 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning with Context-Aware Auxiliary Guidance
Jan 04, 2021
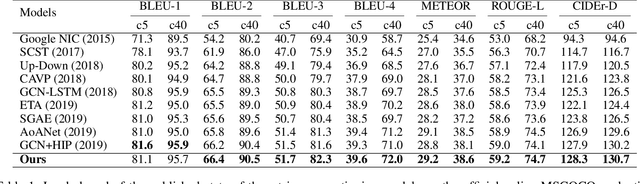
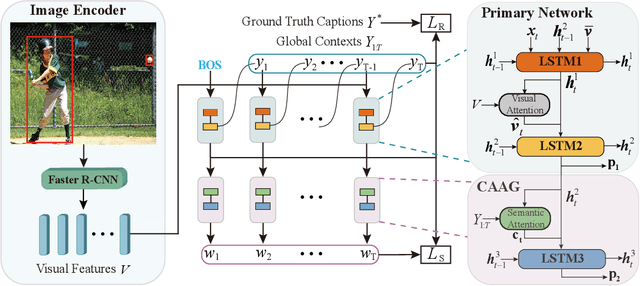

Image captioning is a challenging computer vision task, which aims to generate a natural language description of an image. Most recent researches follow the encoder-decoder framework which depends heavily on the previous generated words for the current prediction. Such methods can not effectively take advantage of the future predicted information to learn complete semantics. In this paper, we propose Context-Aware Auxiliary Guidance (CAAG) mechanism that can guide the captioning model to perceive global contexts. Upon the captioning model, CAAG performs semantic attention that selectively concentrates on useful information of the global predictions to reproduce the current generation. To validate the adaptability of the method, we apply CAAG to three popular captioners and our proposal achieves competitive performance on the challenging Microsoft COCO image captioning benchmark, e.g. 132.2 CIDEr-D score on Karpathy split and 130.7 CIDEr-D (c40) score on official online evaluation server.
Cross-modal Knowledge Reasoning for Knowledge-based Visual Question Answering
Aug 31, 2020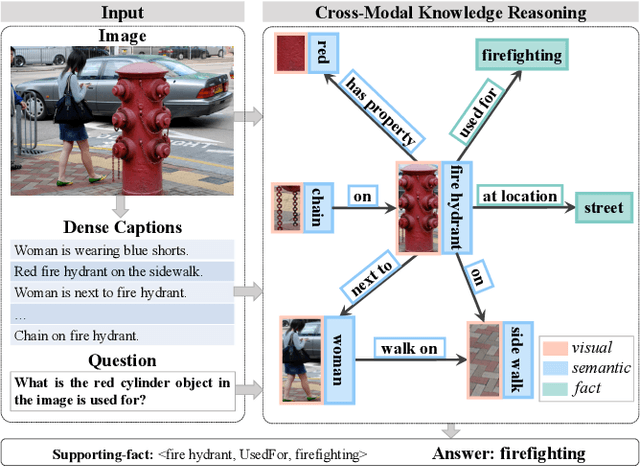
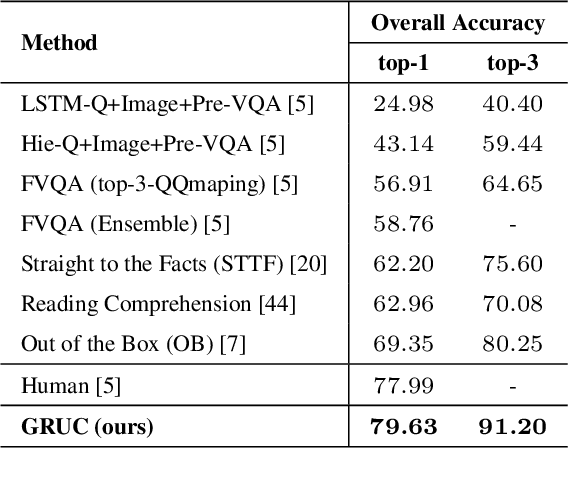

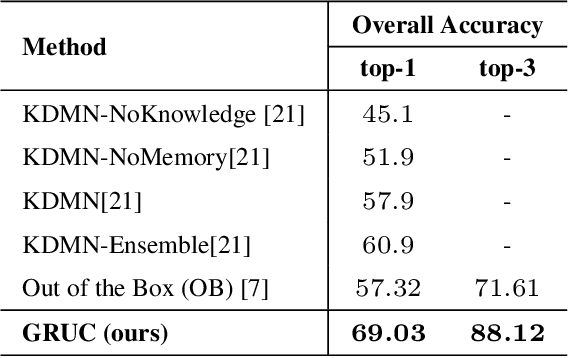
Knowledge-based Visual Question Answering (KVQA) requires external knowledge beyond the visible content to answer questions about an image. This ability is challenging but indispensable to achieve general VQA. One limitation of existing KVQA solutions is that they jointly embed all kinds of information without fine-grained selection, which introduces unexpected noises for reasoning the correct answer. How to capture the question-oriented and information-complementary evidence remains a key challenge to solve the problem. Inspired by the human cognition theory, in this paper, we depict an image by multiple knowledge graphs from the visual, semantic and factual views. Thereinto, the visual graph and semantic graph are regarded as image-conditioned instantiation of the factual graph. On