 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Authorization: Internalizing Authorization into Large Language Models via Reasoning Trajectories
Mar 24, 2026Large Language Models (LLMs) have become core cognitive components in modern artificial intelligence (AI) systems, combining internal knowledge with external context to perform complex tasks. However, LLMs typically treat all accessible data indiscriminately, lacking inherent awareness of knowledge ownership and access boundaries. This deficiency heightens risks of sensitive data leakage and adversarial manipulation, potentially enabling unauthorized system access and severe security crises. Existing protection strategies rely on rigid, uniform defense that prevent dynamic authorization. Structural isolation methods faces scalability bottlenecks, while prompt guidance methods struggle with fine-grained permissions distinctions. Here, we propose the Chain-of-Authorization (CoA) framework, a secure training and reasoning paradigm that internalizes authorization logic into LLMs' core capabilities. Unlike passive external defneses, CoA restructures the model's information flow: it embeds permission context at input and requires generating explicit authorization reasoning trajectory that includes resource review, identity resolution, and decision-making stages before final response. Through supervised fine-tuning on data covering various authorization status, CoA integrates policy execution with task responses, making authorization a causal prerequisite for substantive responses. Extensive evaluations show that CoA not only maintains comparable utility in authorized scenarios but also overcomes the cognitive confusion when permissions mismatches. It exhibits high rejection rates against various unauthorized and adversarial access. This mechanism leverages LLMs' reasoning capability to perform dynamic authorization, using natural language understanding as a proactive security mechanism for deploying reliable LLMs in modern AI systems.
NetMamba+: A Framework of Pre-trained Models for Efficient and Accurate Network Traffic Classification
Jan 29, 2026With the rapid growth of encrypted network traffic, effective traffic classification has become essential for network security and quality of service management. Current machine learning and deep learning approaches for traffic classification face three critical challenges: computational inefficiency of Transformer architectures, inadequate traffic representations with loss of crucial byte-level features while retaining detrimental biases, and poor handling of long-tail distributions in real-world data. We propose NetMamba+, a framework that addresses these challenges through three key innovations: (1) an efficient architecture considering Mamba and Flash Attention mechanisms, (2) a multimodal traffic representation scheme that preserves essential traffic information while eliminating biases, and (3) a label distribution-aware fine-tuning strategy. Evaluation experiments on massive datasets encompassing four main classification tasks showcase NetMamba+'s superior classification performance compared to state-of-the-art baselines, with improvements of up to 6.44\% in F1 score. Moreover, NetMamba+ demonstrates excellent efficiency, achieving 1.7x higher inference throughput than the best baseline while maintaining comparably low memory usage. Furthermore, NetMamba+ exhibits superior few-shot learning abilities, achieving better classification performance with fewer labeled data. Additionally, we implement an online traffic classification system that demonstrates robust real-world performance with a throughput of 261.87 Mb/s. As the first framework to adapt Mamba architecture for network traffic classification, NetMamba+ opens new possibilities for efficient and accurate traffic analysis in complex network environments.
AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers
Mar 25, 2025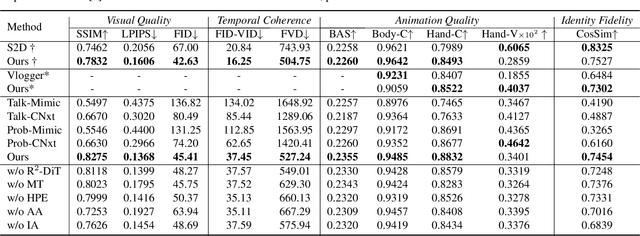
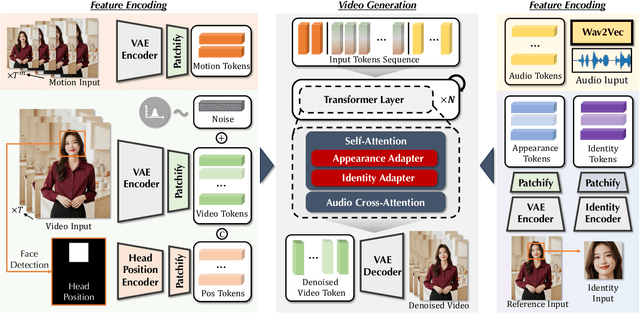
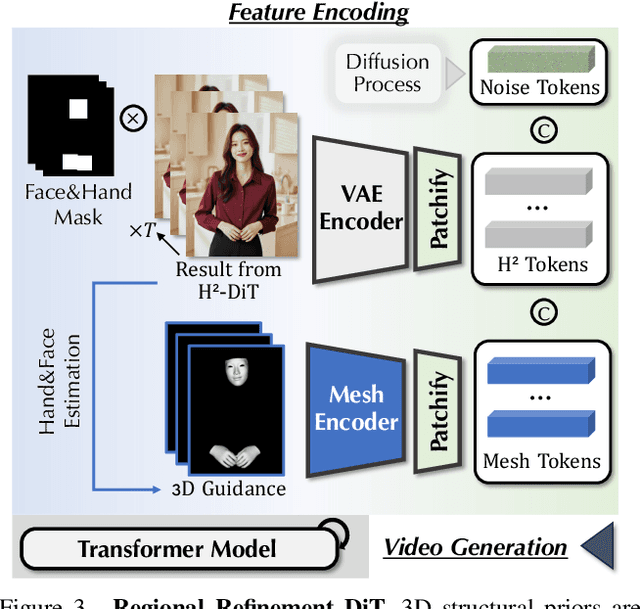

