 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Linear Feature Disentanglement For Neural Networks
Paper and Code
Mar 22, 2022

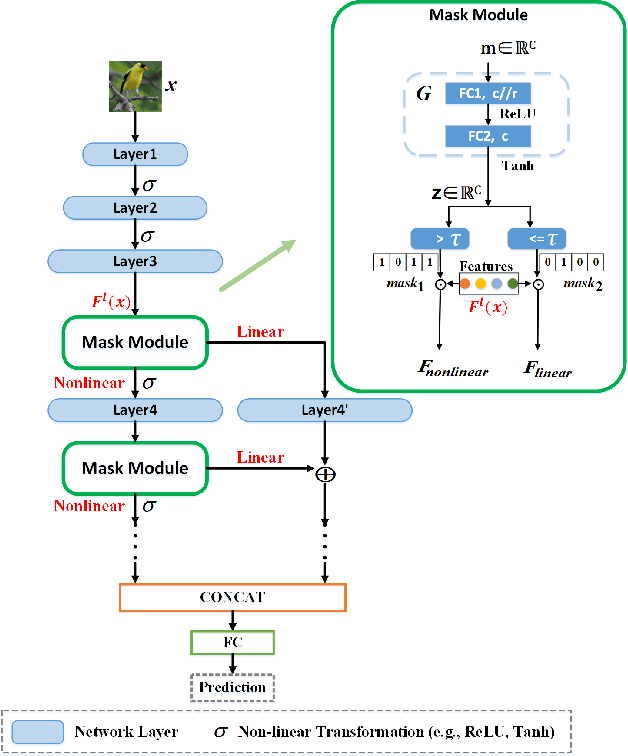

Non-linear activation functions, e.g., Sigmoid, ReLU, and Tanh, have achieved great success in neural networks (NNs). Due to the complex non-linear characteristic of samples, the objective of those activation functions is to project samples from their original feature space to a linear separable feature space. This phenomenon ignites our interest in exploring whether all features need to be transformed by all non-linear functions in current typical NNs, i.e., whether there exists a part of features arriving at the linear separable feature space in the intermediate layers, that does not require further non-linear variation but an affine transformation instead. To validate the above hypothesis, we explore the problem of linear feature disentanglement for neural networks in this paper. Specifically, we devise a learnable mask module to distinguish between linear and non-linear features. Through our designed experiments we found that some features reach the linearly separable space earlier than the others and can be detached partly from the NNs. The explored method also provides a readily feasible pruning strategy which barely affects the performance of the original model. We conduct our experiments on four datasets and present promising results.