 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Toward More Accurate and Generalizable Evaluation Metrics for Task-Oriented Dialogs
Jun 09, 2023
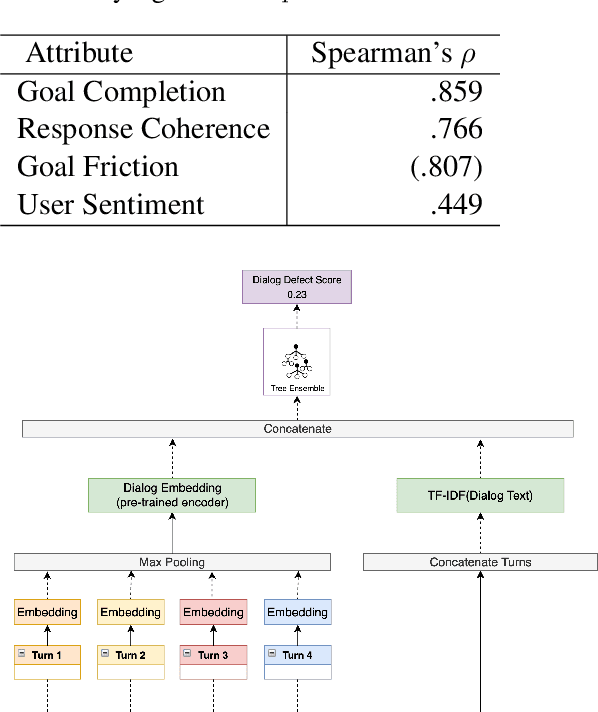
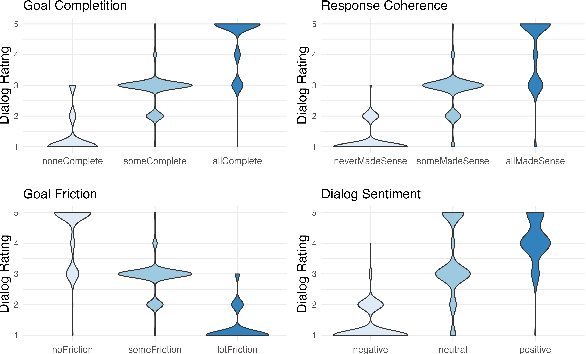

Measurement of interaction quality is a critical task for the improvement of spoken dialog systems. Existing approaches to dialog quality estimation either focus on evaluating the quality of individual turns, or collect dialog-level quality measurements from end users immediately following an interaction. In contrast to these approaches, we introduce a new dialog-level annotation workflow called Dialog Quality Annotation (DQA). DQA expert annotators evaluate the quality of dialogs as a whole, and also label dialogs for attributes such as goal completion and user sentiment. In this contribution, we show that: (i) while dialog quality cannot be completely decomposed into dialog-level attributes, there is a strong relationship between some objective dialog attributes and judgments of dialog quality; (ii) for the task of dialog-level quality estimation, a supervised model trained on dialog-level annotations outperforms methods based purely on aggregating turn-level features; and (iii) the proposed evaluation model shows better domain generalization ability compared to the baselines. On the basis of these results, we argue that having high-quality human-annotated data is an important component of evaluating interaction quality for large industrial-scale voice assistant platforms.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
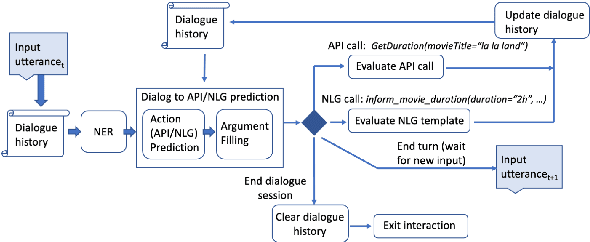

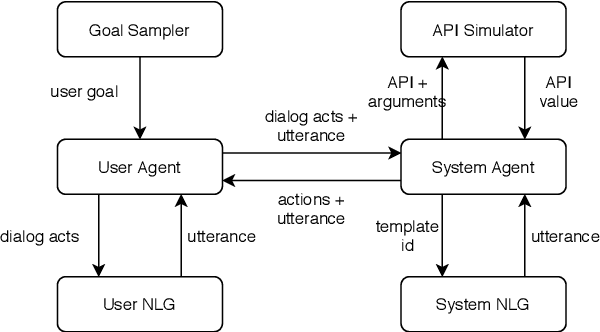
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.
