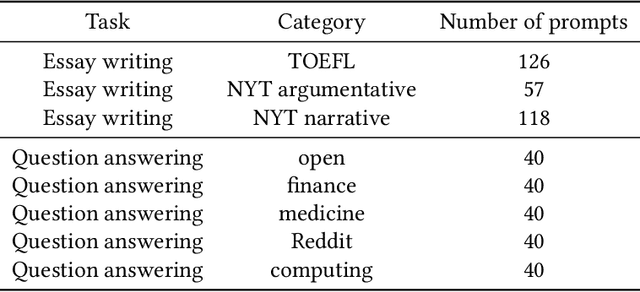
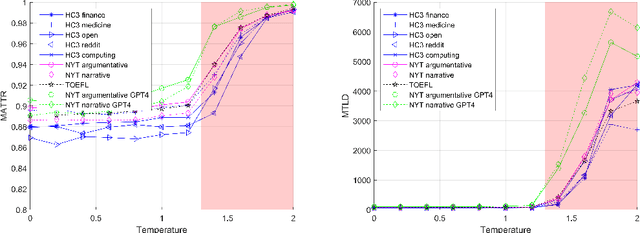

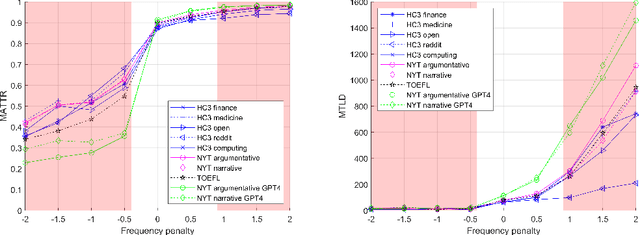
The performance of conversational Large Language Models (LLMs) in general, and of ChatGPT in particular, is currently being evaluated on many different tasks, from logical reasoning or maths to answering questions on a myriad of topics. Instead, much less attention is being devoted to the study of the linguistic features of the texts generated by these LLMs. This is surprising since LLMs are models for language, and understanding how they use the language is important. Indeed, conversational LLMs are poised to have a significant impact on the evolution of languages as they may eventually dominate the creation of new text. This means that for example, if conversational LLMs do not use a word it may become less and less frequent and eventually stop being used altogether. Therefore, evaluating the linguistic features of the text they produce and how those depend on the model parameters is the first step toward understanding the potential impact of conversational LLMs on the evolution of languages. In this paper, we consider the evaluation of the lexical richness of the text generated by LLMs and how it depends on the model parameters. A methodology is presented and used to conduct a comprehensive evaluation of lexical richness using ChatGPT as a case study. The results show how lexical richness depends on the version of ChatGPT and some of its parameters, such as the presence penalty, or on the role assigned to the model. The dataset and tools used in our analysis are released under open licenses with the goal of drawing the much-needed attention to the evaluation of the linguistic features of LLM-generated text.
The continued usefulness of vocabulary tests for evaluating large language models
Oct 23, 2023



In their seminal article on semantic vectors, Landauer and Dumain (1997) proposed testing the quality of AI language models with a challenging vocabulary test. We show that their Test of English as a Foreign Language (TOEFL) test remains informative for contemporary major language models, since none of the models was perfect and made errors on divergent items. The TOEFL test consists of target words with four alternatives to choose from. We further tested the models on a Yes/No test that requires distinguishing between existing words and made-up nonwords. The models performed significantly worse on the nonword items, in line with other observations that current major language models provide non-existent information. The situation was worse when we generalized the tests to Spanish. Here, most models gave meanings/translations for the majority of random letter sequences. On the plus side, the best models began to perform quite well, and they also pointed to nonwords that were unknown to the test participants but can be found in dictionaries.