Despite the recent progress of audio-driven video generation, existing methods mostly focus on driving facial movements, leading to non-coherent head and body dynamics. Moving forward, it is desirable yet challenging to generate holistic human videos with both accurate lip-sync and delicate co-speech gestures w.r.t. given audio. In this work, we propose AudCast, a generalized audio-driven human video generation framework adopting a cascade Diffusion-Transformers (DiTs) paradigm, which synthesizes holistic human videos based on a reference image and a given audio. 1) Firstly, an audio-conditioned Holistic Human DiT architecture is proposed to directly drive the movements of any human body with vivid gesture dynamics. 2) Then to enhance hand and face details that are well-knownly difficult to handle, a Regional Refinement DiT leverages regional 3D fitting as the bridge to reform the signals, producing the final results. Extensive experiments demonstrate that our framework generates high-fidelity audio-driven holistic human videos with temporal coherence and fine facial and hand details. Resources can be found at https://guanjz20.github.io/projects/AudCast.
TALK-Act: Enhance Textural-Awareness for 2D Speaking Avatar Reenactment with Diffusion Model
Oct 14, 2024

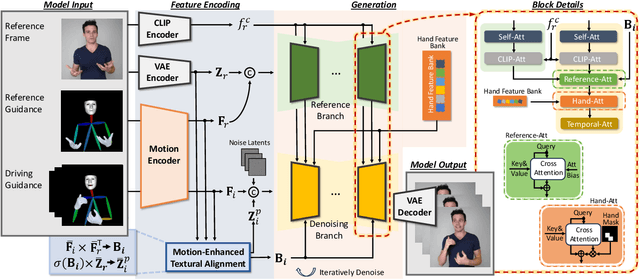

Recently, 2D speaking avatars have increasingly participated in everyday scenarios due to the fast development of facial animation techniques. However, most existing works neglect the explicit control of human bodies. In this paper, we propose to drive not only the faces but also the torso and gesture movements of a speaking figure. Inspired by recent advances in diffusion models, we propose the Motion-Enhanced Textural-Aware ModeLing for SpeaKing Avatar Reenactment (TALK-Act) framework, which enables high-fidelity avatar reenactment from only short footage of monocular video. Our key idea is to enhance the textural awareness with explicit motion guidance in diffusion modeling. Specifically, we carefully construct 2D and 3D structural information as intermediate guidance. While recent diffusion models adopt a side network for control information injection, they fail to synthesize temporally stable results even with person-specific fine-tuning. We propose a Motion-Enhanced Textural Alignment module to enhance the bond between driving and target signals. Moreover, we build a Memory-based Hand-Recovering module to help with the difficulties in hand-shape preserving. After pre-training, our model can achieve high-fidelity 2D avatar reenactment with only 30 seconds of person-specific data. Extensive experiments demonstrate the effectiveness and superiority of our proposed framework. Resources can be found at https://guanjz20.github.io/projects/TALK-Act.
ReSyncer: Rewiring Style-based Generator for Unified Audio-Visually Synced Facial Performer
Aug 06, 2024



Lip-syncing videos with given audio is the foundation for various applications including the creation of virtual presenters or performers. While recent studies explore high-fidelity lip-sync with different techniques, their task-orientated models either require long-term videos for clip-specific training or retain visible artifacts. In this paper, we propose a unified and effective framework ReSyncer, that synchronizes generalized audio-visual facial information. The key design is revisiting and rewiring the Style-based generator to efficiently adopt 3D facial dynamics predicted by a principled style-injected Transformer. By simply re-configuring the information insertion mechanisms within the noise and style space, our framework fuses motion and appearance with unified training. Extensive experiments demonstrate that ReSyncer not only produces high-fidelity lip-synced videos according to audio, but also supports multiple appealing properties that are suitable for creating virtual presenters and performers, including fast personalized fine-tuning, video-driven lip-syncing, the transfer of speaking styles, and even face swapping. Resources can be found at https://guanjz20.github.io/projects/ReSyncer.
