 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWRICNet:A Weighted Rich-scale Inception Coder Network for Multi-Resolution Remote Sensing Image Change Detection
Aug 18, 2021

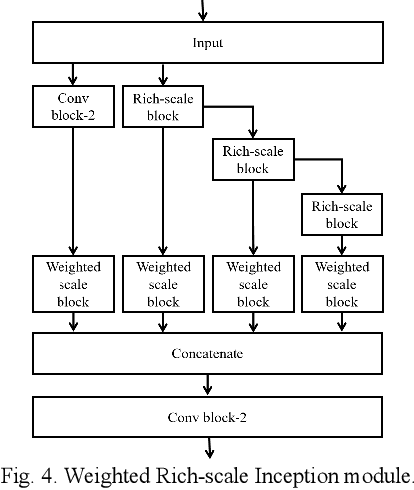
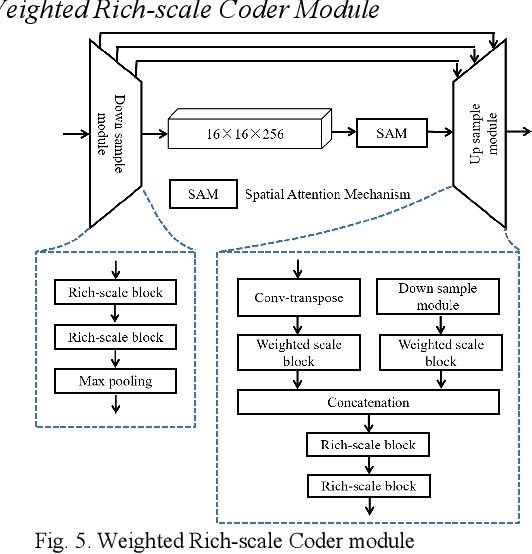
Majority models of remote sensing image changing detection can only get great effect in a specific resolution data set. With the purpose of improving change detection effectiveness of the model in the multi-resolution data set, a weighted rich-scale inception coder network (WRICNet) is proposed in this article, which can make a great fusion of shallow multi-scale features, and deep multi-scale features. The weighted rich-scale inception module of the proposed can obtain shallow multi-scale features, the weighted rich-scale coder module can obtain deep multi-scale features. The weighted scale block assigns appropriate weights to features of different scales, which can strengthen expressive ability of the edge of the changing area. The performance experiments on the multi-resolution data set demonstrate that, compared to the comparative methods, the proposed can further reduce the false alarm outside the change area, and the missed alarm in the change area, besides, the edge of the change area is more accurate. The ablation study of the proposed shows that the training strategy, and improvements of this article can improve the effectiveness of change detection.
A Compact DNN: Approaching GoogLeNet-Level Accuracy of Classification and Domain Adaptation
Apr 03, 2017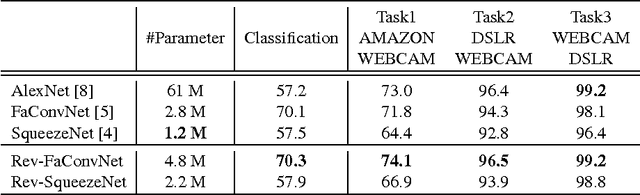
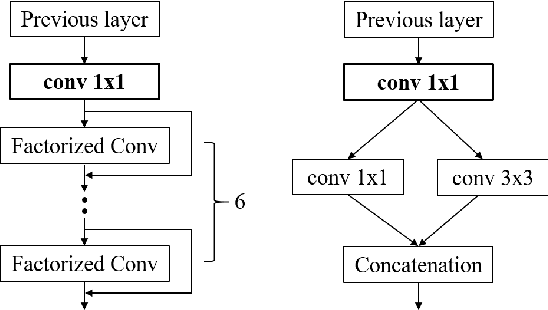
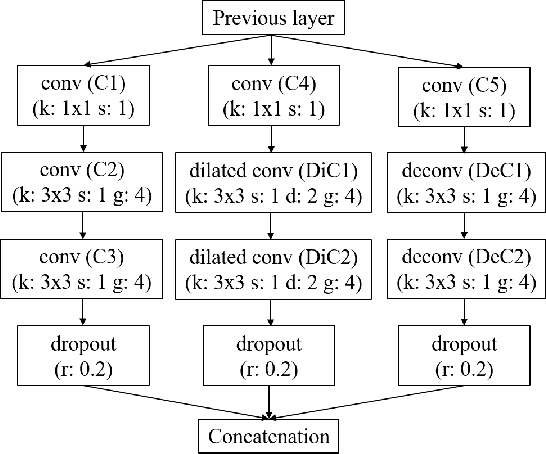
Recently, DNN model compression based on network architecture design, e.g., SqueezeNet, attracted a lot attention. No accuracy drop on image classification is observed on these extremely compact networks, compared to well-known models. An emerging question, however, is whether these model compression techniques hurt DNN's learning ability other than classifying images on a single dataset. Our preliminary experiment shows that these compression methods could degrade domain adaptation (DA) ability, though the classification performance is preserved. Therefore, we propose a new compact network architecture and unsupervised DA method in this paper. The DNN is built on a new basic module Conv-M which provides more diverse feature extractors without significantly increasing parameters. The unified framework of our DA method will simultaneously learn invariance across domains, reduce divergence of feature representations, and adapt label prediction. Our DNN has 4.1M parameters, which is only 6.7% of AlexNet or 59% of GoogLeNet. Experiments show that our DNN obtains GoogLeNet-level accuracy both on classification and DA, and our DA method slightly outperforms previous competitive ones. Put all together, our DA strategy based on our DNN achieves state-of-the-art on sixteen of total eighteen DA tasks on popular Office-31 and Office-Caltech datasets.