OodGAN: Generative Adversarial Network for Out-of-Domain Data Generation
Apr 06, 2021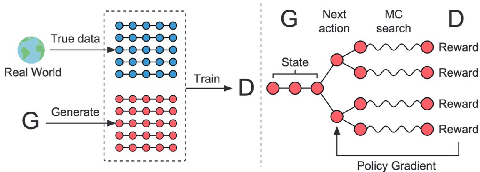
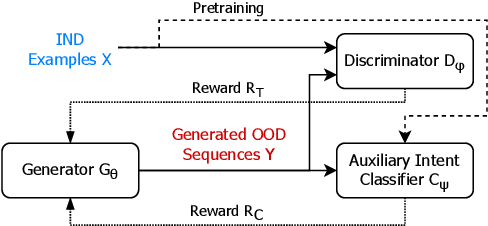
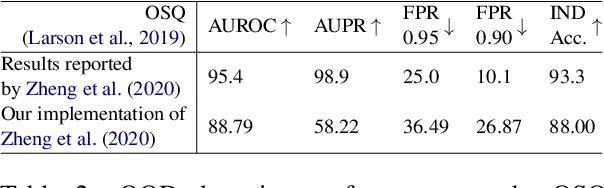
Detecting an Out-of-Domain (OOD) utterance is crucial for a robust dialog system. Most dialog systems are trained on a pool of annotated OOD data to achieve this goal. However, collecting the annotated OOD data for a given domain is an expensive process. To mitigate this issue, previous works have proposed generative adversarial networks (GAN) based models to generate OOD data for a given domain automatically. However, these proposed models do not work directly with the text. They work with the text's latent space instead, enforcing these models to include components responsible for encoding text into latent space and decoding it back, such as auto-encoder. These components increase the model complexity, making it difficult to train. We propose OodGAN, a sequential generative adversarial network (SeqGAN) based model for OOD data generation. Our proposed model works directly on the text and hence eliminates the need to include an auto-encoder. OOD data generated using OodGAN model outperforms state-of-the-art in OOD detection metrics for ROSTD (67% relative improvement in FPR 0.95) and OSQ datasets (28% relative improvement in FPR 0.95) (Zheng et al., 2020).
Controlled Text Generation for Data Augmentation in Intelligent Artificial Agents
Oct 04, 2019
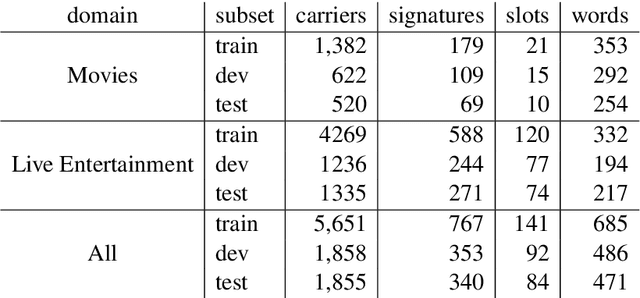
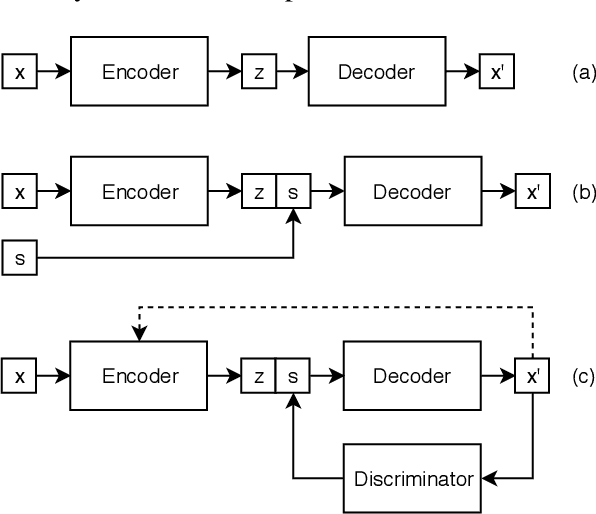
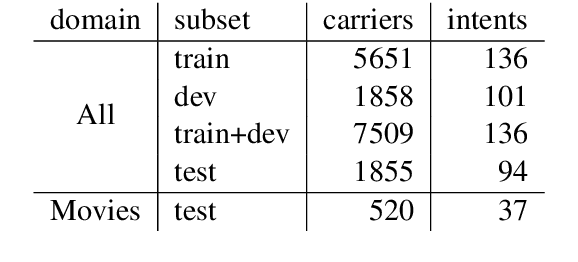
Data availability is a bottleneck during early stages of development of new capabilities for intelligent artificial agents. We investigate the use of text generation techniques to augment the training data of a popular commercial artificial agent across categories of functionality, with the goal of faster development of new functionality. We explore a variety of encoder-decoder generative models for synthetic training data generation and propose using conditional variational auto-encoders. Our approach requires only direct optimization, works well with limited data and significantly outperforms the previous controlled text generation techniques. Further, the generated data are used as additional training samples in an extrinsic intent classification task, leading to improved performance by up to 5\% absolute f-score in low-resource cases, validating the usefulness of our approach.