NetMamba: Efficient Network Traffic Classification via Pre-training Unidirectional Mamba
May 19, 2024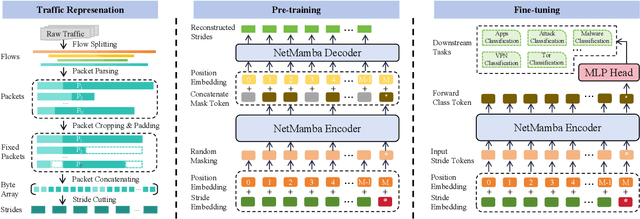
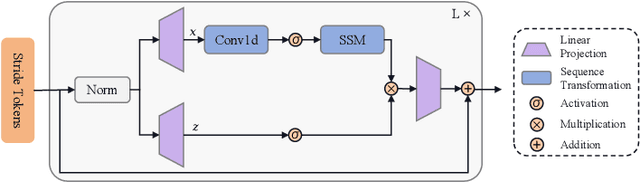
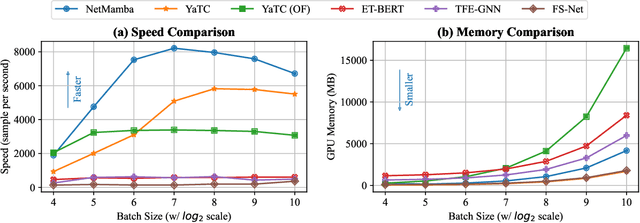
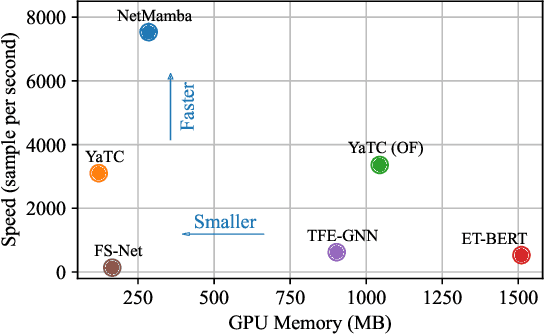
Network traffic classification is a crucial research area aiming to enhance service quality, streamline network management, and bolster cybersecurity. To address the growing complexity of transmission encryption techniques, various machine learning and deep learning methods have been proposed. However, existing approaches encounter two main challenges. Firstly, they struggle with model inefficiency due to the quadratic complexity of the widely used Transformer architecture. Secondly, they suffer from unreliable traffic representation because of discarding important byte information while retaining unwanted biases. To address these challenges, we propose NetMamba, an efficient linear-time state space model equipped with a comprehensive traffic representation scheme. We replace the Transformer with our specially selected and improved Mamba architecture for the networking field to address efficiency issues. In addition, we design a scheme for traffic representation, which is used to extract valid information from massive traffic while removing biased information. Evaluation experiments on six public datasets encompassing three main classification tasks showcase NetMamba's superior classification performance compared to state-of-the-art baselines. It achieves up to 4.83\% higher accuracy and 4.64\% higher f1 score on encrypted traffic classification tasks. Additionally, NetMamba demonstrates excellent efficiency, improving inference speed by 2.24 times while maintaining comparably low memory usage. Furthermore, NetMamba exhibits superior few-shot learning abilities, achieving better classification performance with fewer labeled data. To the best of our knowledge, NetMamba is the first model to tailor the Mamba architecture for networking.
