 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERA: Hybrid Edge-cloud Resource Allocation for Cost-Efficient AI Agents
Apr 01, 2025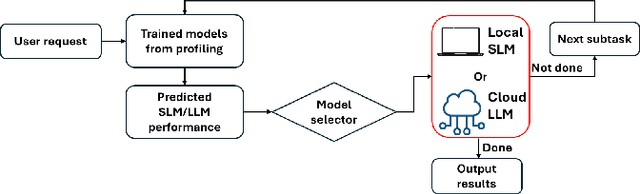

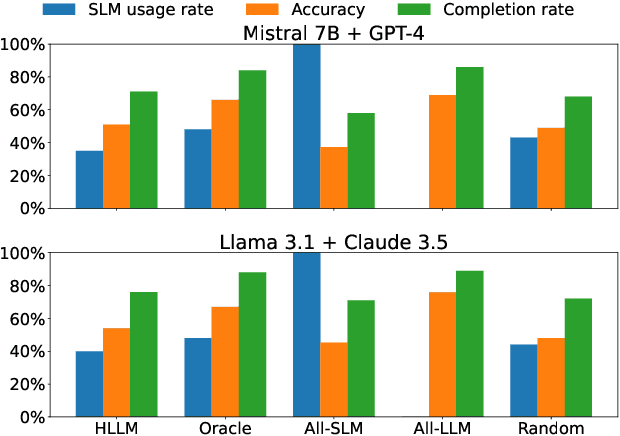
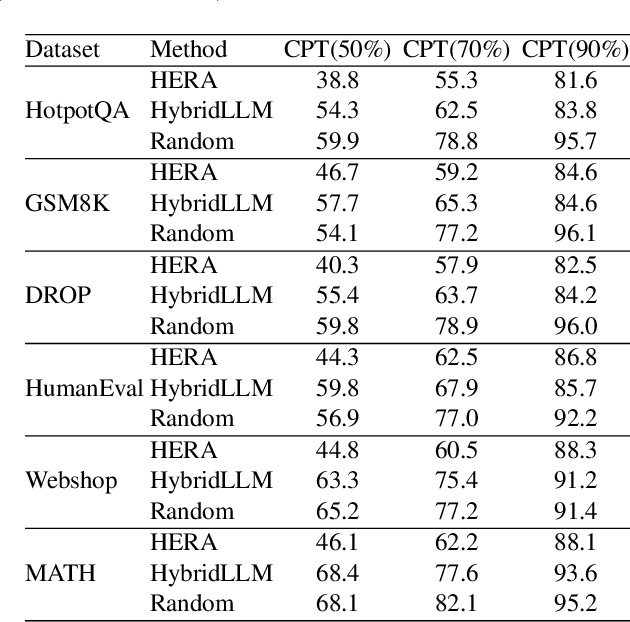
In the realm of AI, large language models (LLMs) like GPT-4, central to the operation of AI agents, predominantly operate in the cloud, incurring high operational costs. With local-based small language models (SLMs) becoming more accurate, the necessity of cloud-exclusive processing is being reconsidered. An AI agent's response to a user's request comprises a series of subtasks or iterations. Existing approaches only allocate a single request between SLM and LLM to ensure their outputs are similar, but adopting this approach in the AI agent scenario for assigning each subtask is not effective since SLM will output a different subsequent subtask, which affects the accuracy of the final output. In this paper, we first conduct experimental analysis to understand the features of AI agent operations. Leveraging our findings, we propose the Adaptive Iteration-level Model Selector (AIMS), a lightweight scheduler to automatically partition AI agent's subtasks between local-based SLM and cloud-based LLM. AIMS considers the varying subtask features and strategically decides the location for each subtask in order to use SLM as much as possible while attaining the accuracy level. Our experimental results demonstrate that AIMS increases accuracy by up to 9.1% and SLM usage by up to 10.8% compared to HybridLLM. It offloads 45.67% of subtasks to a local SLM while attaining similar accuracy on average compared with the cloud-only LLM approach.
DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales
Aug 02, 2023
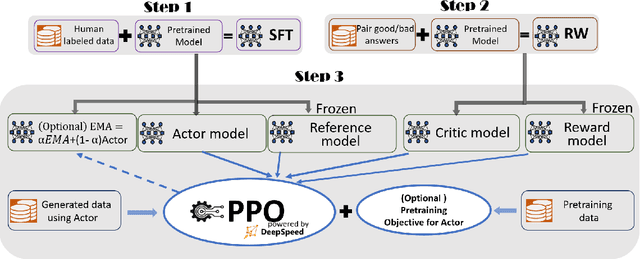

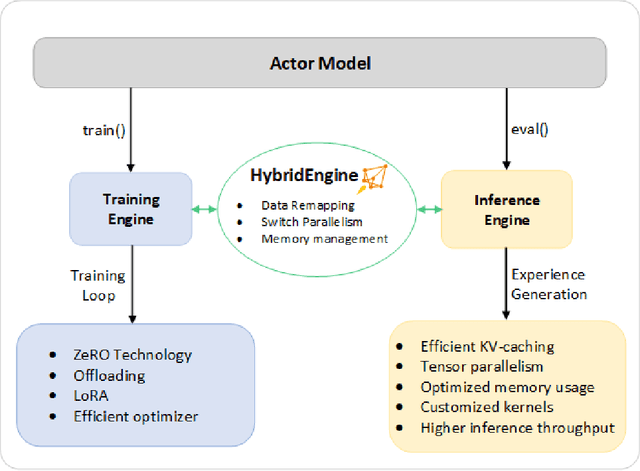
ChatGPT-like models have revolutionized various applications in artificial intelligence, from summarization and coding to translation, matching or even surpassing human performance. However, the current landscape lacks an accessible, efficient, and cost-effective end-to-end RLHF (Reinforcement Learning with Human Feedback) training pipeline for these powerful models, particularly when training at the scale of billions of parameters. This paper introduces DeepSpeed-Chat, a novel system that democratizes RLHF training, making it accessible to the AI community. DeepSpeed-Chat offers three key capabilities: an easy-to-use training and inference experience for ChatGPT-like models, a DeepSpeed-RLHF pipeline that replicates the training pipeline from InstructGPT, and a robust DeepSpeed-RLHF system that combines various optimizations for training and inference in a unified way. The system delivers unparalleled efficiency and scalability, enabling training of models with hundreds of billions of parameters in record time and at a fraction of the cost. With this development, DeepSpeed-Chat paves the way for broader access to advanced RLHF training, even for data scientists with limited resources, thereby fostering innovation and further development in the field of AI.
Software-Defined Design Space Exploration for an Efficient AI Accelerator Architecture
Mar 18, 2019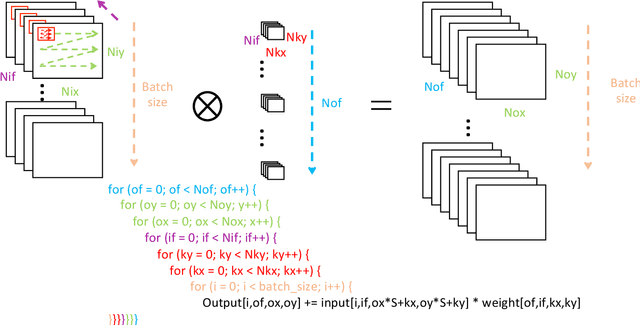


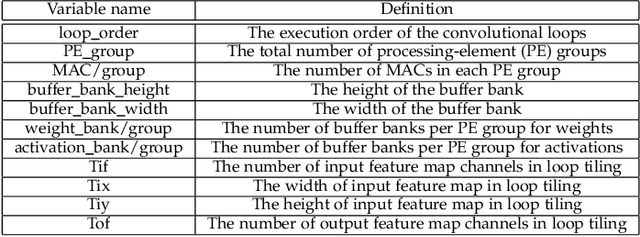
Deep neural networks (DNNs) have been shown to outperform conventional machine learning algorithms across a wide range of applications, e.g., image recognition, object detection, robotics, and natural language processing. However, the high computational complexity of DNNs often necessitates extremely fast and efficient hardware. The problem gets worse as the size of neural networks grows exponentially. As a result, customized hardware accelerators have been developed to accelerate DNN processing without sacrificing model accuracy. However, previous accelerator design studies have not fully considered the characteristics of the target applications, which may lead to sub-optimal architecture designs. On the other hand, new DNN models have been developed for better accuracy, but their compatibility with the underlying hardware accelerator is often overlooked. In this article, we propose an application-driven framework for architectural design space exploration of DNN accelerators. This framework is based on a hardware analytical model of individual DNN operations. It models the accelerator design task as a multi-dimensional optimization problem. We demonstrate that it can be efficaciously used in application-driven accelerator architecture design. Given a target DNN, the framework can generate efficient accelerator design solutions with optimized performance and area. Furthermore, we explore the opportunity to use the framework for accelerator configuration optimization under simultaneous diverse DNN applications. The framework is also capable of improving neural network models to best fit the underlying hardware resources.
