 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Fitting Room: Generating Arbitrarily Long Videos of Virtual Try-On from a Single Image -- Technical Preview
Sep 04, 2025We introduce the Virtual Fitting Room (VFR), a novel video generative model that produces arbitrarily long virtual try-on videos. Our VFR models long video generation tasks as an auto-regressive, segment-by-segment generation process, eliminating the need for resource-intensive generation and lengthy video data, while providing the flexibility to generate videos of arbitrary length. The key challenges of this task are twofold: ensuring local smoothness between adjacent segments and maintaining global temporal consistency across different segments. To address these challenges, we propose our VFR framework, which ensures smoothness through a prefix video condition and enforces consistency with the anchor video -- a 360-degree video that comprehensively captures the human's wholebody appearance. Our VFR generates minute-scale virtual try-on videos with both local smoothness and global temporal consistency under various motions, making it a pioneering work in long virtual try-on video generation.
Dress&Dance: Dress up and Dance as You Like It - Technical Preview
Aug 28, 2025We present Dress&Dance, a video diffusion framework that generates high quality 5-second-long 24 FPS virtual try-on videos at 1152x720 resolution of a user wearing desired garments while moving in accordance with a given reference video. Our approach requires a single user image and supports a range of tops, bottoms, and one-piece garments, as well as simultaneous tops and bottoms try-on in a single pass. Key to our framework is CondNet, a novel conditioning network that leverages attention to unify multi-modal inputs (text, images, and videos), thereby enhancing garment registration and motion fidelity. CondNet is trained on heterogeneous training data, combining limited video data and a larger, more readily available image dataset, in a multistage progressive manner. Dress&Dance outperforms existing open source and commercial solutions and enables a high quality and flexible try-on experience.
V2Edit: Versatile Video Diffusion Editor for Videos and 3D Scenes
Mar 13, 2025



This paper introduces V$^2$Edit, a novel training-free framework for instruction-guided video and 3D scene editing. Addressing the critical challenge of balancing original content preservation with editing task fulfillment, our approach employs a progressive strategy that decomposes complex editing tasks into a sequence of simpler subtasks. Each subtask is controlled through three key synergistic mechanisms: the initial noise, noise added at each denoising step, and cross-attention maps between text prompts and video content. This ensures robust preservation of original video elements while effectively applying the desired edits. Beyond its native video editing capability, we extend V$^2$Edit to 3D scene editing via a "render-edit-reconstruct" process, enabling high-quality, 3D-consistent edits even for tasks involving substantial geometric changes such as object insertion. Extensive experiments demonstrate that our V$^2$Edit achieves high-quality and successful edits across various challenging video editing tasks and complex 3D scene editing tasks, thereby establishing state-of-the-art performance in both domains.
ProEdit: Simple Progression is All You Need for High-Quality 3D Scene Editing
Nov 07, 2024



This paper proposes ProEdit - a simple yet effective framework for high-quality 3D scene editing guided by diffusion distillation in a novel progressive manner. Inspired by the crucial observation that multi-view inconsistency in scene editing is rooted in the diffusion model's large feasible output space (FOS), our framework controls the size of FOS and reduces inconsistency by decomposing the overall editing task into several subtasks, which are then executed progressively on the scene. Within this framework, we design a difficulty-aware subtask decomposition scheduler and an adaptive 3D Gaussian splatting (3DGS) training strategy, ensuring high quality and efficiency in performing each subtask. Extensive evaluation shows that our ProEdit achieves state-of-the-art results in various scenes and challenging editing tasks, all through a simple framework without any expensive or sophisticated add-ons like distillation losses, components, or training procedures. Notably, ProEdit also provides a new way to control, preview, and select the "aggressivity" of editing operation during the editing process.
SceneCraft: Layout-Guided 3D Scene Generation
Oct 11, 2024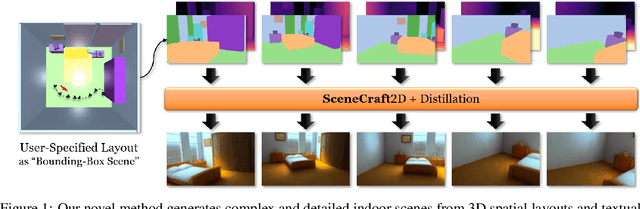