VideoDistill: Language-aware Vision Distillation for Video Question Answering
Apr 01, 2024
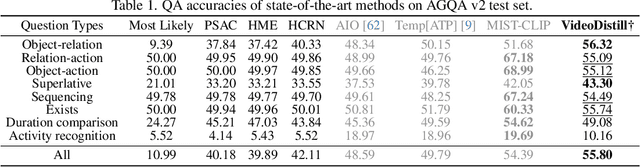
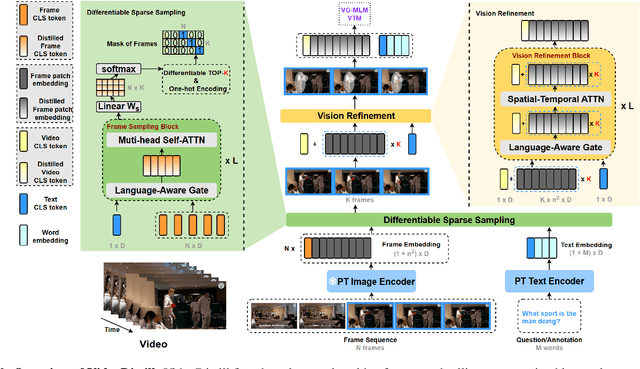
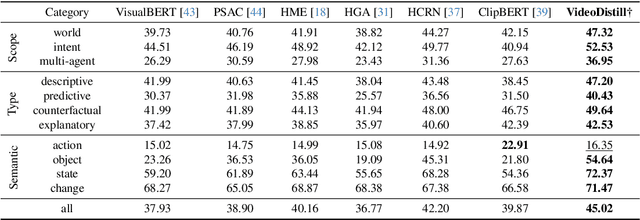
Significant advancements in video question answering (VideoQA) have been made thanks to thriving large image-language pretraining frameworks. Although these image-language models can efficiently represent both video and language branches, they typically employ a goal-free vision perception process and do not interact vision with language well during the answer generation, thus omitting crucial visual cues. In this paper, we are inspired by the human recognition and learning pattern and propose VideoDistill, a framework with language-aware (i.e., goal-driven) behavior in both vision perception and answer generation process. VideoDistill generates answers only from question-related visual embeddings and follows a thinking-observing-answering approach that closely resembles human behavior, distinguishing it from previous research. Specifically, we develop a language-aware gating mechanism to replace the standard cross-attention, avoiding language's direct fusion into visual representations. We incorporate this mechanism into two key components of the entire framework. The first component is a differentiable sparse sampling module, which selects frames containing the necessary dynamics and semantics relevant to the questions. The second component is a vision refinement module that merges existing spatial-temporal attention layers to ensure the extraction of multi-grained visual semantics associated with the questions. We conduct experimental evaluations on various challenging video question-answering benchmarks, and VideoDistill achieves state-of-the-art performance in both general and long-form VideoQA datasets. In Addition, we verify that VideoDistill can effectively alleviate the utilization of language shortcut solutions in the EgoTaskQA dataset.
Teeth-SEG: An Efficient Instance Segmentation Framework for Orthodontic Treatment based on Anthropic Prior Knowledge
Apr 01, 2024



Teeth localization, segmentation, and labeling in 2D images have great potential in modern dentistry to enhance dental diagnostics, treatment planning, and population-based studies on oral health. However, general instance segmentation frameworks are incompetent due to 1) the subtle differences between some teeth' shapes (e.g., maxillary first premolar and second premolar), 2) the teeth's position and shape variation across subjects, and 3) the presence of abnormalities in the dentition (e.g., caries and edentulism). To address these problems, we propose a ViT-based framework named TeethSEG, which consists of stacked Multi-Scale Aggregation (MSA) blocks and an Anthropic Prior Knowledge (APK) layer. Specifically, to compose the two modules, we design 1) a unique permutation-based upscaler to ensure high efficiency while establishing clear segmentation boundaries with 2) multi-head self/cross-gating layers to emphasize particular semantics meanwhile maintaining the divergence between token embeddings. Besides, we collect 3) the first open-sourced intraoral image dataset IO150K, which comprises over 150k intraoral photos, and all photos are annotated by orthodontists using a human-machine hybrid algorithm. Experiments on IO150K demonstrate that our TeethSEG outperforms the state-of-the-art segmentation models on dental image segmentation.
