 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Generative Models for 3D Occupancy Prediction in Autonomous Driving
May 29, 2025Accurately predicting 3D occupancy grids from visual inputs is critical for autonomous driving, but current discriminative methods struggle with noisy data, incomplete observations, and the complex structures inherent in 3D scenes. In this work, we reframe 3D occupancy prediction as a generative modeling task using diffusion models, which learn the underlying data distribution and incorporate 3D scene priors. This approach enhances prediction consistency, noise robustness, and better handles the intricacies of 3D spatial structures. Our extensive experiments show that diffusion-based generative models outperform state-of-the-art discriminative approaches, delivering more realistic and accurate occupancy predictions, especially in occluded or low-visibility regions. Moreover, the improved predictions significantly benefit downstream planning tasks, highlighting the practical advantages of our method for real-world autonomous driving applications.
TrackOcc: Camera-based 4D Panoptic Occupancy Tracking
Mar 11, 2025Comprehensive and consistent dynamic scene understanding from camera input is essential for advanced autonomous systems. Traditional camera-based perception tasks like 3D object tracking and semantic occupancy prediction lack either spatial comprehensiveness or temporal consistency. In this work, we introduce a brand-new task, Camera-based 4D Panoptic Occupancy Tracking, which simultaneously addresses panoptic occupancy segmentation and object tracking from camera-only input. Furthermore, we propose TrackOcc, a cutting-edge approach that processes image inputs in a streaming, end-to-end manner with 4D panoptic queries to address the proposed task. Leveraging the localization-aware loss, TrackOcc enhances the accuracy of 4D panoptic occupancy tracking without bells and whistles. Experimental results demonstrate that our method achieves state-of-the-art performance on the Waymo dataset. The source code will be released at https://github.com/Tsinghua-MARS-Lab/TrackOcc.
SceneCraft: Layout-Guided 3D Scene Generation
Oct 11, 2024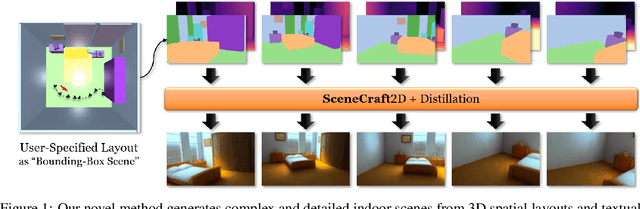


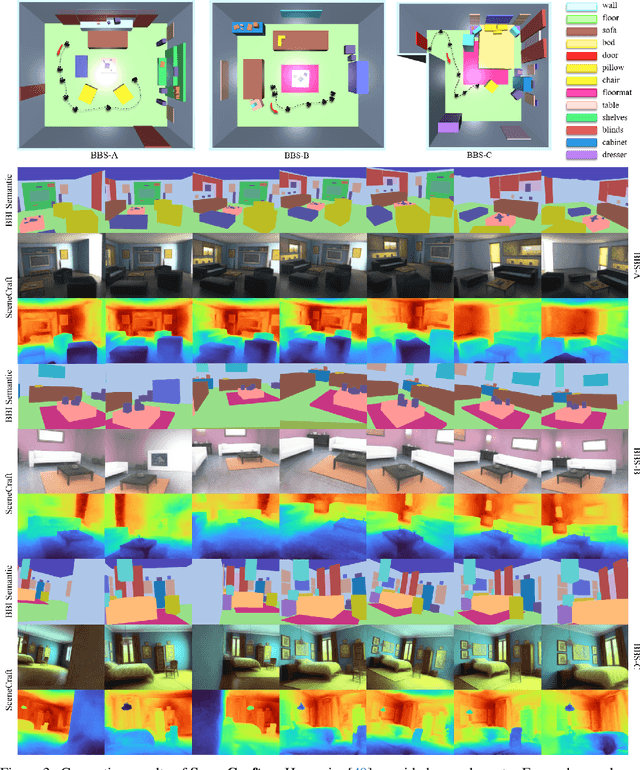
The creation of complex 3D scenes tailored to user specifications has been a tedious and challenging task with traditional 3D modeling tools. Although some pioneering methods have achieved automatic text-to-3D generation, they are generally limited to small-scale scenes with restricted control over the shape and texture. We introduce SceneCraft, a novel method for generating detailed indoor scenes that adhere to textual descriptions and spatial layout preferences provided by users. Central to our method is a rendering-based technique, which converts 3D semantic layouts into multi-view 2D proxy maps. Furthermore, we design a semantic and depth conditioned diffusion model to generate multi-view images, which are used to learn a neural radiance field (NeRF) as the final scene representation. Without the constraints of panorama image generation, we surpass previous methods in supporting complicated indoor space generation beyond a single room, even as complicated as a whole multi-bedroom apartment with irregular shapes and layouts. Through experimental analysis, we demonstrate that our method significantly outperforms existing approaches in complex indoor scene generation with diverse textures, consistent geometry, and realistic visual quality. Code and more results are available at: https://orangesodahub.github.io/SceneCraft
RMMDet: Road-Side Multitype and Multigroup Sensor Detection System for Autonomous Driving
Mar 10, 2023Autonomous driving has now made great strides thanks to artificial intelligence, and numerous advanced methods have been proposed for vehicle end target detection, including single sensor or multi sensor detection methods. However, the complexity and diversity of real traffic situations necessitate an examination of how to use these methods in real road conditions. In this paper, we propose RMMDet, a road-side multitype and multigroup sensor detection system for autonomous driving. We use a ROS-based virtual environment to simulate real-world conditions, in particular the physical and functional construction of the sensors. Then we implement muti-type sensor detection and multi-group sensors fusion in this environment, including camera-radar and camera-lidar detection based on result-level fusion. We produce local datasets and real sand table field, and conduct various experiments. Furthermore, we link a multi-agent collaborative scheduling system to the fusion detection system. Hence, the whole roadside detection system is formed by roadside perception, fusion detection, and scheduling planning. Through the experiments, it can be seen that RMMDet system we built plays an important role in vehicle-road collaboration and its optimization. The code and supplementary materials can be found at: https://github.com/OrangeSodahub/RMMDet