 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Knowledge Reasoning for Knowledge-based Visual Question Answering
Paper and Code
Aug 31, 2020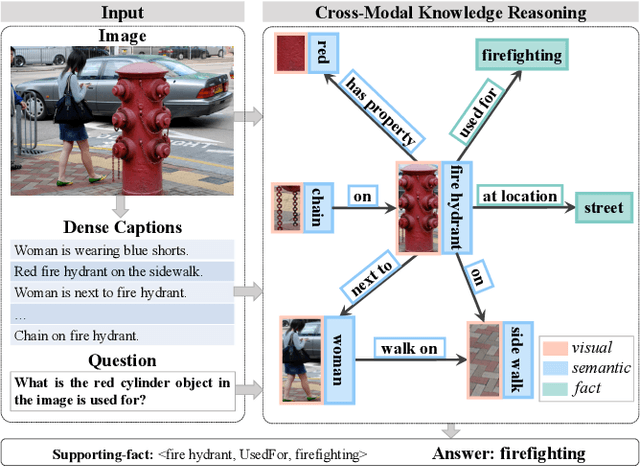
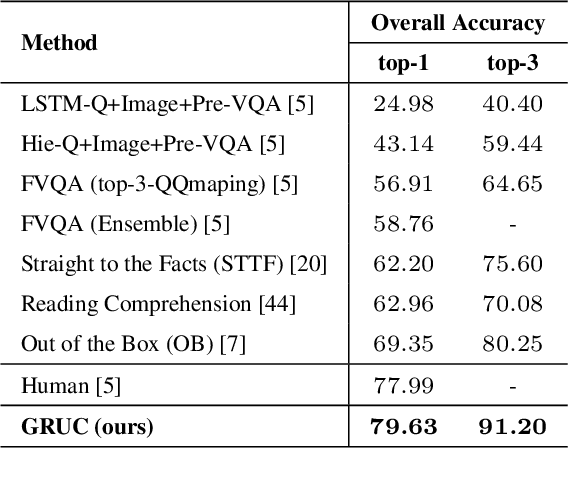

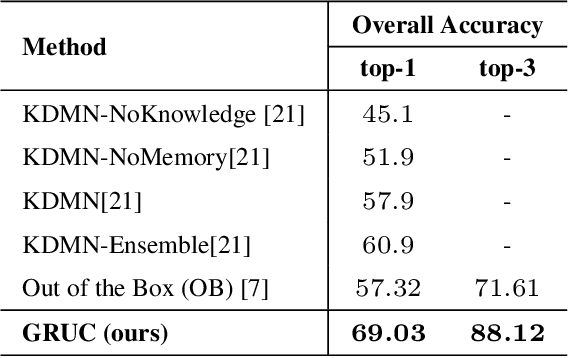
Knowledge-based Visual Question Answering (KVQA) requires external knowledge beyond the visible content to answer questions about an image. This ability is challenging but indispensable to achieve general VQA. One limitation of existing KVQA solutions is that they jointly embed all kinds of information without fine-grained selection, which introduces unexpected noises for reasoning the correct answer. How to capture the question-oriented and information-complementary evidence remains a key challenge to solve the problem. Inspired by the human cognition theory, in this paper, we depict an image by multiple knowledge graphs from the visual, semantic and factual views. Thereinto, the visual graph and semantic graph are regarded as image-conditioned instantiation of the factual graph. On top of these new representations, we re-formulate Knowledge-based Visual Question Answering as a recurrent reasoning process for obtaining complementary evidence from multimodal information. To this end, we decompose the model into a series of memory-based reasoning steps, each performed by a G raph-based R ead, U pdate, and C ontrol ( GRUC ) module that conducts parallel reasoning over both visual and semantic information. By stacking the modules multiple times, our model performs transitive reasoning and obtains question-oriented concept representations under the constrain of different modalities. Finally, we perform graph neural networks to infer the global-optimal answer by jointly considering all the concepts. We achieve a new state-of-the-art performance on three popular benchmark datasets, including FVQA, Visual7W-KB and OK-VQA, and demonstrate the effectiveness and interpretability of our model with extensive experiments.