LLaMA-Excitor: General Instruction Tuning via Indirect Feature Interaction
Apr 01, 2024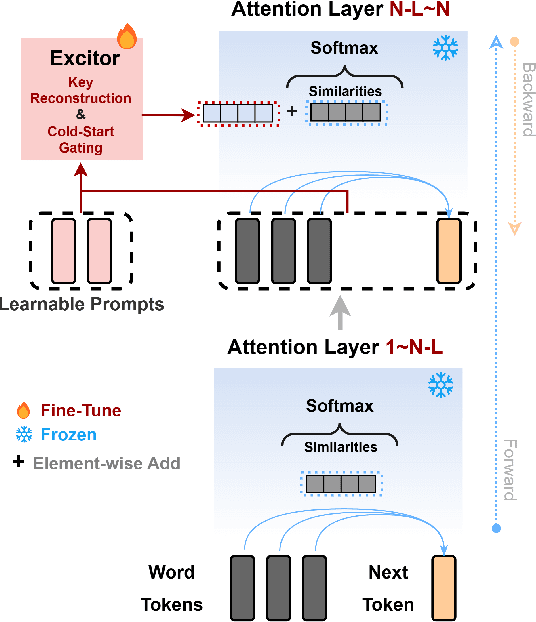

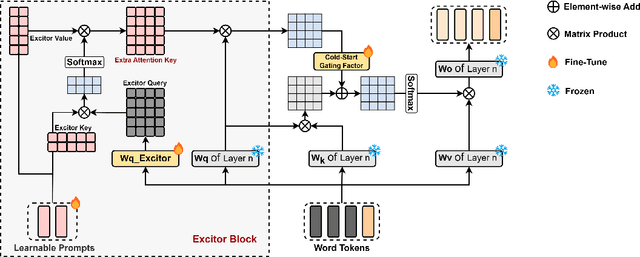

Existing methods to fine-tune LLMs, like Adapter, Prefix-tuning, and LoRA, which introduce extra modules or additional input sequences to inject new skills or knowledge, may compromise the innate abilities of LLMs. In this paper, we propose LLaMA-Excitor, a lightweight method that stimulates the LLMs' potential to better follow instructions by gradually paying more attention to worthwhile information. Specifically, the LLaMA-Excitor does not directly change the intermediate hidden state during the self-attention calculation of the transformer structure. We designed the Excitor block as a bypass module for the similarity score computation in LLMs' self-attention to reconstruct keys and change the importance of values by learnable prompts. LLaMA-Excitor ensures a self-adaptive allocation of additional attention to input instructions, thus effectively preserving LLMs' pre-trained knowledge when fine-tuning LLMs on low-quality instruction-following datasets. Furthermore, we unify the modeling of multi-modal tuning and language-only tuning, extending LLaMA-Excitor to a powerful visual instruction follower without the need for complex multi-modal alignment. Our proposed approach is evaluated in language-only and multi-modal tuning experimental scenarios. Notably, LLaMA-Excitor is the only method that maintains basic capabilities while achieving a significant improvement (+6%) on the MMLU benchmark. In the visual instruction tuning, we achieve a new state-of-the-art image captioning performance of 157.5 CIDEr on MSCOCO, and a comparable performance (88.39%) on ScienceQA to cutting-edge models with more parameters and extensive vision-language pertaining.
Building an Invisible Shield for Your Portrait against Deepfakes
May 22, 2023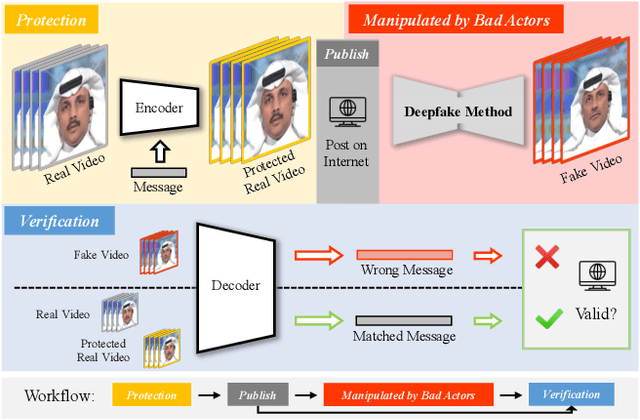



The issue of detecting deepfakes has garnered significant attention in the research community, with the goal of identifying facial manipulations for abuse prevention. Although recent studies have focused on developing generalized models that can detect various types of deepfakes, their performance is not always be reliable and stable, which poses limitations in real-world applications. Instead of learning a forgery detector, in this paper, we propose a novel framework - Integrity Encryptor, aiming to protect portraits in a proactive strategy. Our methodology involves covertly encoding messages that are closely associated with key facial attributes into authentic images prior to their public release. Unlike authentic images, where the hidden messages can be extracted with precision, manipulating the facial attributes through deepfake techniques can disrupt the decoding process. Consequently, the modified facial attributes serve as a mean of detecting manipulated images through a comparison of the decoded messages. Our encryption approach is characterized by its brevity and efficiency, and the resulting method exhibits a good robustness against typical image processing traces, such as image degradation and noise. When compared to baselines that struggle to detect deepfakes in a black-box setting, our method utilizing conditional encryption showcases superior performance when presented with a range of different types of forgeries. In experiments conducted on our protected data, our approach outperforms existing state-of-the-art methods by a significant margin.