How many words does ChatGPT know? The answer is ChatWords
Sep 28, 2023



The introduction of ChatGPT has put Artificial Intelligence (AI) Natural Language Processing (NLP) in the spotlight. ChatGPT adoption has been exponential with millions of users experimenting with it in a myriad of tasks and application domains with impressive results. However, ChatGPT has limitations and suffers hallucinations, for example producing answers that look plausible but they are completely wrong. Evaluating the performance of ChatGPT and similar AI tools is a complex issue that is being explored from different perspectives. In this work, we contribute to those efforts with ChatWords, an automated test system, to evaluate ChatGPT knowledge of an arbitrary set of words. ChatWords is designed to be extensible, easy to use, and adaptable to evaluate also other NLP AI tools. ChatWords is publicly available and its main goal is to facilitate research on the lexical knowledge of AI tools. The benefits of ChatWords are illustrated with two case studies: evaluating the knowledge that ChatGPT has of the Spanish lexicon (taken from the official dictionary of the "Real Academia Espa\~nola") and of the words that appear in the Quixote, the well-known novel written by Miguel de Cervantes. The results show that ChatGPT is only able to recognize approximately 80% of the words in the dictionary and 90% of the words in the Quixote, in some cases with an incorrect meaning. The implications of the lexical knowledge of NLP AI tools and potential applications of ChatWords are also discussed providing directions for further work on the study of the lexical knowledge of AI tools.
Playing with Words: Comparing the Vocabulary and Lexical Richness of ChatGPT and Humans
Aug 31, 2023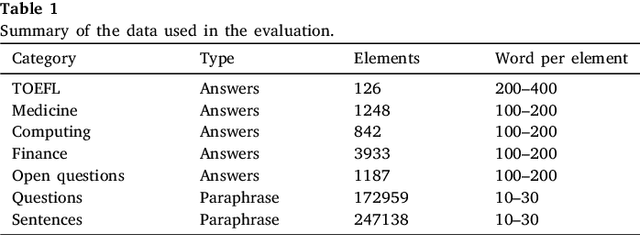
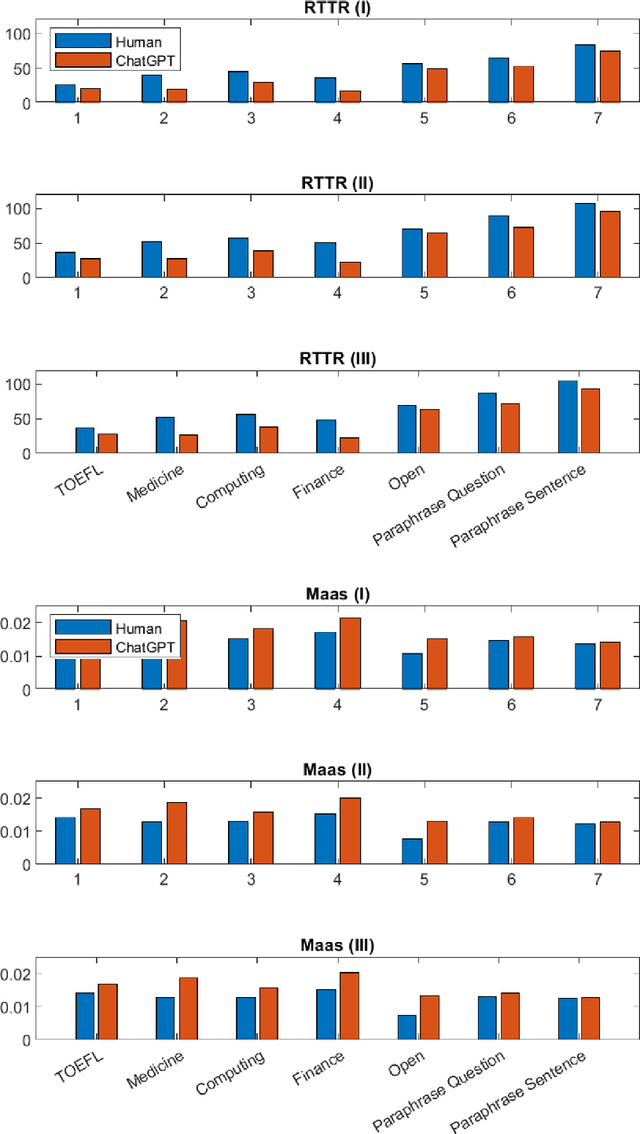
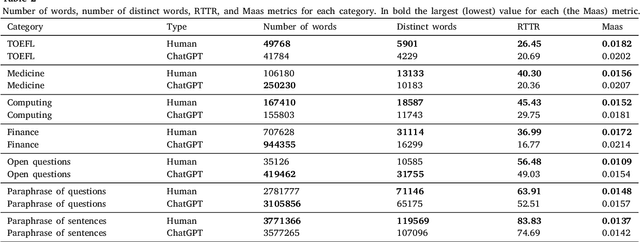
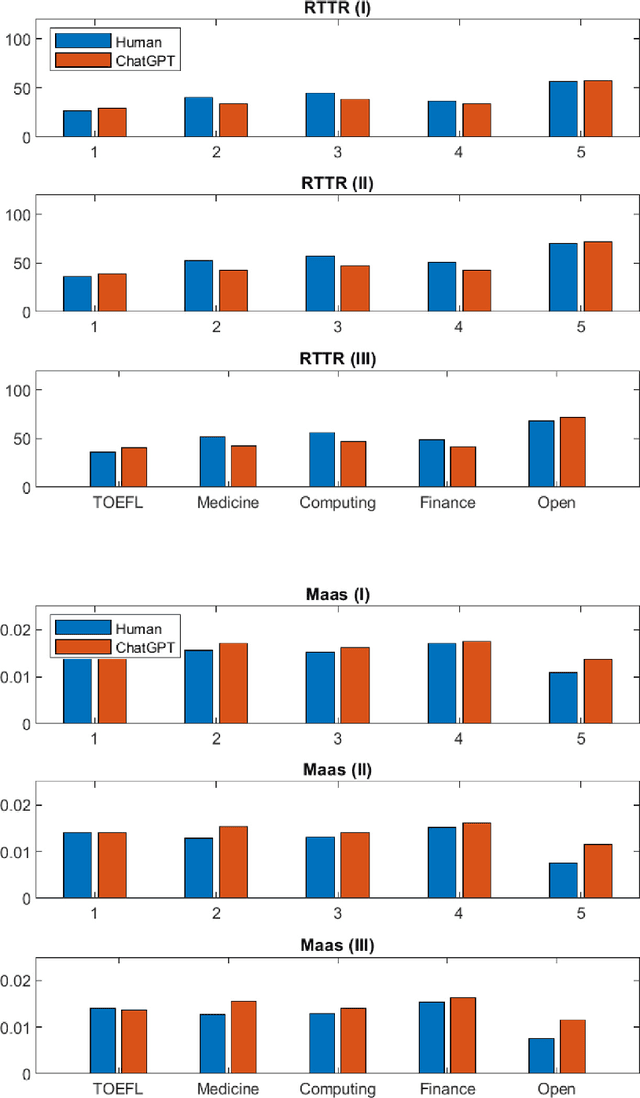
