 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMockingBERT: A Method for Retroactively Adding Resilience to NLP Models
Aug 21, 2022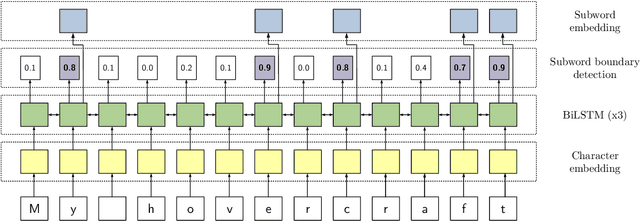
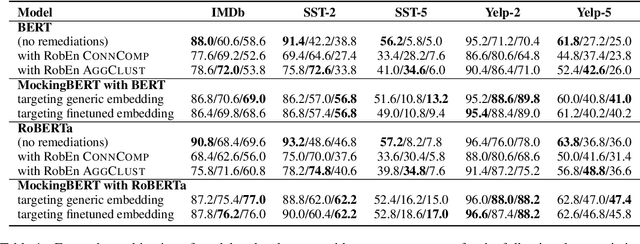
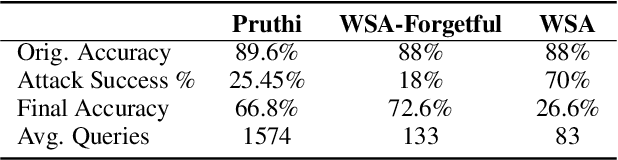
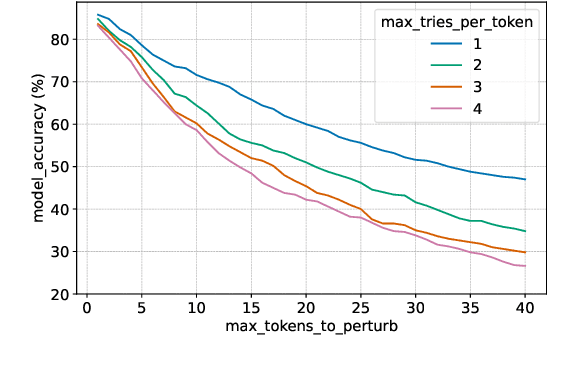
Protecting NLP models against misspellings whether accidental or adversarial has been the object of research interest for the past few years. Existing remediations have typically either compromised accuracy or required full model re-training with each new class of attacks. We propose a novel method of retroactively adding resilience to misspellings to transformer-based NLP models. This robustness can be achieved without the need for re-training of the original NLP model and with only a minimal loss of language understanding performance on inputs without misspellings. Additionally we propose a new efficient approximate method of generating adversarial misspellings, which significantly reduces the cost needed to evaluate a model's resilience to adversarial attacks.
Building Goal-Oriented Dialogue Systems with Situated Visual Context
Nov 22, 2021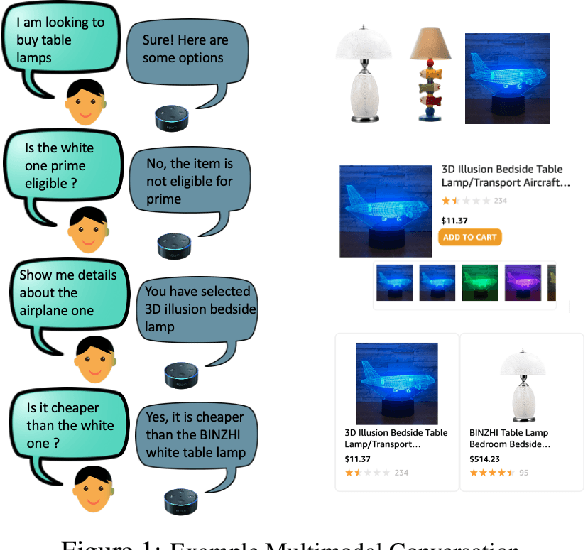
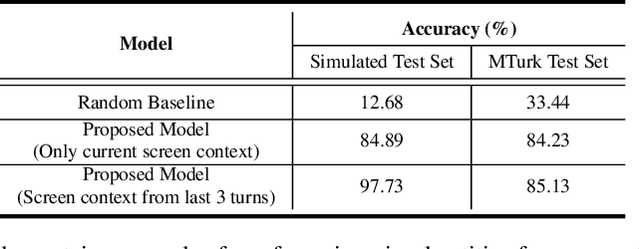
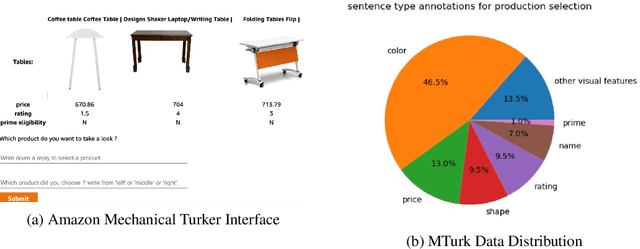
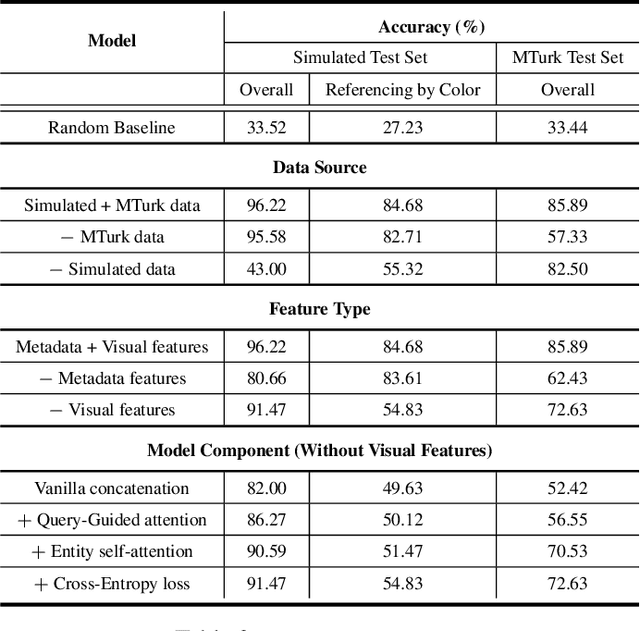
Most popular goal-oriented dialogue agents are capable of understanding the conversational context. However, with the surge of virtual assistants with screen, the next generation of agents are required to also understand screen context in order to provide a proper interactive experience, and better understand users' goals. In this paper, we propose a novel multimodal conversational framework, where the dialogue agent's next action and their arguments are derived jointly conditioned both on the conversational and the visual context. Specifically, we propose a new model, that can reason over the visual context within a conversation and populate API arguments with visual entities given the user query. Our model can recognize visual features such as color and shape as well as the metadata based features such as price or star rating associated with a visual entity. In order to train our model, due to a lack of suitable