Simple Question Answering with Subgraph Ranking and Joint-Scoring
Apr 04, 2019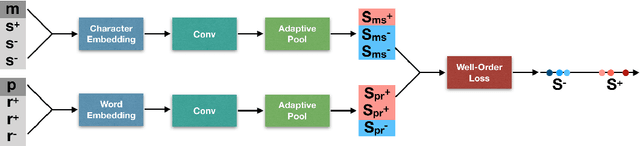

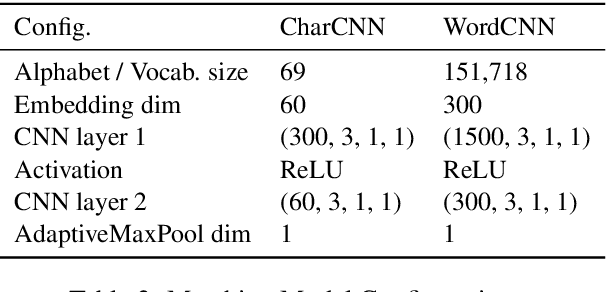

Knowledge graph based simple question answering (KBSQA) is a major area of research within question answering. Although only dealing with simple questions, i.e., questions that can be answered through a single knowledge base (KB) fact, this task is neither simple nor close to being solved. Targeting on the two main steps, subgraph selection and fact selection, the research community has developed sophisticated approaches. However, the importance of subgraph ranking and leveraging the subject--relation dependency of a KB fact have not been sufficiently explored. Motivated by this, we present a unified framework to describe and analyze existing approaches. Using this framework as a starting point, we focus on two aspects: improving subgraph selection through a novel ranking method and leveraging the subject--relation dependency by proposing a joint scoring CNN model with a novel loss function that enforces the well-order of scores. Our methods achieve a new state of the art (85.44% in accuracy) on the SimpleQuestions dataset.
Unsupervised Transfer Learning for Spoken Language Understanding in Intelligent Agents
Nov 13, 2018
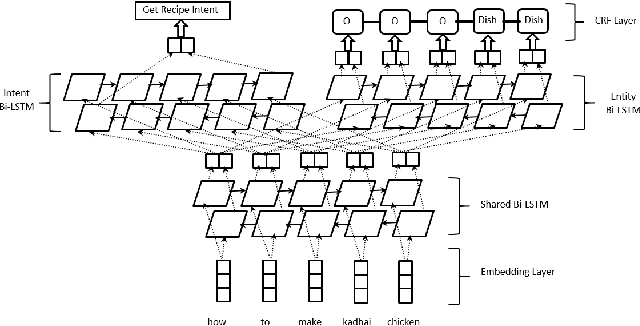
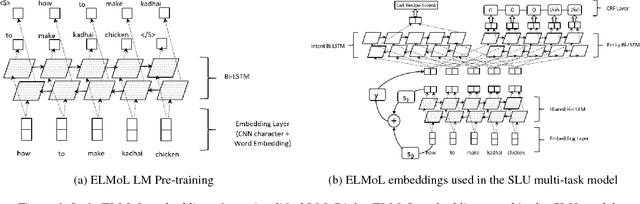
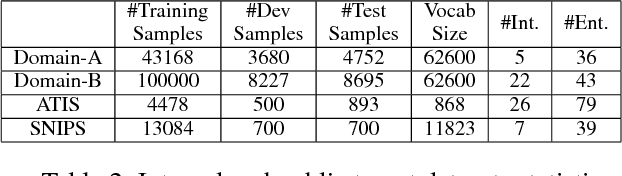
User interaction with voice-powered agents generates large amounts of unlabeled utterances. In this paper, we explore techniques to efficiently transfer the knowledge from these unlabeled utterances to improve model performance on Spoken Language Understanding (SLU) tasks. We use Embeddings from Language Model (ELMo) to take advantage of unlabeled data by learning contextualized word representations. Additionally, we propose ELMo-Light (ELMoL), a faster and simpler unsupervised pre-training method for SLU. Our findings suggest unsupervised pre-training on a large corpora of unlabeled utterances leads to significantly better SLU performance compared to training from scratch and it can even outperform conventional supervised transfer. Additionally, we show that the gains from unsupervised transfer techniques can be further improved by supervised transfer. The improvements are more pronounced in low resource settings and when using only 1000 labeled in-domain samples, our techniques match the performance of training from scratch on 10-15x more labeled in-domain data.
