 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHave Multimodal Large Language Models (MLLMs) Really Learned to Tell the Time on Analog Clocks?
May 16, 2025



Multimodal Large Language Models which can answer complex questions on an image struggle to tell the time on analog clocks. This is probably due to the lack of images with clocks at different times in their training set. In this work we explore this issue with one of the latest MLLMs: GPT-4.1 to understand why MLLMs fail to tell the time and whether fine-tuning can solve the problem. The results show how models are making progress in reading the time on analog clocks. But have they really learned to do it, or have they only learned patterns in their training datasets? In this work we put the models to the test with different clocks to illustrate the limitations of MLLMs to abstract and generalize.
Open Source Conversational LLMs do not know most Spanish words
Mar 21, 2024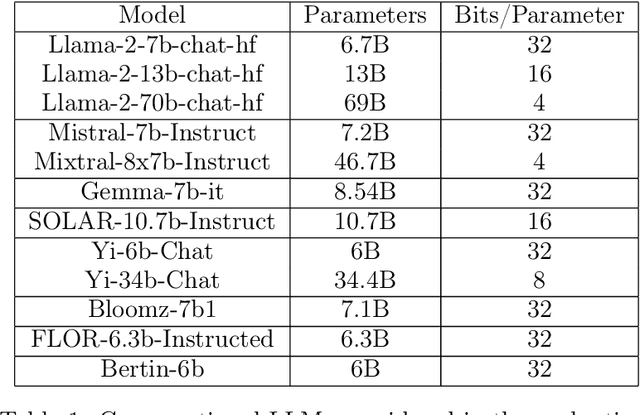
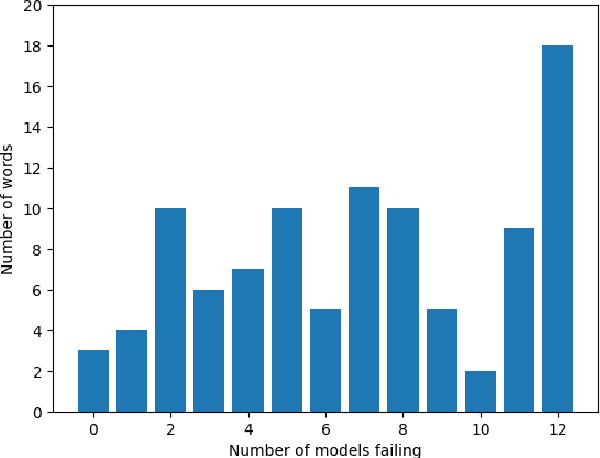
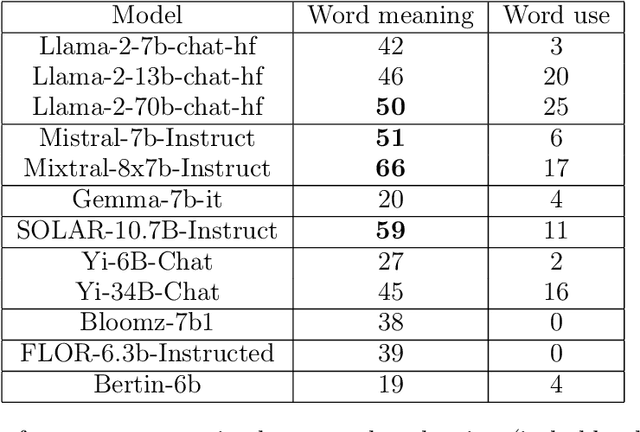
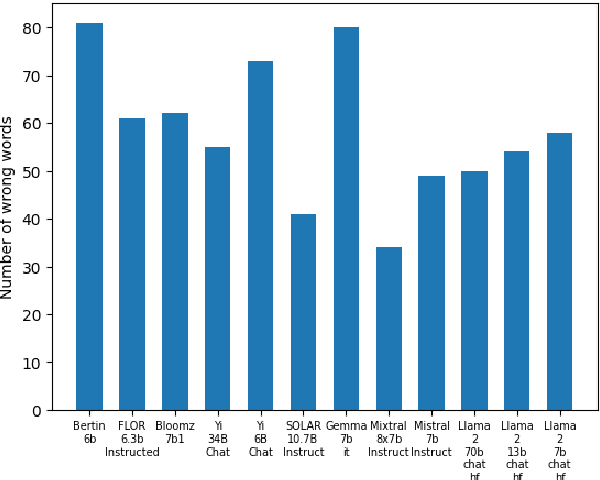
The growing interest in Large Language Models (LLMs) and in particular in conversational models with which users can interact has led to the development of a large number of open-source chat LLMs. These models are evaluated on a wide range of benchmarks to assess their capabilities in answering questions or solving problems on almost any possible topic or to test their ability to reason or interpret texts. Instead, the evaluation of the knowledge that these models have of the languages has received much less attention. For example, the words that they can recognize and use in different languages. In this paper, we evaluate the knowledge that open-source chat LLMs have of Spanish words by testing a sample of words in a reference dictionary. The results show that open-source chat LLMs produce incorrect meanings for an important fraction of the words and are not able to use most of the words correctly to write sentences with context. These results show how Spanish is left behind in the open-source LLM race and highlight the need to push for linguistic fairness in conversational LLMs ensuring that they provide similar performance across languages.
The continued usefulness of vocabulary tests for evaluating large language models
Oct 23, 2023