top of these new representations, we re-formulate Knowledge-based Visual Question Answering as a recurrent reasoning process for obtaining complementary evidence from multimodal information. To this end, we decompose the model into a series of memory-based reasoning steps, each performed by a G raph-based R ead, U pdate, and C ontrol ( GRUC ) module that conducts parallel reasoning over both visual and semantic information. By stacking the modules multiple times, our model performs transitive reasoning and obtains question-oriented concept representations under the constrain of different modalities. Finally, we perform graph neural networks to infer the global-optimal answer by jointly considering all the concepts. We achieve a new state-of-the-art performance on three popular benchmark datasets, including FVQA, Visual7W-KB and OK-VQA, and demonstrate the effectiveness and interpretability of our model with extensive experiments.
RLINK: Deep Reinforcement Learning for User Identity Linkage
Oct 31, 2019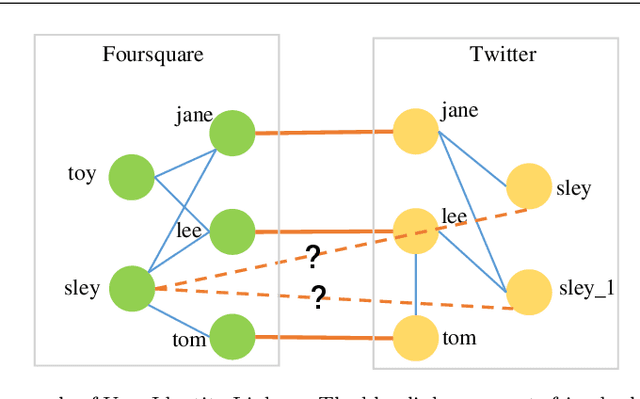
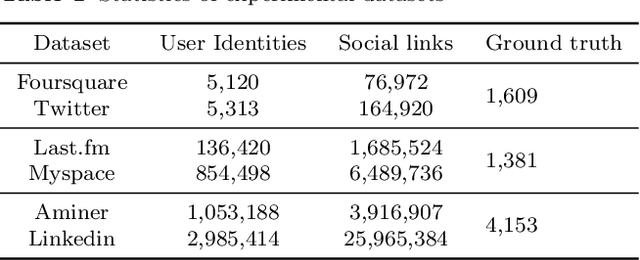
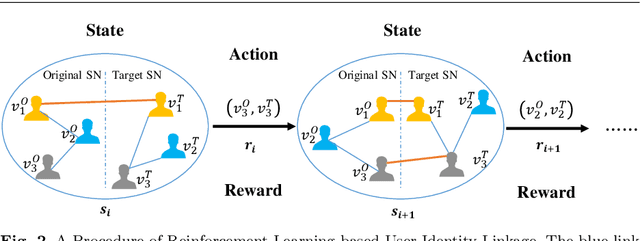
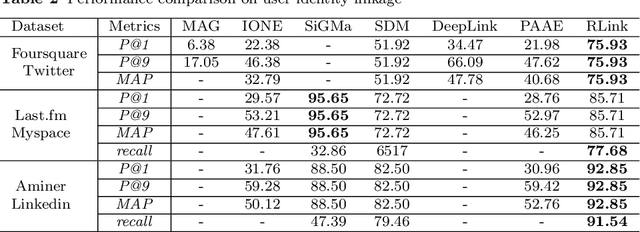
User identity linkage is a task of recognizing the identities of the same user across different social networks (SN). Previous works tackle this problem via estimating the pairwise similarity between identities from different SN, predicting the label of identity pairs or selecting the most relevant identity pair based on the similarity scores. However, most of these methods ignore the results of previously matched identities, which could contribute to the linkage in following matching steps. To address this problem, we convert user identity linkage into a sequence decision problem and propose a reinforcement learning model to optimize the linkage strategy from the global perspective. Our method makes full use of both the social network structure and the history matched identities, and explores the long-term influence of current matching on subsequent decisions. We conduct experiments on different types of datasets, the results show that our method achieves better performance than other state-of-the-art methods.