Hardware-Guided Symbiotic Training for Compact, Accurate, yet Execution-Efficient LSTM
Jan 30, 2019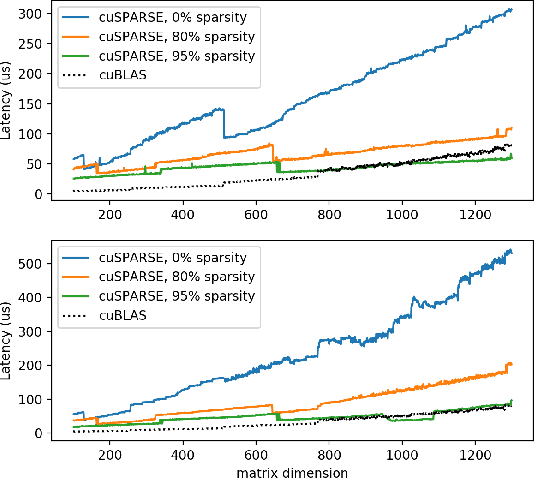
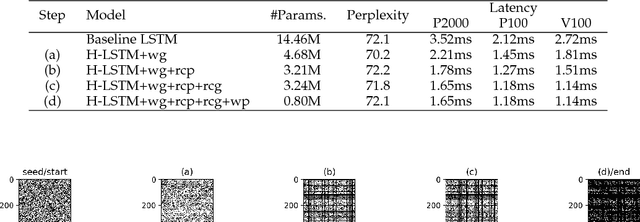
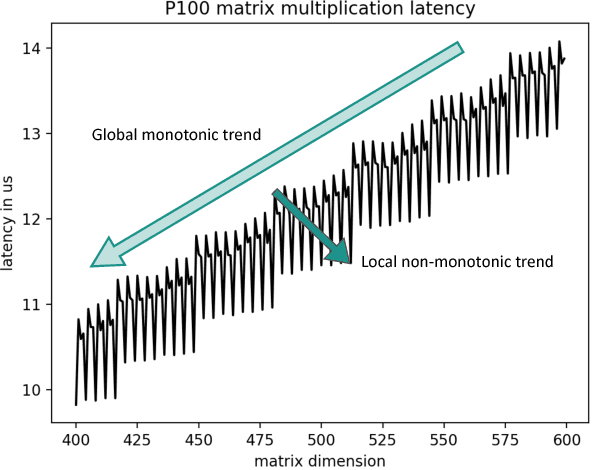
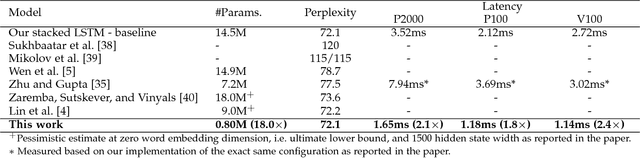
Many long short-term memory (LSTM) applications need fast yet compact models. Neural network compression approaches, such as the grow-and-prune paradigm, have proved to be promising for cutting down network complexity by skipping insignificant weights. However, current compression strategies are mostly hardware-agnostic and network complexity reduction does not always translate into execution efficiency. In this work, we propose a hardware-guided symbiotic training methodology for compact, accurate, yet execution-efficient inference models. It is based on our observation that hardware may introduce substantial non-monotonic behavior, which we call the latency hysteresis effect, when evaluating network size vs. inference latency. This observation raises question about the mainstream smaller-dimension-is-better compression strategy, which often leads to a sub-optimal model architecture. By leveraging the hardware-impacted hysteresis effect and sparsity, we are able to achieve the symbiosis of model compactness and accuracy with execution efficiency, thus reducing LSTM latency while increasing its accuracy. We have evaluated our algorithms on language modeling and speech recognition applications. Relative to the traditional stacked LSTM architecture obtained for the Penn Treebank dataset, we reduce the number of parameters by 18.0x (30.5x) and measured run-time latency by up to 2.4x (5.2x) on Nvidia GPUs (Intel Xeon CPUs) without any accuracy degradation. For the DeepSpeech2 architecture obtained for the AN4 dataset, we reduce the number of parameters by 7.0x (19.4x), word error rate from 12.9% to 9.9% (10.4%), and measured run-time latency by up to 1.7x (2.4x) on Nvidia GPUs (Intel Xeon CPUs). Thus, our method yields compact, accurate, yet execution-efficient inference models.