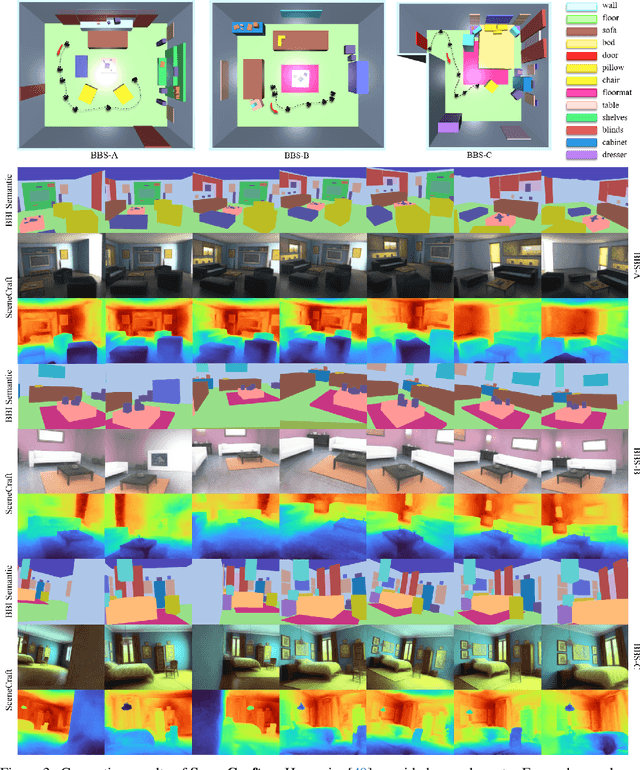
The creation of complex 3D scenes tailored to user specifications has been a tedious and challenging task with traditional 3D modeling tools. Although some pioneering methods have achieved automatic text-to-3D generation, they are generally limited to small-scale scenes with restricted control over the shape and texture. We introduce SceneCraft, a novel method for generating detailed indoor scenes that adhere to textual descriptions and spatial layout preferences provided by users. Central to our method is a rendering-based technique, which converts 3D semantic layouts into multi-view 2D proxy maps. Furthermore, we design a semantic and depth conditioned diffusion model to generate multi-view images, which are used to learn a neural radiance field (NeRF) as the final scene representation. Without the constraints of panorama image generation, we surpass previous methods in supporting complicated indoor space generation beyond a single room, even as complicated as a whole multi-bedroom apartment with irregular shapes and layouts. Through experimental analysis, we demonstrate that our method significantly outperforms existing approaches in complex indoor scene generation with diverse textures, consistent geometry, and realistic visual quality. Code and more results are available at: https://orangesodahub.github.io/SceneCraft
ConsistDreamer: 3D-Consistent 2D Diffusion for High-Fidelity Scene Editing
Jun 13, 2024