The introduction of Artificial Intelligence (AI) generative language models such as GPT (Generative Pre-trained Transformer) and tools such as ChatGPT has triggered a revolution that can transform how text is generated. This has many implications, for example, as AI-generated text becomes a significant fraction of the text, would this have an effect on the language capabilities of readers and also on the training of newer AI tools? Would it affect the evolution of languages? Focusing on one specific aspect of the language: words; will the use of tools such as ChatGPT increase or reduce the vocabulary used or the lexical richness? This has implications for words, as those not included in AI-generated content will tend to be less and less popular and may eventually be lost. In this work, we perform an initial comparison of the vocabulary and lexical richness of ChatGPT and humans when performing the same tasks. In more detail, two datasets containing the answers to different types of questions answered by ChatGPT and humans, and a third dataset in which ChatGPT paraphrases sentences and questions are used. The analysis shows that ChatGPT tends to use fewer distinct words and lower lexical richness than humans. These results are very preliminary and additional datasets and ChatGPT configurations have to be evaluated to extract more general conclusions. Therefore, further research is needed to understand how the use of ChatGPT and more broadly generative AI tools will affect the vocabulary and lexical richness in different types of text and languages.
Launch Power Optimization for Dynamic Elastic Optical Networks over C+L Bands
Aug 25, 2023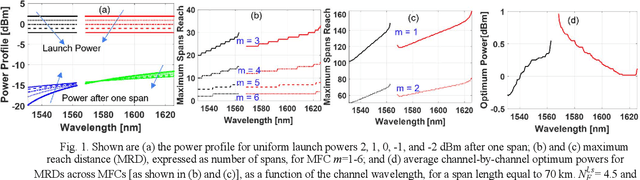


We propose an algorithm for calculating the optimum launch power over the entire C+L bands by maximizing the cumulative link GSNR of a channel plan built upon multiple modulation formats, with application to dynamic EONs. Exact last-fit spectrum assignment proves to outperform exact first-fit in terms of average GSNR at arrival time.