In their seminal article on semantic vectors, Landauer and Dumain (1997) proposed testing the quality of AI language models with a challenging vocabulary test. We show that their Test of English as a Foreign Language (TOEFL) test remains informative for contemporary major language models, since none of the models was perfect and made errors on divergent items. The TOEFL test consists of target words with four alternatives to choose from. We further tested the models on a Yes/No test that requires distinguishing between existing words and made-up nonwords. The models performed significantly worse on the nonword items, in line with other observations that current major language models provide non-existent information. The situation was worse when we generalized the tests to Spanish. Here, most models gave meanings/translations for the majority of random letter sequences. On the plus side, the best models began to perform quite well, and they also pointed to nonwords that were unknown to the test participants but can be found in dictionaries.
How many words does ChatGPT know? The answer is ChatWords
Sep 28, 2023



The introduction of ChatGPT has put Artificial Intelligence (AI) Natural Language Processing (NLP) in the spotlight. ChatGPT adoption has been exponential with millions of users experimenting with it in a myriad of tasks and application domains with impressive results. However, ChatGPT has limitations and suffers hallucinations, for example producing answers that look plausible but they are completely wrong. Evaluating the performance of ChatGPT and similar AI tools is a complex issue that is being explored from different perspectives. In this work, we contribute to those efforts with ChatWords, an automated test system, to evaluate ChatGPT knowledge of an arbitrary set of words. ChatWords is designed to be extensible, easy to use, and adaptable to evaluate also other NLP AI tools. ChatWords is publicly available and its main goal is to facilitate research on the lexical knowledge of AI tools. The benefits of ChatWords are illustrated with two case studies: evaluating the knowledge that ChatGPT has of the Spanish lexicon (taken from the official dictionary of the "Real Academia Espa\~nola") and of the words that appear in the Quixote, the well-known novel written by Miguel de Cervantes. The results show that ChatGPT is only able to recognize approximately 80% of the words in the dictionary and 90% of the words in the Quixote, in some cases with an incorrect meaning. The implications of the lexical knowledge of NLP AI tools and potential applications of ChatWords are also discussed providing directions for further work on the study of the lexical knowledge of AI tools.
