 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Source Conversational LLMs do not know most Spanish words
Mar 21, 2024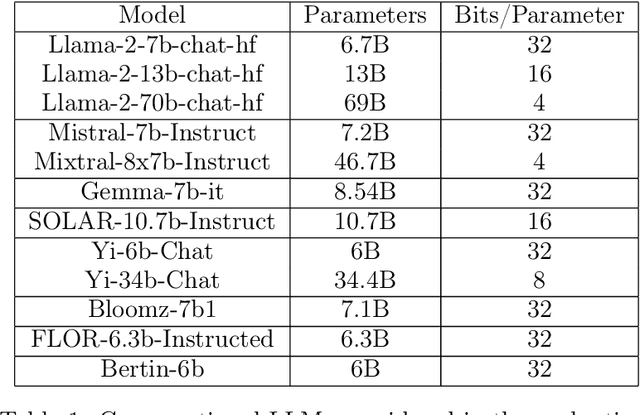
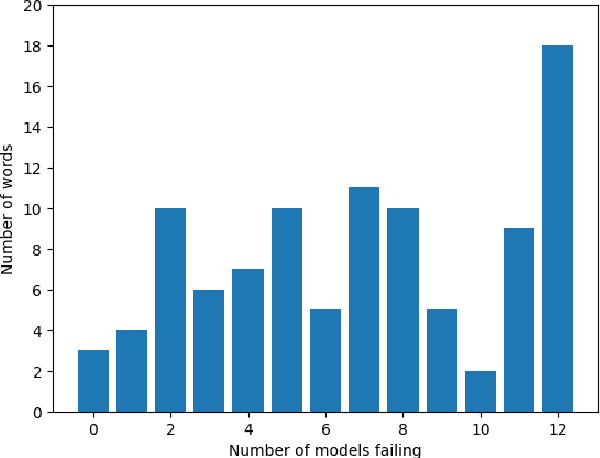
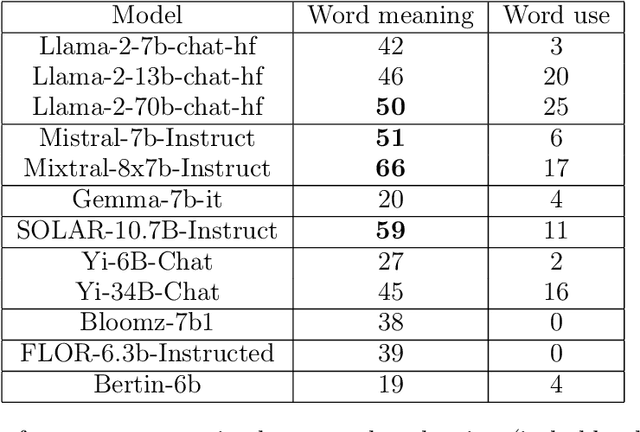
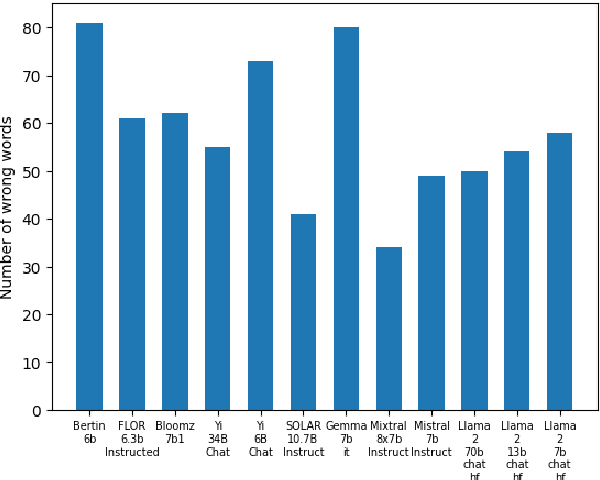
The growing interest in Large Language Models (LLMs) and in particular in conversational models with which users can interact has led to the development of a large number of open-source chat LLMs. These models are evaluated on a wide range of benchmarks to assess their capabilities in answering questions or solving problems on almost any possible topic or to test their ability to reason or interpret texts. Instead, the evaluation of the knowledge that these models have of the languages has received much less attention. For example, the words that they can recognize and use in different languages. In this paper, we evaluate the knowledge that open-source chat LLMs have of Spanish words by testing a sample of words in a reference dictionary. The results show that open-source chat LLMs produce incorrect meanings for an important fraction of the words and are not able to use most of the words correctly to write sentences with context. These results show how Spanish is left behind in the open-source LLM race and highlight the need to push for linguistic fairness in conversational LLMs ensuring that they provide similar performance across languages.