This paper proposes ConsistDreamer - a novel framework that lifts 2D diffusion models with 3D awareness and 3D consistency, thus enabling high-fidelity instruction-guided scene editing. To overcome the fundamental limitation of missing 3D consistency in 2D diffusion models, our key insight is to introduce three synergetic strategies that augment the input of the 2D diffusion model to become 3D-aware and to explicitly enforce 3D consistency during the training process. Specifically, we design surrounding views as context-rich input for the 2D diffusion model, and generate 3D-consistent, structured noise instead of image-independent noise. Moreover, we introduce self-supervised consistency-enforcing training within the per-scene editing procedure. Extensive evaluation shows that our ConsistDreamer achieves state-of-the-art performance for instruction-guided scene editing across various scenes and editing instructions, particularly in complicated large-scale indoor scenes from ScanNet++, with significantly improved sharpness and fine-grained textures. Notably, ConsistDreamer stands as the first work capable of successfully editing complex (e.g., plaid/checkered) patterns. Our project page is at immortalco.github.io/ConsistDreamer.
Instruct 4D-to-4D: Editing 4D Scenes as Pseudo-3D Scenes Using 2D Diffusion
Jun 13, 2024This paper proposes Instruct 4D-to-4D that achieves 4D awareness and spatial-temporal consistency for 2D diffusion models to generate high-quality instruction-guided dynamic scene editing results. Traditional applications of 2D diffusion models in dynamic scene editing often result in inconsistency, primarily due to their inherent frame-by-frame editing methodology. Addressing the complexities of extending instruction-guided editing to 4D, our key insight is to treat a 4D scene as a pseudo-3D scene, decoupled into two sub-problems: achieving temporal consistency in video editing and applying these edits to the pseudo-3D scene. Following this, we first enhance the Instruct-Pix2Pix (IP2P) model with an anchor-aware attention module for batch processing and consistent editing. Additionally, we integrate optical flow-guided appearance propagation in a sliding window fashion for more precise frame-to-frame editing and incorporate depth-based projection to manage the extensive data of pseudo-3D scenes, followed by iterative editing to achieve convergence. We extensively evaluate our approach in various scenes and editing instructions, and demonstrate that it achieves spatially and temporally consistent editing results, with significantly enhanced detail and sharpness over the prior art. Notably, Instruct 4D-to-4D is general and applicable to both monocular and challenging multi-camera scenes. Code and more results are available at immortalco.github.io/Instruct-4D-to-4D.
NeuralEditor: Editing Neural Radiance Fields via Manipulating Point Clouds
May 04, 2023This paper proposes NeuralEditor that enables neural radiance fields (NeRFs) natively editable for general shape editing tasks. Despite their impressive results on novel-view synthesis, it remains a fundamental challenge for NeRFs to edit the shape of the scene. Our key insight is to exploit the explicit point cloud representation as the underlying structure to construct NeRFs, inspired by the intuitive interpretation of NeRF rendering as a process that projects or "plots" the associated 3D point cloud to a 2D image plane. To this end, NeuralEditor introduces a novel rendering scheme based on deterministic integration within K-D tree-guided density-adaptive voxels, which produces both high-quality rendering results and precise point clouds through optimization. NeuralEditor then performs shape editing via mapping associated points between point clouds. Extensive evaluation shows that NeuralEditor achieves state-of-the-art performance in both shape deformation and scene morphing tasks. Notably, NeuralEditor supports both zero-shot inference and further fine-tuning over the edited scene. Our code, benchmark, and demo video are available at https://immortalco.github.io/NeuralEditor.
PointTree: Transformation-Robust Point Cloud Encoder with Relaxed K-D Trees
Aug 11, 2022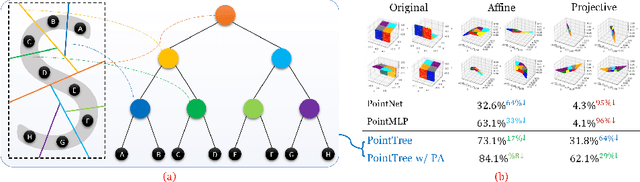

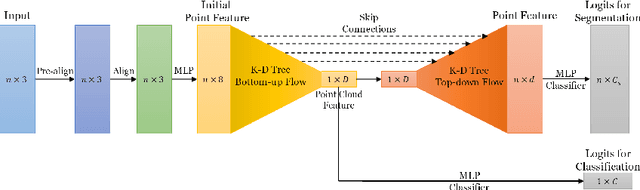

Being able to learn an effective semantic representation directly on raw point clouds has become a central topic in 3D understanding. Despite rapid progress, state-of-the-art encoders are restrictive to canonicalized point clouds, and have weaker than necessary performance when encountering geometric transformation distortions. To overcome this challenge, we propose PointTree, a general-purpose point cloud encoder that is robust to transformations based on relaxed K-D trees. Key to our approach is the design of the division rule in K-D trees by using principal component analysis (PCA). We use the structure of the relaxed K-D tree as our computational graph, and model the features as border descriptors which are merged with pointwise-maximum operation. In addition to this novel architecture design, we further improve the robustness by introducing pre-alignment -- a simple yet effective PCA-based normalization scheme. Our PointTree encoder combined with pre-alignment consistently outperforms state-of-the-art methods by large margins, for applications from object classification to semantic segmentation on various transformed versions of the widely-benchmarked datasets. Code and pre-trained models are available at https://github.com/immortalCO/PointTree.