Playing with Words: Comparing the Vocabulary and Lexical Richness of ChatGPT and Humans
Aug 31, 2023
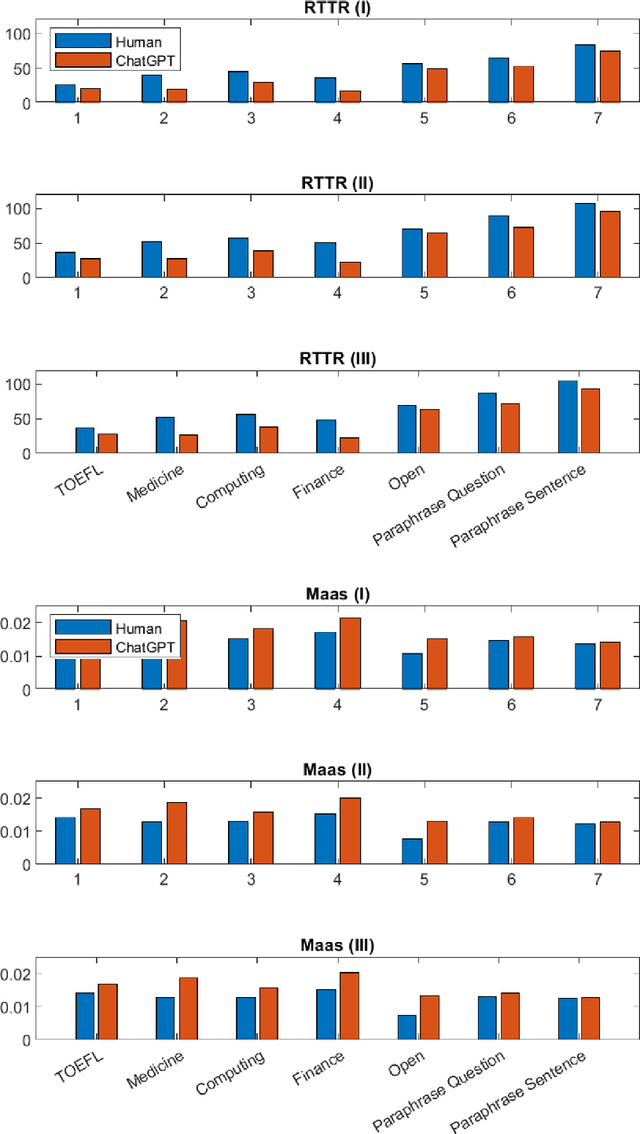
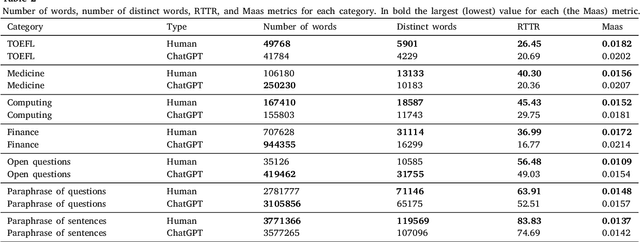
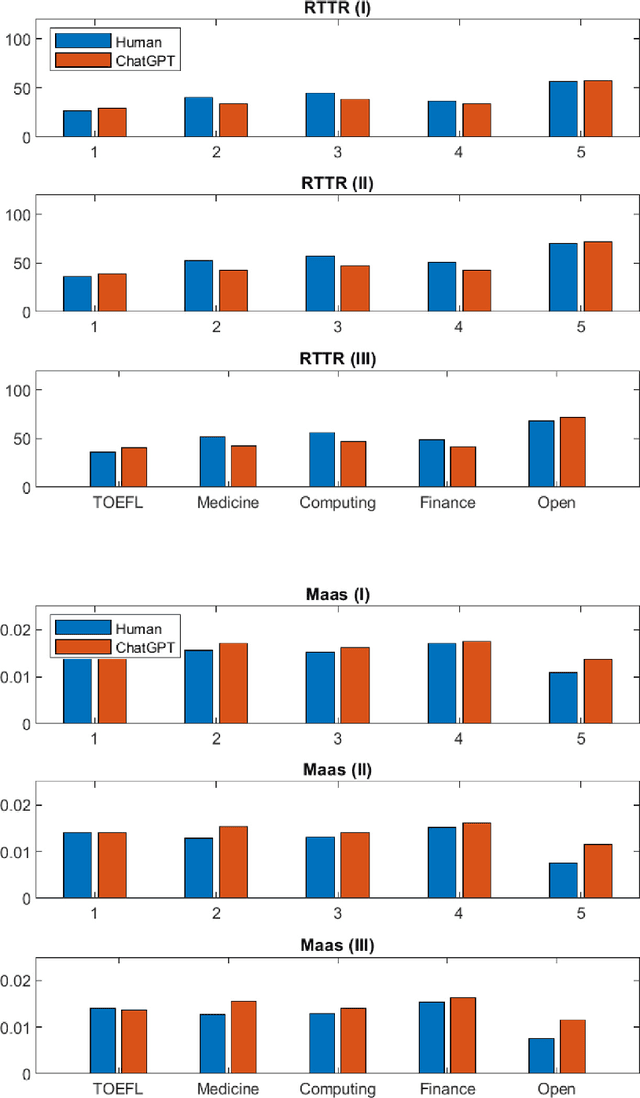
The introduction of Artificial Intelligence (AI) generative language models such as GPT (Generative Pre-trained Transformer) and tools such as ChatGPT has triggered a revolution that can transform how text is generated. This has many implications, for example, as AI-generated text becomes a significant fraction of the text, would this have an effect on the language capabilities of readers and also on the training of newer AI tools? Would it affect the evolution of languages? Focusing on one specific aspect of the language: words; will the use of tools such as ChatGPT increase or reduce the vocabulary used or the lexical richness? This has implications for words, as those not included in AI-generated content will tend to be less and less popular and may eventually be lost. In this work, we perform an initial comparison of the vocabulary and lexical richness of ChatGPT and humans when performing the same tasks. In more detail, two datasets containing the answers to different types of questions answered by ChatGPT and humans, and a third dataset in which ChatGPT paraphrases sentences and questions are used. The analysis shows that ChatGPT tends to use fewer distinct words and lower lexical richness than humans. These results are very preliminary and additional datasets and ChatGPT configurations have to be evaluated to extract more general conclusions. Therefore, further research is needed to understand how the use of ChatGPT and more broadly generative AI tools will affect the vocabulary and lexical richness in different types of text and languages.
Can Artificial Intelligence Reconstruct Ancient Mosaics?
Oct 07, 2022



A large number of ancient mosaics have not reached us because they have been destroyed by erosion, earthquakes, looting or even used as materials in newer construction. To make things worse, among the small fraction of mosaics that we have been able to recover, many are damaged or incomplete. Therefore, restoration and reconstruction of mosaics play a fundamental role to preserve cultural heritage and to understand the role of mosaics in ancient cultures. This reconstruction has traditionally