 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGFuse: An Infrared and Visible Image Fusion Approach Based on Transformer and Generative Adversarial Network
Feb 04, 2022
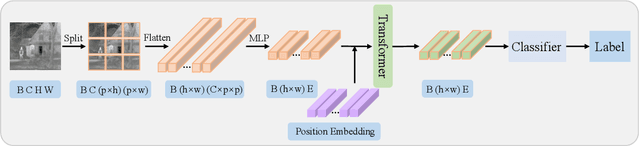


The end-to-end image fusion framework has achieved promising performance, with dedicated convolutional networks aggregating the multi-modal local appearance. However, long-range dependencies are directly neglected in existing CNN fusion approaches, impeding balancing the entire image-level perception for complex scenario fusion. In this paper, therefore, we propose an infrared and visible image fusion algorithm based on a lightweight transformer module and adversarial learning. Inspired by the global interaction power, we use the transformer technique to learn the effective global fusion relations. In particular, shallow features extracted by CNN are interacted in the proposed transformer fusion module to refine the fusion relationship within the spatial scope and across channels simultaneously. Besides, adversarial learning is designed in the training process to improve the output discrimination via imposing competitive consistency from the inputs, reflecting the specific characteristics in infrared and visible images. The experimental performance demonstrates the effectiveness of the proposed modules, with superior improvement against the state-of-the-art, generalising a novel paradigm via transformer and adversarial learning in the fusion task.
Unsupervised Image Fusion Method based on Feature Mutual Mapping
Jan 29, 2022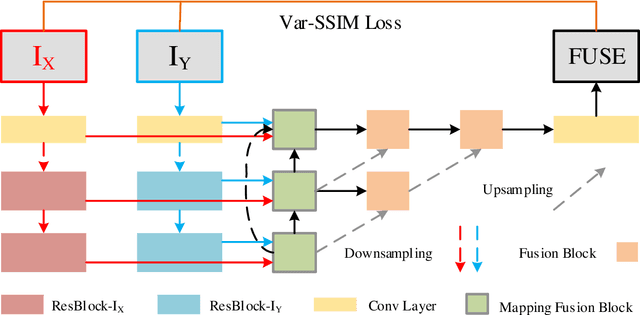
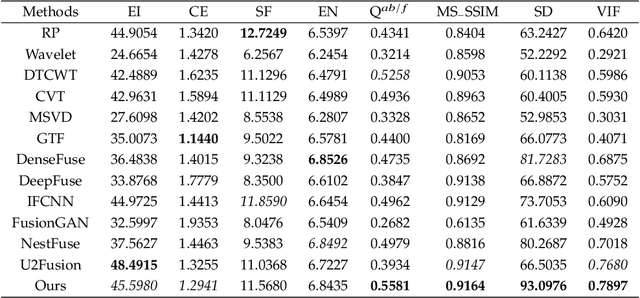
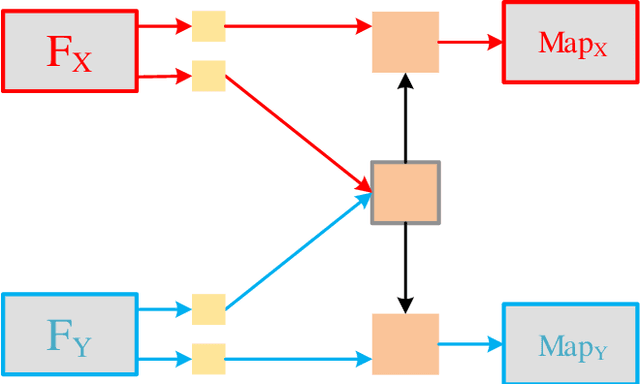
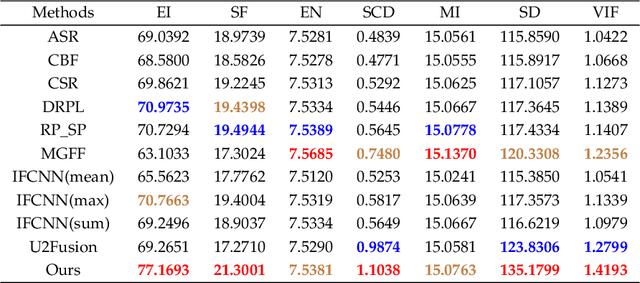
Deep learning-based image fusion approaches have obtained wide attention in recent years, achieving promising performance in terms of visual perception. However, the fusion module in the current deep learning-based methods suffers from two limitations, \textit{i.e.}, manually designed fusion function, and input-independent network learning. In this paper, we propose an unsupervised adaptive image fusion method to address the above issues. We propose a feature mutual mapping fusion module and dual-branch multi-scale autoencoder. More specifically, we construct a global map to measure the connections of pixels between the input source images. % The found mapping relationship guides the image fusion. Besides, we design a dual-branch multi-scale network through sampling transformation to extract discriminative image features. We further enrich feature representations of different scales through feature aggregation in the decoding process. Finally, we propose a modified loss function to train the network with efficient convergence property. Through sufficient training on infrared and visible image data sets, our method also shows excellent generalized performance in multi-focus and medical image fusion. Our method achieves superior performance in both visual perception and objective evaluation. Experiments prove that the performance of our proposed method on a variety of image fusion tasks surpasses other state-of-the-art methods, proving the effectiveness and versatility of our approach.