 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN3H-Core: Neuron-designed Neural Network Accelerator via FPGA-based Heterogeneous Computing Cores
Dec 15, 2021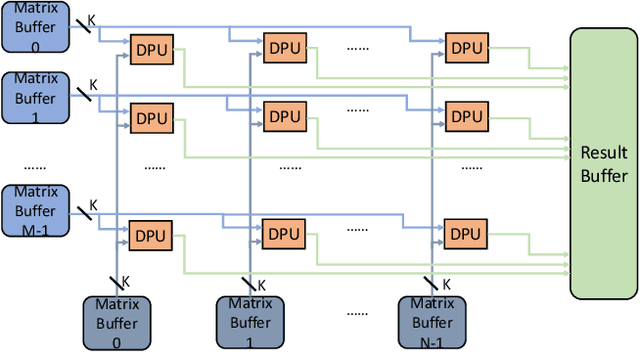
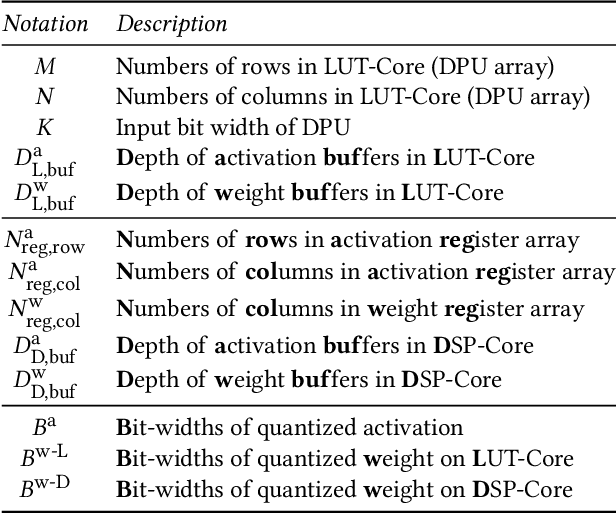
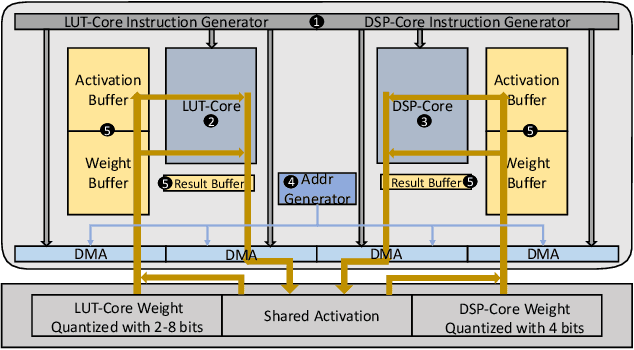
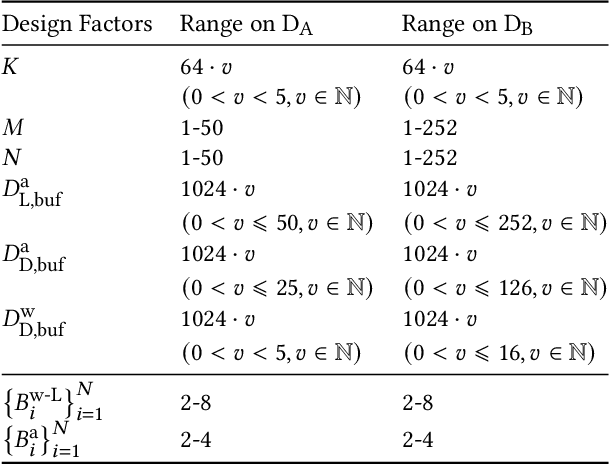
Accelerating the neural network inference by FPGA has emerged as a popular option, since the reconfigurability and high performance computing capability of FPGA intrinsically satisfies the computation demand of the fast-evolving neural algorithms. However, the popular neural accelerators on FPGA (e.g., Xilinx DPU) mainly utilize the DSP resources for constructing their processing units, while the rich LUT resources are not well exploited. Via the software-hardware co-design approach, in this work, we develop an FPGA-based heterogeneous computing system for neural network acceleration. From the hardware perspective, the proposed accelerator consists of DSP- and LUT-based GEneral Matrix-Multiplication (GEMM) computing cores, which forms the entire computing system in a heterogeneous fashion. The DSP- and LUT-based GEMM cores are computed w.r.t a unified Instruction Set Architecture (ISA) and unified buffers. Along the data flow of the neural network inference path, the computation of the convolution/fully-connected layer is split into two portions, handled by the DSP- and LUT-based GEMM cores asynchronously. From the software perspective, we mathematically and systematically model the latency and resource utilization of the proposed heterogeneous accelerator, regarding varying system design configurations. Through leveraging the reinforcement learning technique, we construct a framework to achieve end-to-end selection and optimization of the design specification of target heterogeneous accelerator, including workload split strategy, mixed-precision quantization scheme, and resource allocation of DSP- and LUT-core. In virtue of the proposed design framework and heterogeneous computing system, our design outperforms the state-of-the-art Mix&Match design with latency reduced by 1.12-1.32x with higher inference accuracy. The N3H-core is open-sourced at: https://github.com/elliothe/N3H_Core.