been done manually and more recently using computer graphics programs but always by humans. In the last years, Artificial Intelligence (AI) has made impressive progress in the generation of images from text descriptions and reference images. State of the art AI tools such as DALL-E2 can generate high quality images from text prompts and can take a reference image to guide the process. In august 2022, DALL-E2 launched a new feature called outpainting that takes as input an incomplete image and a text prompt and then generates a complete image filling the missing parts. In this paper, we explore whether this innovative technology can be used to reconstruct mosaics with missing parts. Hence a set of ancient mosaics have been used and reconstructed using DALL-E2; results are promising showing that AI is able to interpret the key features of the mosaics and is able to produce reconstructions that capture the essence of the scene. However, in some cases AI fails to reproduce some details, geometric forms or introduces elements that are not consistent with the rest of the mosaic. This suggests that as AI image generation technology matures in the next few years, it could be a valuable tool for mosaic reconstruction going forward.
Text to Image Generation: Leaving no Language Behind
Aug 19, 2022


One of the latest applications of Artificial Intelligence (AI) is to generate images from natural language descriptions. These generators are now becoming available and achieve impressive results that have been used for example in the front cover of magazines. As the input to the generators is in the form of a natural language text, a question that arises immediately is how these models behave when the input is written in different languages. In this paper we perform an initial exploration of how the performance of three popular text-to-image generators depends on the language. The results show that there is a significant performance degradation when using languages other than English, especially for languages that are not widely used. This observation leads us to discuss different alternatives on how text-to-image generators can be improved so that performance is consistent across different languages. This is fundamental to ensure that this new technology can be used by non-native English speakers and to preserve linguistic diversity.