Deep Active Learning for Anchor User Prediction
Jun 25, 2019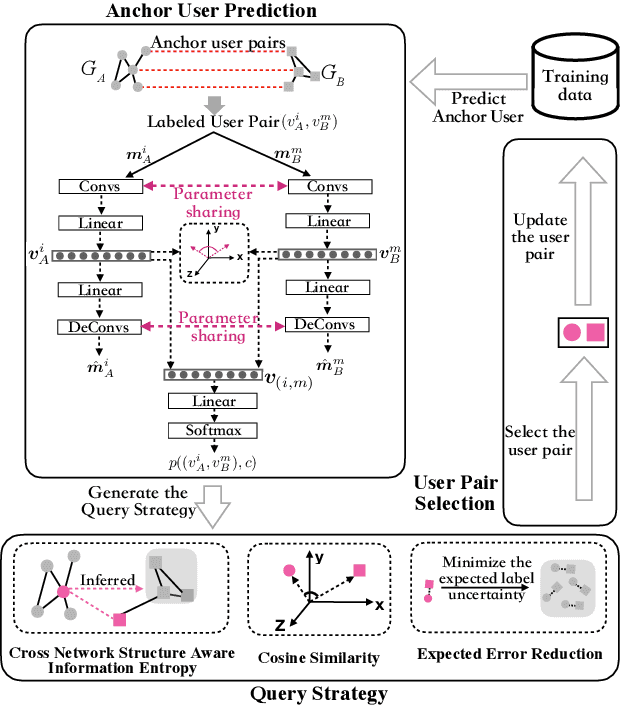
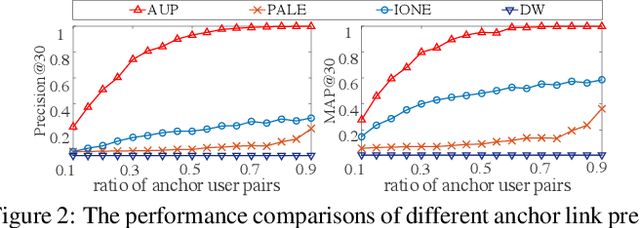
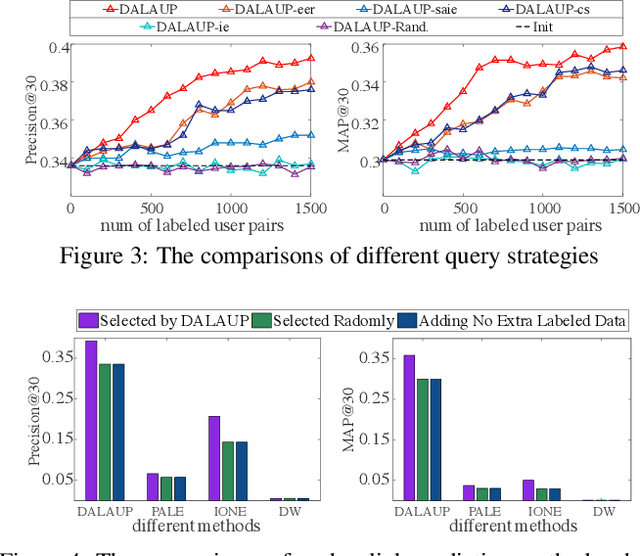
Predicting pairs of anchor users plays an important role in the cross-network analysis. Due to the expensive costs of labeling anchor users for training prediction models, we consider in this paper the problem of minimizing the number of user pairs across multiple networks for labeling as to improve the accuracy of the prediction. To this end, we present a deep active learning model for anchor user prediction (DALAUP for short). However, active learning for anchor user sampling meets the challenges of non-i.i.d. user pair data caused by network structures and the correlation among anchor or non-anchor user pairs. To solve the challenges, DALAUP uses a couple of neural networks with shared-parameter to obtain the vector representations of user pairs, and ensembles three query strategies to select the most informative user pairs for labeling and model training. Experiments on real-world social network data demonstrate that DALAUP outperforms the state-of-the-art approaches.