multimodal conversational datasets, we also propose a novel multimodal dialog simulator to generate synthetic data and also collect realistic user data from MTurk to improve model robustness. The proposed model achieves a reasonable 85% model accuracy, without high inference latency. We also demonstrate the proposed approach in a prototypical furniture shopping experience for a multimodal virtual assistant.
Alexa Conversations: An Extensible Data-driven Approach for Building Task-oriented Dialogue Systems
Apr 19, 2021
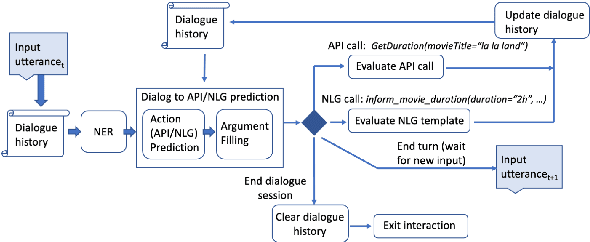

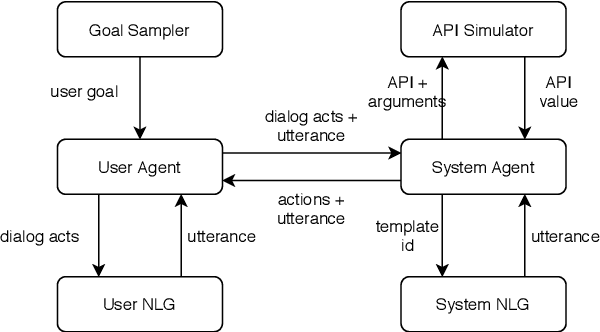
Traditional goal-oriented dialogue systems rely on various components such as natural language understanding, dialogue state tracking, policy learning and response generation. Training each component requires annotations which are hard to obtain for every new domain, limiting scalability of such systems. Similarly, rule-based dialogue systems require extensive writing and maintenance of rules and do not scale either. End-to-End dialogue systems, on the other hand, do not require module-specific annotations but need a large amount of data for training. To overcome these problems, in this demo, we present Alexa Conversations, a new approach for building goal-oriented dialogue systems that is scalable, extensible as well as data efficient. The components of this system are trained in a data-driven manner, but instead of collecting annotated conversations for training, we generate them using a novel dialogue simulator based on a few seed dialogues and specifications of APIs and entities provided by the developer. Our approach provides out-of-the-box support for natural conversational phenomena like entity sharing across turns or users changing their mind during conversation without requiring developers to provide any such dialogue flows. We exemplify our approach using a simple pizza ordering task and showcase its value in reducing the developer burden for creating a robust experience. Finally, we evaluate our system using a typical movie ticket booking task and show that the dialogue simulator is an essential component of the system that leads to over $50\%$ improvement in turn-level action signature prediction accuracy.