 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMockingBERT: A Method for Retroactively Adding Resilience to NLP Models
Paper and Code
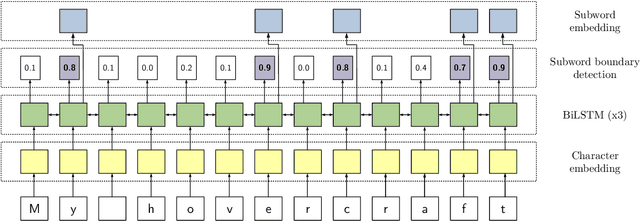
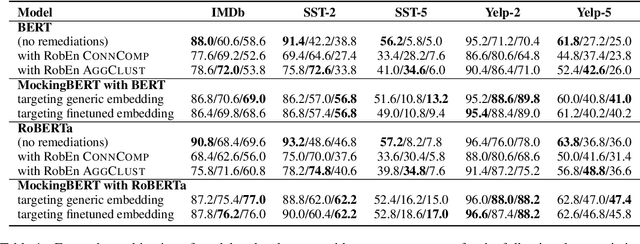
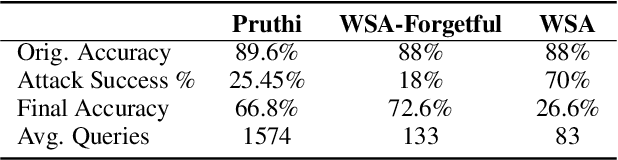
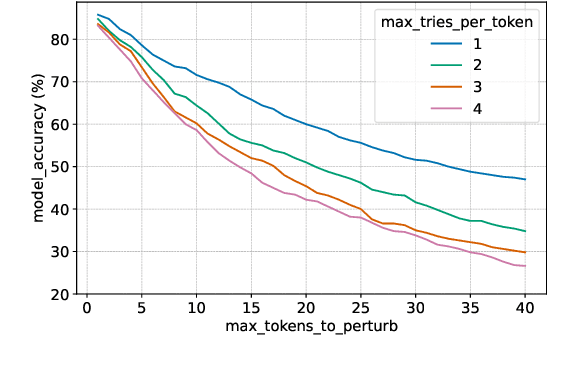
Protecting NLP models against misspellings whether accidental or adversarial has been the object of research interest for the past few years. Existing remediations have typically either compromised accuracy or required full model re-training with each new class of attacks. We propose a novel method of retroactively adding resilience to misspellings to transformer-based NLP models. This robustness can be achieved without the need for re-training of the original NLP model and with only a minimal loss of language understanding performance on inputs without misspellings. Additionally we propose a new efficient approximate method of generating adversarial misspellings, which significantly reduces the cost needed to evaluate a model's resilience to adversarial attacks.