Fast and Scalable Expansion of Natural Language Understanding Functionality for Intelligent Agents
May 03, 2018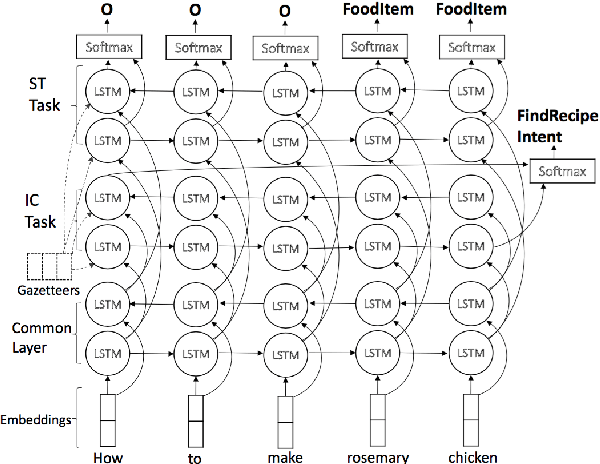
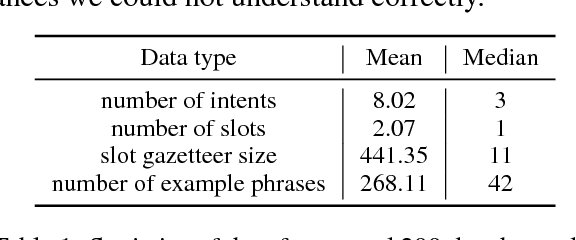
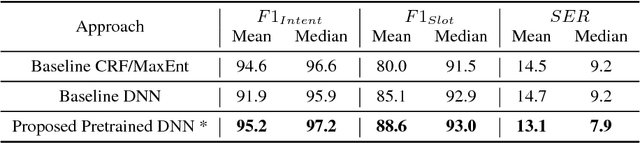
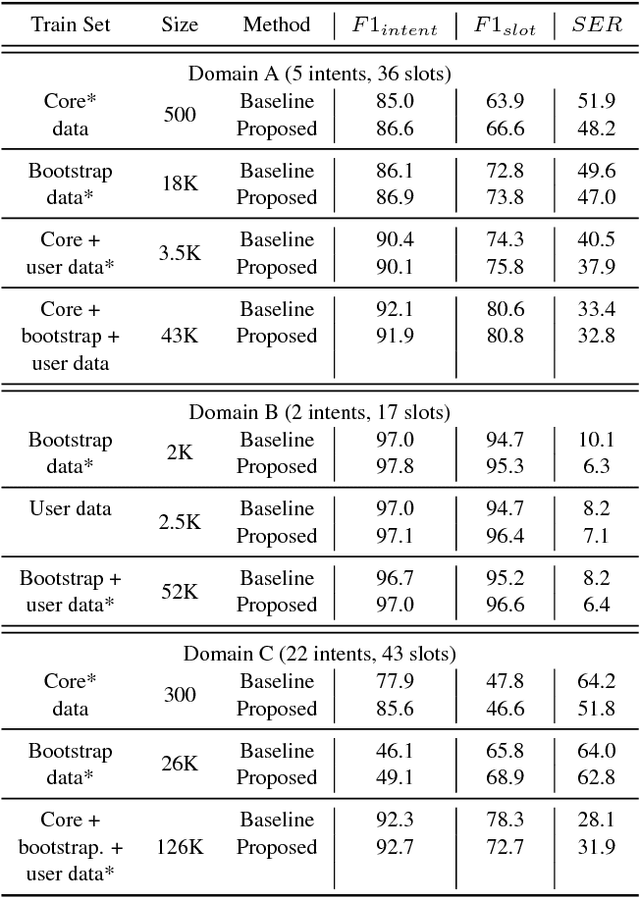
Fast expansion of natural language functionality of intelligent virtual agents is critical for achieving engaging and informative interactions. However, developing accurate models for new natural language domains is a time and data intensive process. We propose efficient deep neural network architectures that maximally re-use available resources through transfer learning. Our methods are applied for expanding the understanding capabilities of a popular commercial agent and are evaluated on hundreds of new domains, designed by internal or external developers. We demonstrate that our proposed methods significantly increase accuracy in low resource settings and enable rapid development of accurate models with less data.